ATHAR
收藏Hugging Face2024-07-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/mohamed-khalil/ATHAR
下载链接
链接失效反馈官方服务:
资源简介:
ATHAR数据集是一个全面的古典阿拉伯语文本英译集合,包含约66,000行翻译文本,包括原始的古典阿拉伯语文本及其英译。该数据集分为测试数据和训练数据两个主要子集。每条记录包含一个古典阿拉伯语文本字段和一个对应的英译字段。该数据集适用于阿拉伯语到英语的翻译任务。
创建时间:
2024-07-18
原始信息汇总
数据集概述
数据集信息
特征
- 名称: arabic
- 数据类型: string
- 名称: english
- 数据类型: string
分割
- 名称: train
- 字节数: 27878710
- 样本数: 65043
- 名称: test
- 字节数: 430500
- 样本数: 1000
大小
- 下载大小: 14722818
- 数据集大小: 28309210
配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: data/train-*
- 分割: test
- 路径: data/test-*
- 分割: train
- 数据文件:
任务类别
- translation
语言
- ar
- en
名称
- ATHAR
大小类别
- 10K<n<100K
数据集结构
字段
- 字段: Arabic(str)
- 描述: 古典阿拉伯语文本
- 字段: English(str)
- 描述: 古典阿拉伯语文本的英文翻译
数据集加载
代码示例
python from datasets import load_dataset
athar = load_dataset("mohamed-khalil/ATHAR")
样本示例
示例
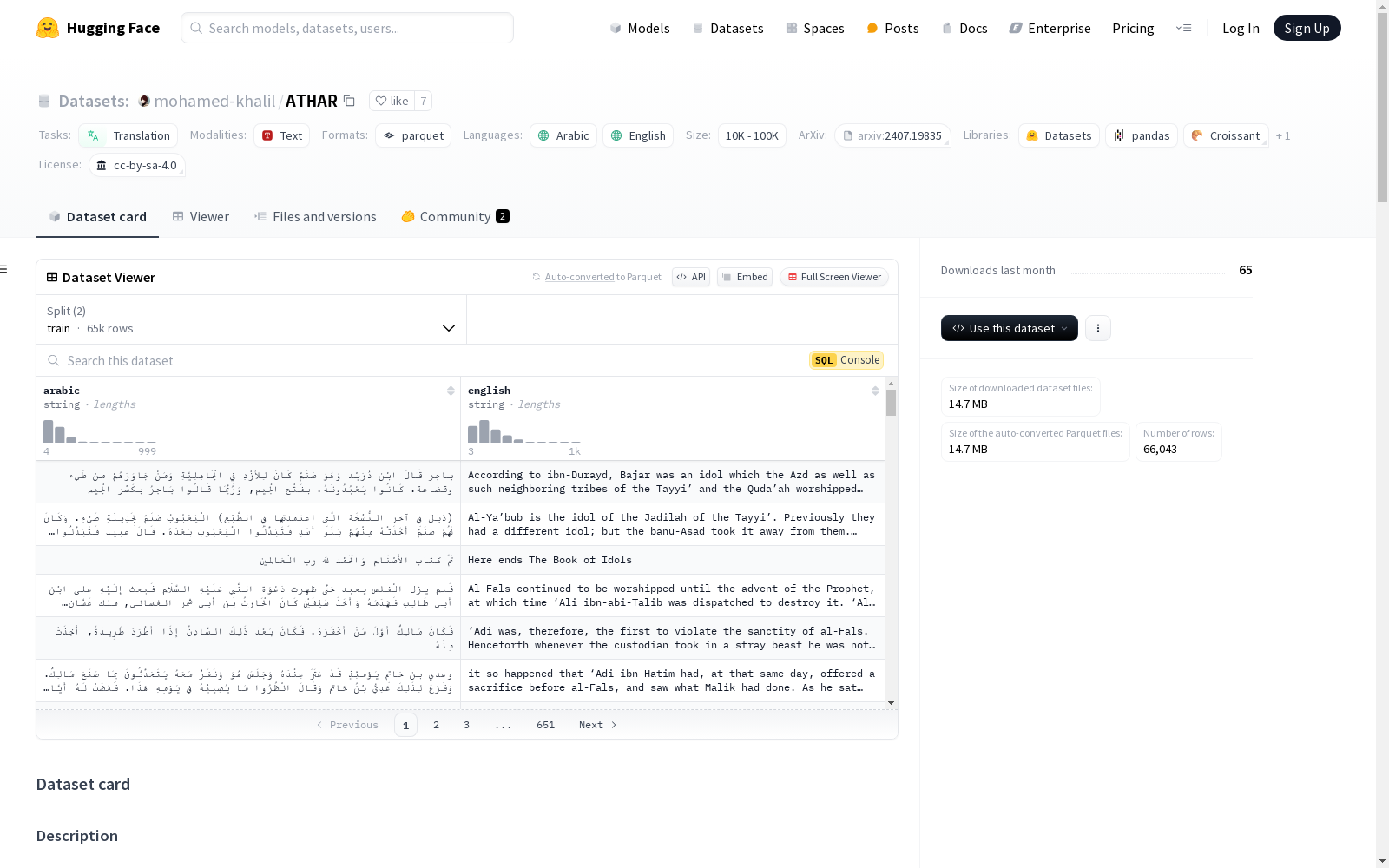
- Arabic: فَلم يزل الْفلس يعبد حَتَّى ظهرت دَعْوَة النَّبِي عَلَيْهِ السَّلَام فَبعث إِلَيْهِ على ابْن أَبِي طَالِبٍ فَهَدَمَهُ وَأَخَذَ سَيْفَيْنِ كَانَ الْحَارِثُ بن أبي شمرٍ الغساني, ملك غَسَّان قَلَّدَهُ إِيَّاهُمَا, يُقَالُ لَهُمَا مِخْذَمٌ وَرَسُوبٌ(وَهُمَا السَّيْفَانِ اللَّذَانِ ذَكَرَهُمَا عَلْقَمَةُ بْنُ عَبْدَةَ فِي شِعْرِهِ). فَقَدِمَ بِهِمَا عَلِيُّ بْنُ أَبِي طَالِبٍ عَلَى النَّبِيِّ صَلَّى اللَّهُ عَلَيْهِ وَسَلَّمَ فَتَقَلَّدَ أَحَدَهُمَا ثُمَّ دَفَعَهُ إِلَى عَلِيِّ بْنِ أَبِي طَالِبٍ, فَهُوَ سَيْفُهُ الَّذِي كَانَ يَتَقَلَّدُهُ
- English: Al-Fals continued to be worshipped until the advent of the Prophet, at which time ‘Ali ibn-abi-Talib was dispatched to destroy it. ‘Ali destroyed the idol and carried away therefrom two swords called Mikhdham and Rasub (the same two swords which ‘Alqamah ibn-’Abadah had mentioned in his poetry), which al-Harith ibn-abi-Shamir, king of Ghassan, had presented al-Fals. ‘Ali brought them to the Prophet who wore one of them and gave it back to him. It was the sword which ‘Ali was always wont to wear
搜集汇总
数据集介绍
构建方式
ATHAR数据集通过从Rasaif网站(rasaif.com)提取的66,000句古典阿拉伯文本构建而成,这些文本涵盖了伊斯兰和世界历史、哲学、科学、医学和文化等多个领域的经典著作。数据集的构建过程包括从原始文本中提取句子,并由专家团队进行高质量的英语翻译,确保翻译的准确性和文化背景的保留。数据集分为训练集和测试集,分别包含65,043条和1,000条句子,用于训练和评估翻译模型。
使用方法
ATHAR数据集可通过HuggingFace平台直接下载,用户可以使用`datasets`库加载数据集。加载后,数据集可以用于训练和评估古典阿拉伯语到英语的翻译模型。用户可以通过调用`load_dataset`函数轻松访问数据集,并利用其提供的训练集和测试集进行模型开发和性能评估。数据集的简洁结构和清晰的字段定义使得其在机器翻译任务中的应用更加便捷。
背景与挑战
背景概述
