pd12m-full
收藏Hugging Face2024-11-16 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/sayakpaul/pd12m-full
下载链接
链接失效反馈官方服务:
资源简介:
PD12M数据集是Spawning/PD12M数据集的一个变体,与webdataset格式兼容。该数据集在获得原始作者的许可后公开。数据集通过img2dataset工具下载,并序列化到S3存储桶中。数据集的元数据由多个parquet文件合并成一个pandas数据框。该数据集仍在全面更新中,建议关注更新动态。
创建时间:
2024-11-14
原始信息汇总
PD12M 数据集
基本信息
- 语言: 英语
- 名称: PD12M
- 许可证: CDLA-Permissive-2.0
- 标签: 图像
数据集来源
- 该数据集是从 Spawning/PD12M 下载的变体。
- 该数据集与
webdataset兼容。 - 数据集的公开是在获得原始作者的许可后进行的。
数据下载与处理
-
数据集使用
img2dataset工具下载。 -
下载命令如下: bash img2dataset --url_list pd12m_full.parquet --input_format "parquet" --url_col "url" --caption_col "caption" --output_format webdataset --number_sample_per_shard=5000 --skip_reencode=True --output_folder s3://diffusion-datasets/pd12m --processes_count 16 --thread_count 64 --resize_mode no --enable_wandb True
-
pd12m_full.parquet是通过将 这里 的所有 parquet 文件合并到一个 pandas dataframe 中生成的。
数据集更新状态
- 数据集仓库仍在全面更新中,请关注此空间以获取更新完成的信息。
搜集汇总
数据集介绍
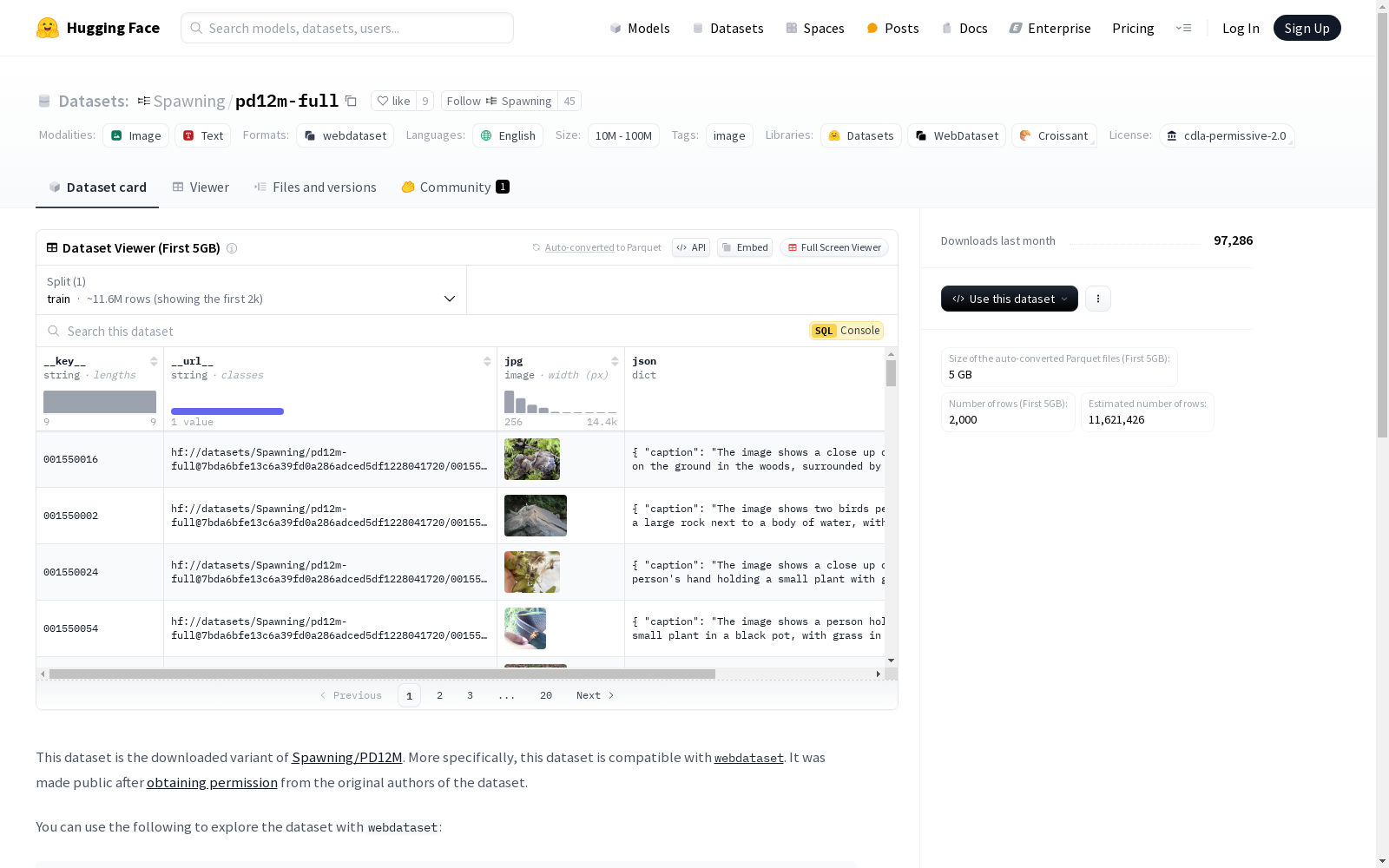
构建方式
pd12m-full数据集的构建过程采用了高效的数据处理工具和分布式计算技术。首先,通过`img2dataset`工具从原始数据源下载图像数据,并将其序列化为`webdataset`格式的分片文件。这些分片文件随后被存储于S3存储桶中,确保了数据的高效访问和存储。此外,原始数据源的所有Parquet文件被整合为一个单一的Pandas DataFrame,进一步简化了数据的处理流程。整个构建过程在CPU集群上完成,并通过`wandb`工具进行了详细的日志记录,确保了数据处理的透明性和可追溯性。
特点
