HW4_CLASSIFICATION_mnar
收藏Hugging Face2025-01-26 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/pppereira3/HW4_CLASSIFICATION_mnar
下载链接
链接失效反馈官方服务:
资源简介:
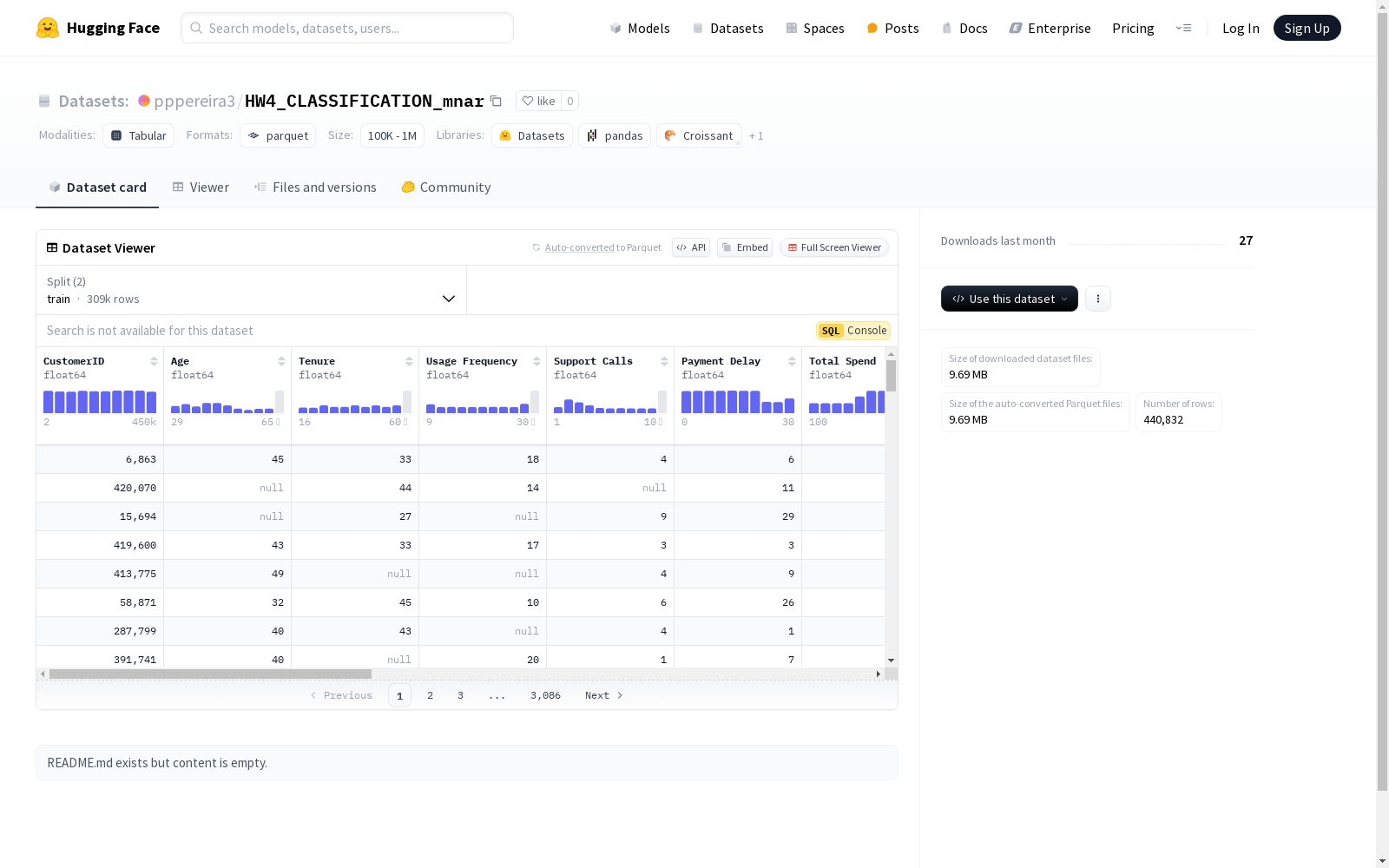
该数据集包含多个与客户相关的特征,如客户ID、年龄、使用频率、支持电话数量、支付延迟、总消费金额、最后一次互动时间等。此外,还包括性别、订阅类型和合同长度等分类特征。数据集被分为训练集和测试集,分别包含308582和132250个样本。数据集的下载大小为9690618字节,总大小为32401164字节。
创建时间:
2025-01-25
搜集汇总
数据集介绍
构建方式
HW4_CLASSIFICATION_mnar数据集的构建,是通过收集客户的个人信息与服务使用记录,包括但不限于年龄、在网时长、使用频率等,并以此作为特征,以性别、订阅类型、合同长度等因素作为标签,形成了具备训练机器学习模型能力的结构化数据集。数据集的构建融合了真实世界场景的复杂性,旨在为分类任务提供有价值的实验资源。
使用方法
使用HW4_CLASSIFICATION_mnar数据集时,用户需要先通过HuggingFace提供的接口下载相应的训练集和测试集。之后,可以利用数据集内置的 splits 信息来加载数据,并对数据进行预处理。针对具体的分类任务,研究者可以基于此数据集的特征和标签,运用各种机器学习算法进行模型训练,并通过测试集对模型性能进行验证。
背景与挑战
背景概述
HW4_CLASSIFICATION_mnar数据集,其创建旨在对客户流失预测模型进行训练与评估。该数据集涵盖客户的基本信息、服务使用情况以及合同类型等维度,共计308582条训练样本与132250条测试样本。其创建时间虽不明确,但从数据集结构来看,它反映了现代商业分析领域对客户行为分析的需求。研究人员或机构未具体标明,但该数据集显然对客户关系管理、市场细分以及个性化营销策略等领域产生了重要影响。
