mad-cars
收藏魔搭社区2026-01-06 更新2025-06-28 收录
下载链接:
https://modelscope.cn/datasets/yandex/mad-cars
下载链接
链接失效反馈官方服务:
资源简介:
# MAD-Cars: Multi-view Auto Dataset 🚗
## Dataset Description
**MAD-Cars** is a large-scale collection of 360° car videos.
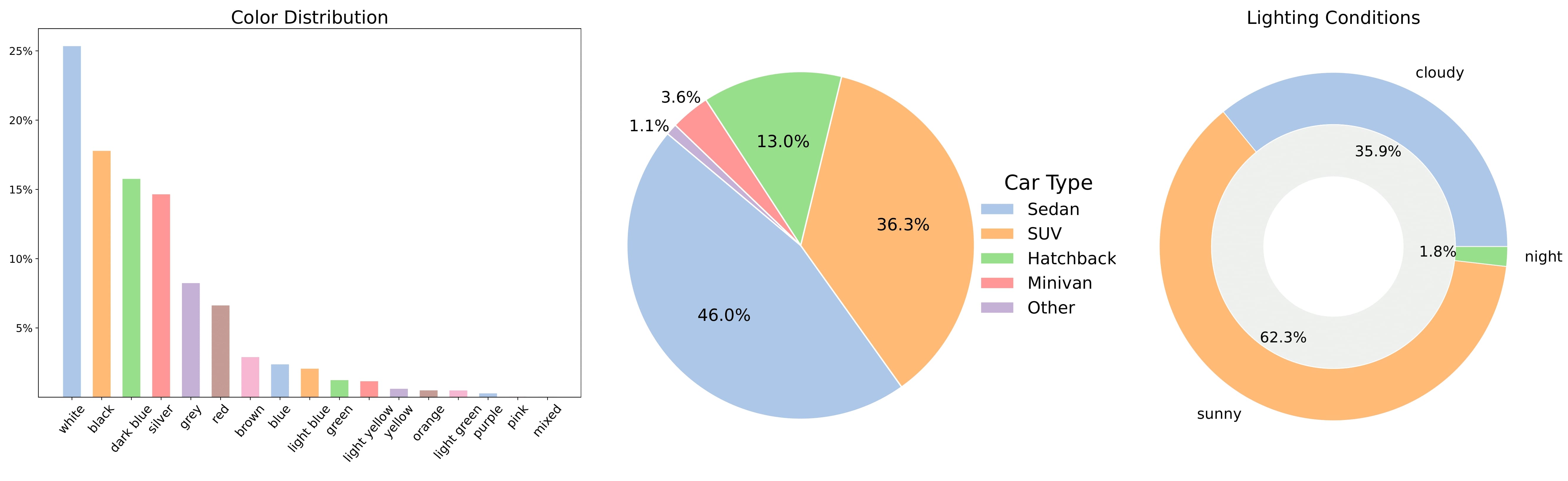
It comprises ~70,000 car instances with diverse brands, car types, colors, and lighting conditions. Each instance contains an average of ~85 frames, with most car instances available at a resolution of 1920x1080. The dataset statistics are presented in the figure below. The data is carefully curated by filtering the frames and entire car instances that can negatively affect 3D reconstruction.
This dataset is introduced in the research paper: \
**"[MADrive: Memory-Augmented Driving Scene Modeling](https://huggingface.co/papers/2506.21520)"**
Project page: https://yandex-research.github.io/madrive/
### Data Fields
Each instance in the dataset contains:
* `car_id`: Unique identifier for a single car instance.
* `view_id`: Identifier for a specific view of the car.
* `url`: URL to download the corresponding single car view.
* `color`: RGB color value representing the car's color.
* `brand`: Manufacturer or brand of the car.
* `model`: Specific model name or designation of the car.
Note that `view_id` is not aligned with a particular camera position or angle.
### Data Splits
The dataset contains a single split:
* `train`: 5,884,329 samples.
