AylinNaebzadeh/english_dialects_combined
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/AylinNaebzadeh/english_dialects_combined
下载链接
链接失效反馈官方服务:
资源简介:
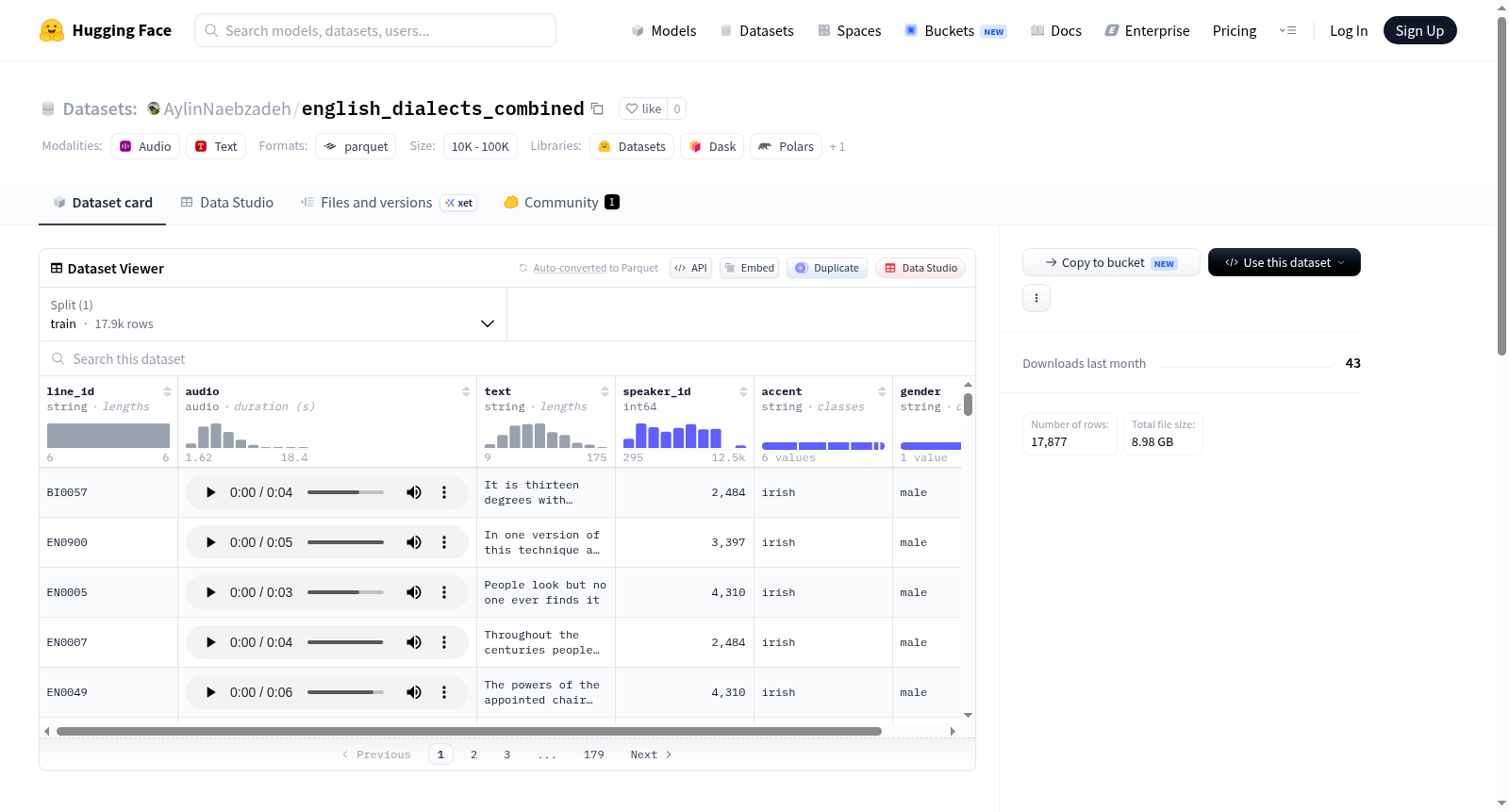
该数据集是🤗 ylacombe/english_dialects的合并版本,发布于LREC 2020。其目的是为不同任务的音频模型训练准备数据。除了合并11个数据集外,还为每条记录添加了性别和口音作为元数据。数据集包含音频、文本、说话者ID、口音和性别等特征,主要用于语音技术和语言分析。数据集包含超过31小时的录音,来自120名自认为是英格兰南部、中部、北部、威尔士、苏格兰和爱尔兰英语变体的母语使用者。录音脚本专门为口音引发而设计,涵盖了多种语音现象,并提供了高音素覆盖率。
This dataset is the combined version of 🤗 ylacombe/english_dialects published at LREC 2020. The goal is to prepare the dataset for audio models training on different tasks. In addition to merging 11 datasets together, gender and accent were added for each record as metadata. The dataset includes features such as audio, text, speaker ID, accent, and gender, and is primarily used for speech technologies and linguistic analysis. The resulting corpora include over 31 hours of recordings from 120 volunteers who self-identify as native speakers of Southern England, Midlands, Northern England, Welsh, Scottish and Irish varieties of English. The recording scripts were curated specifically for accent elicitation, covering a variety of phonological phenomena and providing a high phoneme coverage.
