Grasp-Anything
收藏arXiv2023-09-18 更新2024-06-21 收录
下载链接:
https://grasp-anything-2023.github.io
下载链接
链接失效反馈官方服务:
资源简介:
Grasp-Anything是一个由基础模型合成的大规模抓取数据集,旨在解决机器人抓取检测中的长期挑战。该数据集包含100万样本和超过300万个对象,通过利用基础模型的广泛知识库,涵盖了日常生活中的各种对象,从而超越了以往的数据集。Grasp-Anything不仅在多样性和规模上表现出色,还成功支持了基于视觉任务的零样本抓取检测和真实世界机器人实验。数据集的创建过程涉及使用ChatGPT生成场景描述,然后利用基础模型生成图像和抓取姿态。该数据集的应用领域包括机器人抓取、零样本学习和领域适应,旨在通过提供更广泛的对象和更自然的场景设置来提高抓取检测的泛化能力。
Grasp-Anything is a large-scale grasping dataset synthesized by foundation models, aiming to address long-standing challenges in robotic grasping detection. This dataset contains 1 million samples and over 3 million objects, covering a wide range of daily objects by leveraging the extensive knowledge base of foundation models, thus outperforming previous datasets. Grasp-Anything excels not only in diversity and scale, but also successfully supports zero-shot grasping detection for vision-based tasks and real-world robotic experiments. The dataset creation process involves using ChatGPT to generate scene descriptions, followed by generating images and grasping poses via foundation models. Its application areas include robotic grasping, zero-shot learning, and domain adaptation, with the goal of enhancing the generalization performance of grasping detection by providing a broader set of objects and more natural scene configurations.
提供机构:
自动化与控制研究所,维也纳工业大学,维也纳,奥地利
创建时间:
2023-09-18
搜集汇总
数据集介绍
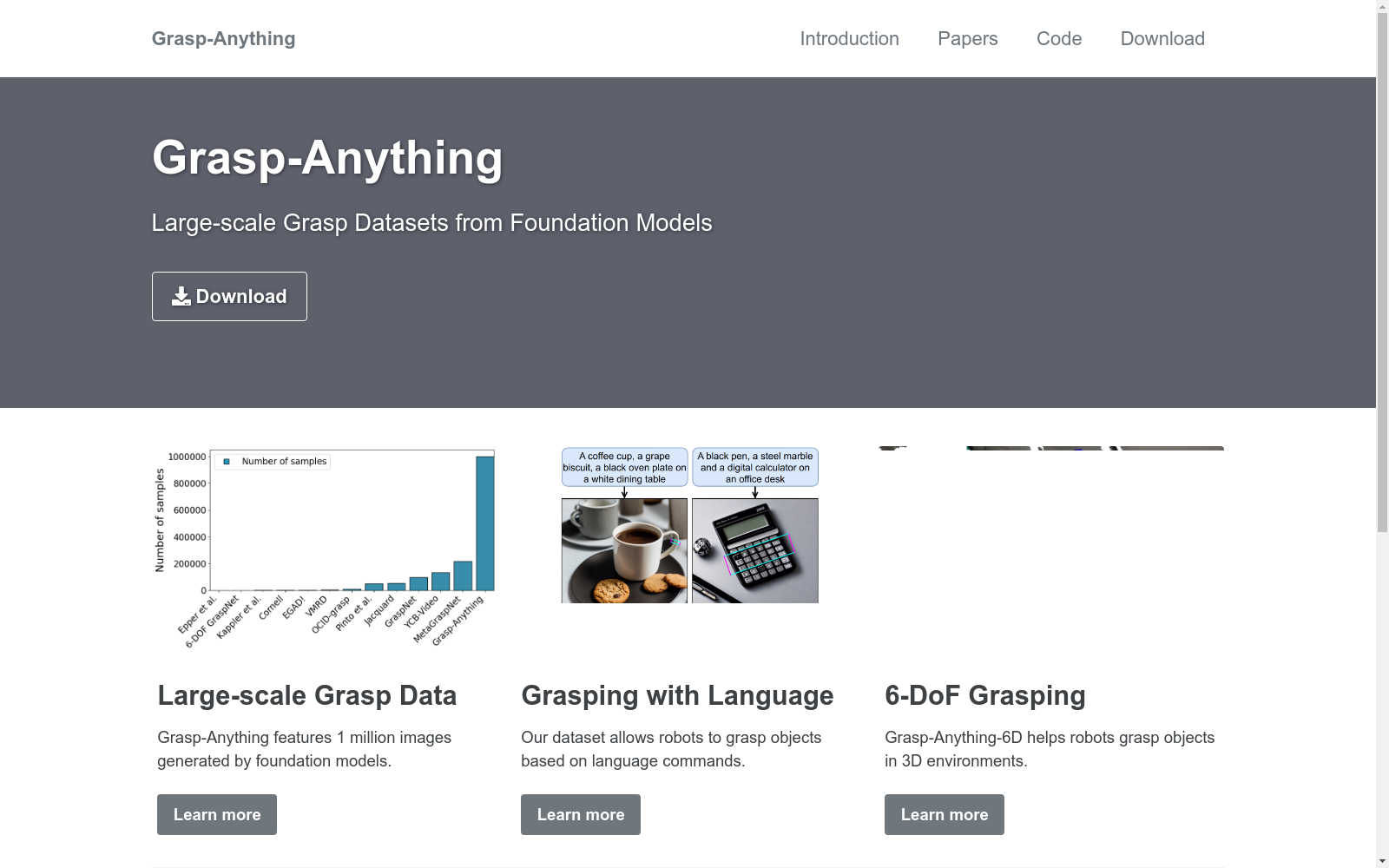
构建方式
Grasp-Anything 数据集的构建方式是通过利用基础模型的知识库来生成大规模的抓握数据集。首先,通过 ChatGPT 进行提示工程,生成包含多样对象的场景描述。然后,使用 Stable Diffusion 2.1 从这些文本提示生成图像,并使用 OFA 和 SegmentAnything 模型收集每个对象实例分割掩码。最后,使用 RAGT-3/3 模型自动生成抓握姿势,并通过计算净扭矩来评估抓握质量。