pd12m-full数据集以其大规模和高兼容性著称。该数据集包含了丰富的图像数据,每张图像均附带有详细的元数据信息,包括URL、标题等。数据集采用`webdataset`格式,这种格式不仅支持高效的数据流处理,还能够与多种深度学习框架无缝集成。此外,数据集的分片设计使得其能够在大规模分布式计算环境中高效加载和处理,极大地提升了数据处理的灵活性和可扩展性。
使用方法
使用pd12m-full数据集时,用户可以通过`webdataset`库轻松加载和处理数据。首先,用户需要指定数据集的路径,并通过`wds.WebDataset`方法初始化数据集。随后,用户可以对数据集进行随机打乱和解码操作,以确保数据的多样性和完整性。通过遍历数据集,用户可以访问每张图像的元数据信息,包括图像尺寸、标题等。此外,数据集还提供了一个参考的数据加载器实现,用户可以根据需求进行定制和扩展,以满足不同的研究或应用场景。
背景与挑战
背景概述
PD12M数据集是一个基于图像处理领域的重要数据集,由Spawning团队创建并公开发布。该数据集的主要目的是为图像生成和图像标注任务提供高质量的训练数据。PD12M数据集通过整合多个来源的图像和标注信息,形成了一个大规模的图像数据集,广泛应用于深度学习模型的训练与评估。其创建过程中,研究人员采用了先进的图像采集与处理工具,如`img2dataset`,确保了数据的高效获取与处理。该数据集的发布为图像生成和标注领域的研究提供了重要的数据支持,推动了相关技术的进步。
当前挑战
PD12M数据集在构建与应用过程中面临多重挑战。首先,数据集的构建需要处理海量的图像数据,如何高效地采集、清洗和标注这些数据是一个复杂的技术难题。其次,数据集的多样性与代表性至关重要,确保数据覆盖广泛的场景和类别,以避免模型训练中的偏差问题。此外,数据集的存储与传输也是一个挑战,尤其是在大规模分布式环境下,如何高效地管理和分发数据需要精心设计的技术方案。最后,数据集的合法性与版权问题也不容忽视,确保数据来源的合法性与使用的合规性是数据集构建与发布过程中必须严格把控的环节。
常用场景
经典使用场景
在计算机视觉领域,PD12M数据集广泛应用于图像生成和图像理解任务。其丰富的图像样本和标注信息为深度学习模型提供了多样化的训练数据,尤其在生成对抗网络(GAN)和变分自编码器(VAE)等生成模型中表现出色。通过使用`webdataset`工具,研究人员可以高效地加载和处理大规模图像数据,从而加速模型的训练和评估过程。
解决学术问题
PD12M数据集解决了大规模图像数据集的获取和处理难题,为学术研究提供了高质量的资源。其多样化的图像内容和详细的标注信息有助于提升模型在图像分类、目标检测和图像生成等任务中的性能。此外,该数据集的使用还推动了图像生成技术的创新,为生成模型的训练和评估提供了标准化的基准。
衍生相关工作
基于PD12M数据集,研究人员开发了多种先进的图像生成和处理算法。例如,利用该数据集训练的生成对抗网络(GAN)模型在图像生成任务中表现出色,推动了图像生成技术的发展。此外,该数据集还被用于开发图像修复和图像增强算法,为图像处理领域的研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