提供机构:
AylinNaebzadeh
搜集汇总
数据集介绍
构建方式
该数据集融合了原本发布于LREC 2020的ylacombe/english_dialects数据集中的11个子集,旨在为音频模型训练提供统一的多任务数据基础。在此基础上,每一条记录被补充了性别与口音标签,形成了结构化的元数据体系,使得数据集具备跨地域与跨性别语音分析的能力。原始录音脚本特别设计用于口音诱出,覆盖了丰富的音韵现象和高音素覆盖率,包括全球地名、主要航空公司及常见人名在不同口音下的发音。
使用方法
数据集以HuggingFace Datasets库加载,提供默认配置下的训练集分割,内含17877条样本。用户可通过指定data_files路径读取流式音频数据,并结合accent与gender字段进行条件过滤。由于音频字段采用标准音频编码格式,可直接利用transformer类模型进行预处理与微调。建议研究人员在使用时参考原始论文中的音韵覆盖设计,以充分发挥数据在跨口音语音分析中的价值。
背景与挑战
背景概述
该数据集由Demirsahin等研究人员于2020年在LREC会议上发布,旨在系统性地采集不列颠群岛多种英语口音的语音数据。其核心研究问题在于,通过构建一个包含性别、口音等元数据标注的高质量多说话人语料库,为语音技术研究与语言学分析提供标准化资源。该数据集整合了11个来源,涵盖英格兰南部、中部、北部、威尔士、苏格兰及爱尔兰等主要英语变体,总计逾31小时、120位志愿者的录音,显著推动了跨口音语音识别与音系学比较研究的进展。通过纳入与CSTR VCTK等现有资源的重叠语料,该数据集助力于个体与区域口音的横向对比,已成为英语方言研究领域的重要基准。
当前挑战
领域挑战集中于如何精准建模多口音语音在音系、韵律及词汇层面的显著变异,以提升语音系统对非标准英语变体的鲁棒性。数据集构建中面临双重难题:其一,需确保录制脚本兼具语言覆盖力与口音诱发效能——脚本须涵盖全球地名、航空公司等引发跨口音音位差异的词汇,并兼顾本地语词以捕获地域特色;其二,在整合11个异构数据源时,需统一标注格式并精准补全缺失的性别与口音元数据,同时维持音频质量一致性,这对自动标注校验与跨数据集对齐技术提出了严苛要求。
常用场景
经典使用场景
在语音科学与技术领域,english_dialects_combined数据集最经典的用途是作为多口音语音识别与语种辨识的基础训练与评估资源。该数据集汇聚了来自英国群岛六种主要英语口音的高质量语音数据,包括录音文本、说话人身份及性别等元信息,为构建跨口音的声学模型提供了标准化、规模化的实验平台。研究者通过该数据集可深入探究不同口音在音位、韵律与声学特征上的异同,并训练出能够适应多种地域变体的鲁棒语音系统,从而推动多口音场景下语音技术的普适性发展。
解决学术问题
该数据集有效解决了语音研究中长期存在的口音多样性与数据稀缺之间的矛盾。在此之前,由于缺乏覆盖广泛英国口音且标注详尽的公开语料库,研究者对于口音间的声学差异及发音变异机制的理解长期受限。english_dialects_combined通过整合十一个子数据集并统一标注口音与性别字段,为精细化分析口音对语音识别性能的影响提供了坚实基础。它还促进了说话人自适应、方言辨识及社会语音学等方向的量化研究,其丰富的语料与元数据助力学界构建更具包容性的语音模型,极大地推进了语音技术在复杂多口音环境中的适应能力与公平性。
实际应用
在实际应用层面,该数据集为开发面向英国地区用户的多口音语音助手、智能客服系统与语音导航工具提供了核心支撑。例如,可基于此数据集训练声学模型,使得亚马逊Alexa或谷歌助手等产品能够更准确地理解来自苏格兰、威尔士或北英格兰等地区的用户指令。在教育领域,该数据集可用于开发英语口音教学软件,帮助学习者辨识并模仿不同地域的发音特征。此外,在司法语音鉴定与口音自动识别系统中,该数据集所涵盖的丰富口音样本极大提升了模型对真实世界中复杂语音变体的辨别能力,从而增强了相关系统的实用性与可靠性。
数据集最近研究
最新研究方向
当前,english_dialects_combined数据集在语音识别与多口音语音合成领域展现出前沿价值。该数据集融合了来自不列颠群岛六种英语方言的录音,涵盖性别、口音等精细元数据,为研究地域性语音变体提供了高保真素材。结合LREC 2020提出的开放多说话人语料库理念,研究者正利用该数据集探索口音适应与跨方言语音模型的泛化能力,尤其是在减少模型对于标准英语发音的偏置方面。数据集通过精心设计的脚本(涵盖全球地名、常用人名以及本地词汇的发音),推动了语音技术对多模态文化地理特征的捕捉,对于构建更具包容性的智能语音助手和方言保护具有深远意义。
以上内容由遇见数据集搜集并总结生成