使用方法
Grasp-Anything 数据集的使用方法包括抓握检测、语言驱动抓握、机器人抓握等多个方面。用户可以使用该数据集来训练抓握检测模型,以实现对不同对象的抓握。此外,该数据集还可以用于语言驱动抓握研究,以实现机器人与人类的自然交互。
背景与挑战
背景概述
抓取检测作为机器人领域的一项基础而长期的研究课题,其相关技术已广泛应用于制造、物流、仓储自动化等领域。随着深度学习技术的进步,数据驱动的方法在机器人抓取领域得到了快速发展。然而,现有的抓取数据集在物体多样性和场景复杂性方面仍存在局限性,难以满足现实世界应用的需求。为了克服这一挑战,研究人员提出了一种新的抓取数据集——Grasp-Anything,该数据集利用基础模型的知识,通过文本描述和图像生成技术,实现了大规模、多样化的物体和场景的覆盖。
当前挑战
Grasp-Anything数据集的构建过程中,面临着一些挑战。首先,如何生成包含无限多样性的物体和场景是一个难题。其次,如何将自然语言描述与场景中的物体进行有效关联,以便实现人机交互的优化。此外,现有的基础模型在功能性和鲁棒性方面仍需进一步提升,以满足现实世界应用的需求。最后,如何将Grasp-Anything数据集应用于实际的机器人抓取任务,并验证其在真实场景中的有效性,也是一项重要的挑战。
常用场景
经典使用场景
Grasp-Anything 数据集的经典使用场景在于零样本抓取检测。通过利用大型语言模型和文本到图像模型的知识,该数据集能够生成包含多种物体和自然场景的图像,从而训练模型进行零样本抓取检测。在计算机视觉和机器人抓取检测方面,Grasp-Anything 数据集都取得了显著的性能提升。
解决学术问题
Grasp-Anything 数据集解决了现有抓取数据集在物体多样性和场景复杂性方面的局限性。通过利用大型语言模型和文本到图像模型的知识,该数据集能够生成包含多种物体和自然场景的图像,从而克服了现有数据集在物体数量和场景配置方面的限制。此外,Grasp-Anything 数据集还考虑了自然语言描述,为人类与机器人之间的交互提供了更多可能性。
实际应用
Grasp-Anything 数据集在实际应用中具有广泛的应用前景。例如,在制造业、物流和仓库自动化等领域,机器人抓取检测是关键任务之一。通过使用 Grasp-Anything 数据集进行训练,机器人可以更好地理解和执行抓取任务,从而提高生产效率。此外,该数据集还可以用于其他相关任务,例如模拟到现实世界的抓取姿势估计、人机交互和语言驱动的移动操作。
数据集最近研究
最新研究方向
Grasp-Anything数据集的最新研究方向主要集中在利用基础模型的知识来提高抓取检测的通用性和鲁棒性。该数据集通过使用ChatGPT和Stable Diffusion等基础模型,生成包含大量样本和对象的抓取数据,从而超越了传统的抓取数据集。实验结果表明,Grasp-Anything数据集能够有效地支持在计算机视觉和机器人方面的零样本抓取检测,并在真实世界的机器人实验中取得了显著成果。此外,该数据集的多模态特性,如文本提示、图像和分割掩码,也为语言驱动抓取检测和人类-机器人交互等研究领域提供了新的研究方向。
相关研究论文
- 1Grasp-Anything: Large-scale Grasp Dataset from Foundation Models自动化与控制研究所,维也纳工业大学,维也纳,奥地利 · 2023年
以上内容由遇见数据集搜集并总结生成