ATHAR数据集是一个专注于古典阿拉伯语到英语翻译的高质量、多样化数据集,由Mohammed Khalil和Mohammed Sabry于2024年创建。该数据集包含了约66,000条古典阿拉伯语文本及其对应的英语翻译,涵盖了伊斯兰历史、哲学、科学、医学和文化等多个领域的经典文献。ATHAR的构建旨在为机器翻译领域提供丰富的语料资源,特别是针对古典阿拉伯语这一复杂且历史悠久的语言。该数据集的发布填补了古典阿拉伯语翻译数据资源的空白,为相关领域的研究者提供了宝贵的工具,推动了跨语言文化交流与理解。
当前挑战
ATHAR数据集在构建和应用过程中面临多重挑战。首先,古典阿拉伯语具有复杂的语法结构和丰富的词汇多样性,其翻译任务对机器翻译模型提出了极高的要求,尤其是在保持语义准确性和文化背景的忠实性方面。其次,数据集的构建过程中,如何确保翻译的高质量与一致性是一个关键问题,尤其是在处理历史文献时,翻译者需要具备深厚的语言学和历史知识。此外,古典阿拉伯语的语料资源相对稀缺,数据收集与标注的过程耗时且复杂,如何平衡数据的多样性与质量也是构建过程中的一大挑战。这些挑战不仅影响了数据集的构建效率,也对后续的模型训练与评估提出了更高的要求。
常用场景
经典使用场景
ATHAR数据集在机器翻译领域具有广泛的应用,尤其是在古典阿拉伯语到英语的翻译任务中。该数据集包含了大量高质量的古典阿拉伯语文本及其对应的英语翻译,适用于训练和评估翻译模型。研究人员可以利用该数据集构建和优化神经机器翻译系统,特别是在处理复杂句法结构和丰富文化背景的文本时,ATHAR提供了宝贵的资源。
解决学术问题
ATHAR数据集解决了古典阿拉伯语翻译中的多个学术难题。首先,它填补了古典阿拉伯语与英语之间高质量平行语料库的空白,为翻译模型的训练提供了可靠的数据支持。其次,该数据集涵盖了多种文学体裁和历史时期的文本,有助于提升模型在处理不同风格和语境下的翻译能力。此外,ATHAR还为跨语言文化研究提供了重要的数据基础,促进了古典阿拉伯文学在全球范围内的传播与理解。
实际应用
在实际应用中,ATHAR数据集为多语言翻译工具的开发提供了重要支持。例如,基于该数据集训练的翻译模型可以用于学术研究、历史文献翻译以及跨文化交流等领域。此外,该数据集还可用于教育领域,帮助学生和研究者更好地理解古典阿拉伯语文本的内容和背景。通过提升翻译质量,ATHAR为全球用户提供了更便捷的古典阿拉伯语资源访问途径。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术的飞速发展,古典阿拉伯语到英语的翻译任务逐渐成为研究热点。ATHAR数据集作为这一领域的高质量资源,为研究者提供了丰富的古典阿拉伯语文本及其对应的英语翻译。该数据集不仅涵盖了伊斯兰历史、哲学、科学和医学等多个领域的经典文献,还为机器翻译模型的训练和评估提供了坚实的基础。当前的研究方向主要集中在如何利用深度学习技术提升翻译的准确性和流畅性,尤其是在处理古典阿拉伯语特有的语法结构和词汇时。此外,ATHAR数据集的出现也为跨文化研究提供了新的视角,推动了阿拉伯文化遗产的数字化传播与全球共享。
以上内容由遇见数据集搜集并总结生成