## Usage
The MAD dataset is designed for novel-view synthesis of cars. [MADrive](https://huggingface.co/papers/2506.21520) exploits this data for the retrieval-augmented driving scene reconstruction.
### Getting Started
**Loading the dataset:**
```python
from datasets import load_dataset
dataset = load_dataset("yandex/mad-cars", split="train")
```
**Exracting the first view:**
```python
from PIL import Image
import requests
from io import BytesIO
response = requests.get(dataset[0]['url'])
image = Image.open(BytesIO(response.content))
```
**Grouping by `car_id`:**
```python
car_id_to_urls = dataset.to_pandas().groupby("car_id")['url'].agg(list)
```
## Citation
```bibtex
@artcile{karpikova2025madrivememoryaugmenteddrivingscene,
title={MADrive: Memory-Augmented Driving Scene Modeling},
author={Polina Karpikova and Daniil Selikhanovych and Kirill Struminsky and Ruslan Musaev and Maria Golitsyna and Dmitry Baranchuk},
year={2025},
eprint={2506.21520},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.21520},
}
```
# MAD-Cars:多视角汽车数据集 🚗
## 数据集说明
**MAD-Cars** 是一个大规模的360°汽车视频合集。该数据集涵盖约70,000个汽车实例,包含多样化的品牌、车型、车身颜色与光照条件。每个汽车实例平均包含约85帧图像,绝大多数实例的分辨率为1920×1080。数据集统计信息见下图。本数据集经过严格筛选,剔除了会对三维重建产生负面影响的帧与完整汽车实例。
本数据集的相关研究论文为:
**《MADrive:记忆增强驾驶场景建模》**,论文链接:https://huggingface.co/papers/2506.21520
项目主页:https://yandex-research.github.io/madrive/

### 数据字段
数据集中的每个实例包含以下内容:
* `car_id`:单个汽车实例的唯一标识符。
* `view_id`:汽车特定视角的标识符。
* `url`:对应单视角汽车图像的下载链接。
* `color`:表征汽车车身颜色的RGB色彩值。
* `brand`:汽车的制造商或品牌。
* `model`:汽车的具体型号名称或编号。
注意:`view_id` 并未与特定的相机位置或拍摄角度绑定。
### 数据划分
本数据集仅包含单一划分:
* `train`:共计5,884,329个样本。
## 使用场景
本数据集旨在支持汽车的新颖视角合成任务。研究工作[MADrive](https://huggingface.co/papers/2506.21520)将该数据集用于检索增强型驾驶场景重建任务。
### 快速上手
**加载数据集:**
python
from datasets import load_dataset
dataset = load_dataset("yandex/mad-cars", split="train")
**提取首个视角图像:**
python
from PIL import Image
import requests
from io import BytesIO
response = requests.get(dataset[0]['url'])
image = Image.open(BytesIO(response.content))
**按`car_id`分组:**
python
car_id_to_urls = dataset.to_pandas().groupby("car_id")['url'].agg(list)
## 引用格式
bibtex
@article{karpikova2025madrivememoryaugmenteddrivingscene,
title={MADrive: Memory-Augmented Driving Scene Modeling},
author={Polina Karpikova and Daniil Selikhanovych and Kirill Struminsky and Ruslan Musaev and Maria Golitsyna and Dmitry Baranchuk},
year={2025},
eprint={2506.21520},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.21520},
}
提供机构:
maas创建时间:
2025-06-23
搜集汇总
数据集介绍
背景与挑战
背景概述
MAD-Cars是一个包含约70,000个汽车实例的大规模多视角汽车视频数据集,每个实例平均有约85帧,分辨率多为1920x1080。该数据集设计用于汽车的新视角合成和驾驶场景的重建,支持通过`car_id`和`view_id`进行数据组织和使用Apache License 2.0许可。
以上内容由遇见数据集搜集并总结生成


