BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg
收藏Hugging Face2025-11-02 更新2025-11-03 收录
下载链接:
https://huggingface.co/datasets/TAUR-dev/BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个包含问题和答案以及相关元数据的数据集,用于训练模型。数据集包含4000个训练示例,并提供了一些关于任务配置和模型响应评估的详细信息。
创建时间:
2025-10-30
原始信息汇总
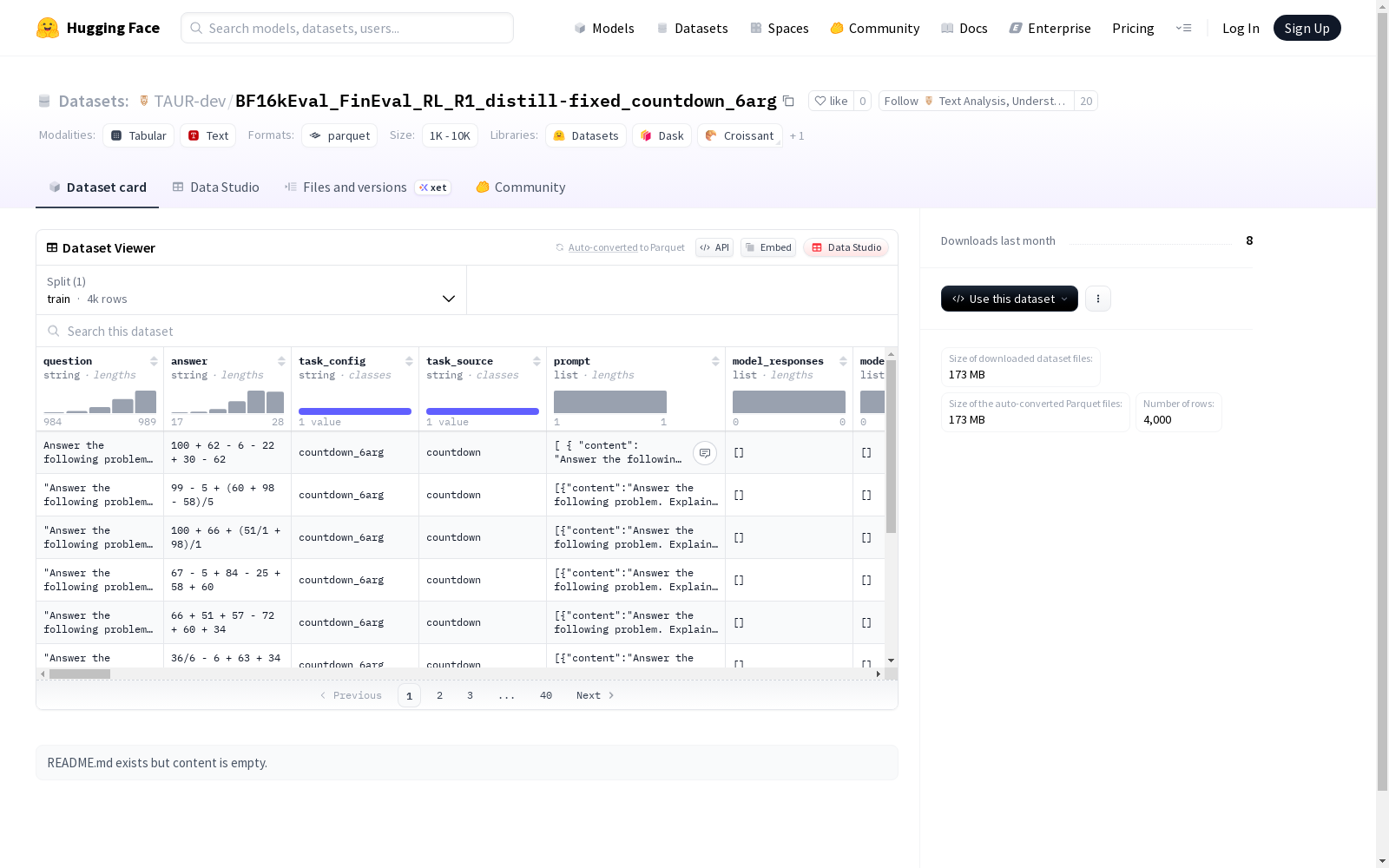
BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg 数据集概述
数据集基本信息
- 数据集名称: BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg
- 数据量: 4,000个样本
- 数据集大小: 554,023,319字节
- 下载大小: 172,608,418字节
- 数据格式: 结构化数据
数据结构特征
主要字段
- question: 问题文本(字符串类型)
- answer: 答案文本(字符串类型)
- task_config: 任务配置信息(字符串类型)
- task_source: 任务来源(字符串类型)
- prompt: 提示信息列表
- content: 内容(字符串类型)
- role: 角色(字符串类型)
模型响应相关字段
- model_responses: 模型响应列表
- model_responses__eval_is_correct: 模型响应正确性评估列表
- model_responses__best_of_n_atags: 最佳N个标签的模型响应列表
- model_responses__budget_forced: 预算强制模型响应列表
评估指标字段
-
model_responses__best_of_n_atags__metrics: 最佳N个标签评估指标
- flips_by: 翻转次数列表
- flips_total: 总翻转次数
- num_correct: 正确数量
- pass_at_n: N次通过率
- percent_correct: 正确百分比
- skill_count: 技能计数统计
- total_responses: 总响应数
-
model_responses__budget_forced__metrics: 预算强制评估指标
- 包含与最佳N个标签评估相同的指标结构
其他重要字段
- original_split: 原始分割信息
- metadata: 元数据信息
- eval_date: 评估日期
- question_idx: 问题索引
- response_idx: 响应索引
- budget_forced_continuations: 预算强制延续信息
数据分割
- 训练集: 4,000个样本,554,023,319字节
- 数据文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在人工智能评估领域,BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg数据集通过多阶段蒸馏流程构建而成,其核心机制整合了预算约束强化学习与迭代优化策略。该数据集以结构化任务配置为基础,采用多轮对话模拟框架生成训练样本,每个样本包含问题、标准答案及带有元数据的提示序列。构建过程中特别设计了预算强制机制,通过令牌计数与轮次控制实现资源受限条件下的模型响应优化,同时集成内部评估体系对答案正确性进行多层次验证。
