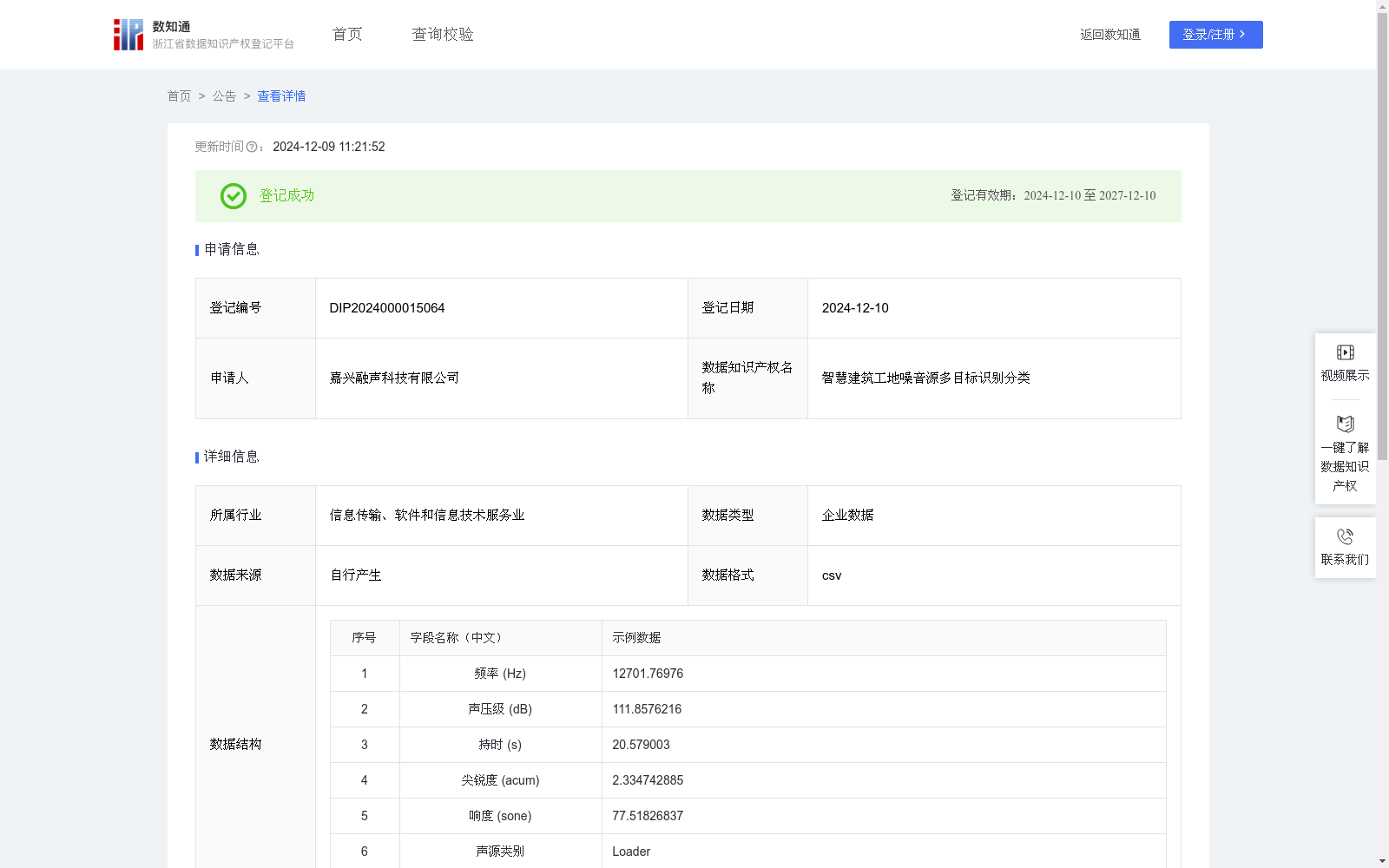
智慧建筑工地噪音源多目标识别分类
收藏浙江省数据知识产权登记平台2024-12-09 更新2024-12-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/98326
下载链接
链接失效反馈官方服务:
资源简介:
为了降低建筑工地作业场景的噪声污染,优化人员作业的环境状态,我们通过CATBoost多目标分类算法进行不同噪音源进行检测分析,从而根据不同噪音的特性进行多目标分类,通过此操作,可以帮助我们筛选出高噪音污染性的运行设备,紧接着再做进一步的环境噪音优化,从而大大提高了从业人员在工作环境的舒适度。1.数据搜集:收集建筑工地场景的声学信号数据,并将其作为特征变量。同时,收集对应噪音源的器件数据,并将其作为分类的目标变量。2.预处理:利用归一化公式x=(xi-min)/(max-min);其中xi是样本字段中第i条数据,x是归一化后的值;并且利用同类均值插补法进行缺失值补充,首先用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。3.数据分析:由于不同设备的声源信息不同,因此我们将他们每个频率的最大值和最小值都搜集出来,紧接着将最大值中最大的那个值作为上限,最小值中最小的那个值作为下限,因此构造出了频率值区间,将区间内的所有值平均分成[0,4000]、[4000,8000]、[8000,12000]、[12000,16000]、[16000,20000]这5类,记为A,B,C,D,E字母,其他数据字段如:声压级、持时、尖锐度、响度的值也同理进行一样的操作,紧接着根据采集到的设备信息,我们可以将它的各个信息值对标字母类别,最后再将各个转换为字母类别的信息按顺序串成一段字母(如:CBAAE对应的就是装载机Loader),最后我们将该字母串导入到交互式文本框中,它就会反馈出对应的声源类别,其中交互式文本框的制作流程如下:首先根据每一个设备信息的上下限确定好可能存在的数字类别,紧接着将所有可能的字母类别进行串联,最终出现了所有属于该设备的字母串类型,最后将这些字母串导入到交互式系统中(也就是所谓的穷举法)。
To reduce noise pollution in construction site operation scenarios and optimize the working environment for personnel, we employ the CATBoost multi-target classification algorithm to detect and analyze different noise sources, thereby performing multi-target classification based on the characteristics of various noises. This operation helps screen out high-noise-pollution operating equipment, followed by further environmental noise optimization, greatly improving the comfort of practitioners in their work environment.
1. Data Collection: Collect acoustic signal data from construction site scenarios as feature variables. Meanwhile, collect device data corresponding to each noise source as the target variables for classification.
