nus-yam/vulrepair
收藏Hugging Face2023-11-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nus-yam/vulrepair
下载链接
链接失效反馈官方服务:
资源简介:
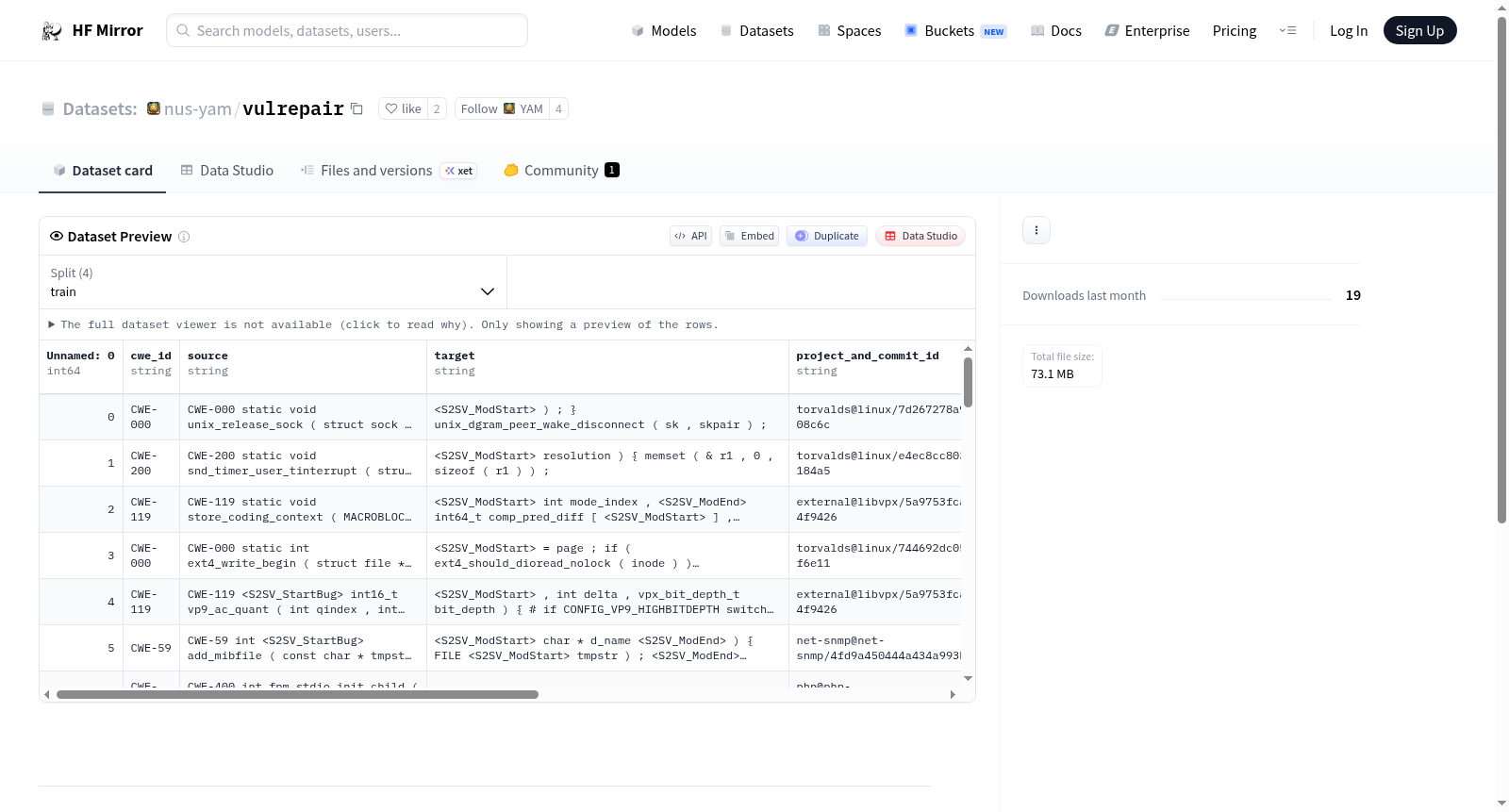
BigFixes是BigVul和CVE-Fixes的干净合并版本。数据集包含四个分割:train(去重的训练数据)、cleantest(与训练集完全不相交的去重测试数据)、test(与训练数据有显著交集的去重训练数据)和output(VulRepair在test分割数据上的输出)。预处理步骤在preprocessing.ipynb中提供。
BigFixes is a clean merged version of BigVul and CVE-Fixes. The dataset contains four splits: train (deduplicated training data), cleantest (deduplicated test data completely disjoint from the training set), test (deduplicated training data that has a significant overlap with the training data), and output (the outputs of VulRepair on the test split). The preprocessing steps are provided in preprocessing.ipynb.
提供机构:
nus-yam
原始信息汇总
BigFixes 数据集概述
数据集描述
BigFixes 是一个 BigVul 和 CVE-Fixes 的清洁联合数据集。
配置信息
- 默认配置 (
default)- 数据文件
train: 去重后的训练数据,路径为train.csv。cleantest: 去重后的测试数据,与训练集完全不相交,路径为clean_test.csv。test: 去重后的训练数据,与训练数据有显著交集,路径为test.csv。output: VulRepair 在test数据上的输出结果,路径为output.csv。
- 数据文件
预处理
预处理代码可在 preprocessing.ipynb 中找到。
搜集汇总
数据集介绍
构建方式
在软件安全领域,漏洞修复数据集对于提升自动化代码修复能力至关重要。VulRepair数据集通过整合BigVul与CVE-Fixes两大权威漏洞数据库,构建了一个经过清洗与去重处理的统一数据集。其构建过程采用系统化预处理流程,确保数据质量与一致性,具体步骤记录于预处理文档中。该数据集划分为训练集、清洁测试集、测试集及模型输出集,其中清洁测试集与训练集完全独立,避免了数据泄露问题,而测试集则保留了与训练集的部分重叠以反映实际研究场景。
特点
该数据集的核心特点在于其高度清洁与结构化设计。通过严格去重处理,消除了原始数据中的冗余条目,提升了数据集的纯净度。数据划分科学合理,清洁测试集与训练集的完全分离确保了模型评估的客观性,而保留重叠的测试集则为研究提供了更贴近真实应用的对比基准。此外,数据集额外提供了VulRepair模型在测试集上的输出结果,为后续研究提供了直接的参考与比较基础,增强了数据集的实用价值与研究深度。
使用方法
使用该数据集时,研究人员可依据不同需求灵活选择数据划分。训练集适用于模型训练与参数优化,清洁测试集可用于评估模型的泛化能力与鲁棒性。测试集则允许在接近实际应用的条件下验证模型性能。模型输出集可作为基准结果,用于对比分析新方法的有效性。数据集以CSV格式提供,便于直接加载与处理,预处理代码的开放也支持用户根据特定研究目标进行自定义调整,从而推动软件漏洞自动修复领域的创新探索。
背景与挑战
背景概述
在软件安全领域,漏洞修复是保障系统稳健性的核心环节。nus-yam/vulrepair数据集由新加坡国立大学的研究团队于近年构建,其整合了BigVul与CVE-Fixes两大开源漏洞数据库,旨在为自动化漏洞修复技术提供高质量的训练与评估基准。该数据集聚焦于代码级别的漏洞定位与补丁生成,推动了智能软件工程与安全分析方向的交叉研究,为学术界和工业界提供了关键的数据支撑。
当前挑战
该数据集致力于应对自动化漏洞修复中的双重挑战:其一,在领域问题层面,如何准确识别代码中的安全缺陷并生成语义正确、结构合规的修复补丁,涉及自然语言与编程语言的复杂映射;其二,在构建过程中,需处理原始数据的噪声与冗余,实现训练集与测试集的严格去重与分离,同时确保数据覆盖的多样性与代表性,以提升模型的泛化能力与可靠性。
常用场景
经典使用场景
在软件安全与漏洞修复领域,nus-yam/vulrepair数据集作为BigVul与CVE-Fixes的清洁联合版本,为自动化漏洞修复研究提供了关键支撑。该数据集通过去重和划分训练、测试子集,经典地应用于训练和评估基于深度学习的代码生成模型,旨在自动生成修复漏洞的补丁代码。研究者利用其结构化的漏洞-修复对数据,探索模型在理解漏洞上下文并输出正确修复方案方面的能力,推动了智能代码修复技术的发展。
实际应用
在实际应用层面,nus-yam/vulrepair数据集为开发安全工具和集成开发环境插件提供了数据基础。基于该数据集训练的模型可被部署于持续集成/持续部署流水线中,自动扫描代码库并建议漏洞修复,辅助开发人员快速响应安全威胁。此外,它还能用于构建代码审计系统,增强企业级软件的质量保障能力,切实降低因漏洞导致的安全风险与维护成本。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,VulRepair项目直接利用该数据集评估其修复生成模型的性能,推动了基于预训练模型的代码修复方法发展。同时,该数据集作为基准被广泛引用于后续研究,如结合图神经网络或强化学习改进修复精度的工作,进一步丰富了自动化软件修复领域的学术成果与技术生态。
以上内容由遇见数据集搜集并总结生成