当前挑战
该数据集在构建过程中所遇到的挑战主要包括数据的质量控制和隐私保护。具体挑战体现在:1)保证数据集中的特征如'Usage Frequency'、'Payment Delay'等真实反映客户行为,而非噪声或异常值;2)处理数据中可能存在的缺失值,例如数据集中的'Missing Not At Random'(MNAR)问题;3)在保护客户隐私的同时,确保数据的可用性和实用性。此外,数据集解决的领域问题是如何准确预测客户流失,这对于提高客户满意度和忠诚度、降低运营成本具有显著挑战性。
常用场景
经典使用场景
在客户关系管理的研究领域中,HW4_CLASSIFICATION_mnar数据集被广泛用于分类任务,其经典的使用场景在于预测客户的流失情况。通过分析客户的年龄、使用频率、支持电话次数等特征,研究者能够构建模型以识别潜在的流失客户。
解决学术问题
该数据集解决了识别客户流失这一学术研究问题,对于企业而言,客户流失意味着潜在收益的损失。通过准确预测客户流失,研究者可以帮助企业制定针对性的保留策略,提高客户满意度和忠诚度,从而具有重要的商业价值。
实际应用
在实际应用中,HW4_CLASSIFICATION_mnar数据集可被用于电信、银行等服务业的客户流失预测模型构建。企业利用这些模型进行客户细分,实施个性化的客户关怀措施,从而有效降低流失率,提升服务水平。
数据集最近研究
最新研究方向
在客户关系管理与市场细分领域,HW4_CLASSIFICATION_mnar数据集以其丰富的客户特征及标签,成为研究的热点。近期研究集中于通过深度学习模型探究客户流失预测,以及基于客户行为特征进行精准营销策略的制定。此数据集涵盖了客户的消费习惯、合同类型、年龄等多元信息,为研究提供了宝贵的资源。学者们正利用该数据集挖掘客户行为模式,以期为提升客户满意度和忠诚度提供数据支撑,进而为企业决策提供科学依据。
以上内容由遇见数据集搜集并总结生成