2. Preprocessing: Use the normalization formula $x=(x_i - ext{min})/( ext{max} - ext{min})$, where $x_i$ is the $i$-th data point in the sample field, and $x$ is the normalized value. Additionally, adopt the same-category mean imputation method to fill missing values: first predict the type of the missing variable using a hierarchical clustering model, then perform imputation with the mean of that type.
3. Data Analysis: Since the sound source information of different equipment varies, we collect the maximum and minimum values of each frequency band. Next, take the largest value among all collected maximums as the upper limit, and the smallest value among all collected minimums as the lower limit, thus constructing a frequency value interval. Divide this interval evenly into 5 categories: [0, 4000], [4000, 8000], [8000, 12000], [12000, 16000], [16000, 20000], labeled as A, B, C, D, E respectively. The same processing is applied to other data fields including sound pressure level, duration, sharpness, and loudness. Subsequently, based on the collected equipment information, we can map each of its information values to the corresponding letter category. Finally, concatenate all the information converted to letter categories in order into a letter string (for example, CBAAE corresponds to the loader). When this letter string is imported into the interactive text box, it will return the corresponding sound source category. The production process of the interactive text box is as follows: first determine the possible numerical categories based on the upper and lower limits of each device's information, then concatenate all possible letter categories to generate all possible letter string types belonging to that device, and finally import these letter strings into the interactive system (i.e., the so-called exhaustive method).
提供机构:
嘉兴融声科技有限公司
创建时间:
2024-11-08
搜集汇总
数据集介绍
特点
该数据集包含501条建筑工地噪音源数据,用于多目标分类以优化作业环境。数据格式为csv,包含频率、声压级等关键字段,并通过CATBoost算法进行分析。
以上内容由遇见数据集搜集并总结生成