特点
该数据集展现出多维评估体系的典型特征,其数据结构涵盖原始问题、模型响应链及精细化评估指标。特征体系包含动态生成的对话提示序列、预算约束下的响应连续性分析以及基于技能分类的性能度量。通过嵌套式评估字段设计,能够同时追踪模型在反思推理、投票决策等九类核心能力上的表现。特别值得注意的是,数据集通过元数据字段完整保留了任务来源与评估过程的时间轨迹,为可复现研究提供了坚实基础。
使用方法
研究人员可通过加载标准数据分割接口直接访问该数据集的4000个训练样本,利用内置的评估指标体系进行模型能力诊断。典型应用流程包括解析任务配置元数据、重构多轮对话场景,并基于预算强制响应字段进行约束条件下的推理分析。使用时应重点关注模型响应评估字段与技能计数结构的联动分析,通过正确率百分比与通过率指标量化模型在复杂决策任务中的表现。数据集的层次化评估体系支持对模型内部推理过程的细粒度考察,适用于强化学习策略验证与多步骤推理能力评估场景。
背景与挑战
背景概述
在人工智能领域,大规模语言模型评估数据集的发展推动了模型性能的精细化度量。BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg数据集作为近期构建的评估资源,专注于强化学习与知识蒸馏框架下的模型响应分析。该数据集通过结构化的问题-答案对及多维度评估指标,旨在解决语言模型在复杂推理任务中的准确性与稳定性问题,其设计体现了对模型内部决策过程的可解释性探索,为优化模型训练策略提供了实证基础。
当前挑战
该数据集致力于应对语言模型在动态推理任务中的鲁棒性评估挑战,例如处理多轮对话中的逻辑一致性和答案修正能力。构建过程中,数据标注的复杂性成为主要障碍,需确保数千条样本的评估标签(如正确性判断和答案提取)的精确对齐;同时,多模态元数据(如令牌使用统计和技能分类)的集成要求跨领域协作,以维持数据一致性与可复现性。
常用场景
经典使用场景
在自然语言处理领域,BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg数据集作为评估框架,专门用于测试语言模型在复杂推理任务中的表现。其核心应用场景涉及对模型多轮对话能力、答案修正机制以及预算约束下响应生成的系统性评测,通过结构化的问题-答案对和任务配置,为模型迭代优化提供标准化基准。
衍生相关工作
基于该数据集的结构化评估范式,衍生出多项经典研究工作。例如融合反射机制的序列到序列模型改进、基于技能计数的多策略集成方法,以及针对预算约束的渐进式生成算法。这些成果在ACL、EMNLP等顶级会议中形成系列论文,推动了评估驱动型模型优化范式的确立。
数据集最近研究
最新研究方向
在语言模型评估领域,BF16kEval_FinEval_RL_R1_distill-fixed_countdown_6arg数据集正推动预算约束下推理能力的前沿探索。该数据集通过集成多轮对话结构、答案修正机制及资源分配策略,为研究受限计算环境中的模型决策优化提供了基准。当前热点聚焦于强化学习与知识蒸馏的协同应用,旨在提升模型在复杂金融场景中的鲁棒性,同时探索评估指标与真实任务性能的关联性,对推动高效可信人工智能系统的发展具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


