Moroccan Darija Datasets
收藏github2024-05-10 更新2024-05-31 收录
下载链接:
https://github.com/nainiayoub/moroccan-darija-datasets
下载链接
链接失效反馈官方服务:
资源简介:
该仓库收集了摩洛哥达里加语数据集,按名称、数据源、地区和大小进行分类,旨在帮助用户快速找到适合其任务的数据集。
This repository compiles a collection of Moroccan Darija datasets, categorized by name, data source, region, and size, designed to assist users in swiftly identifying datasets suitable for their tasks.
创建时间:
2022-05-04
原始信息汇总
摩洛哥达里加语数据集概述
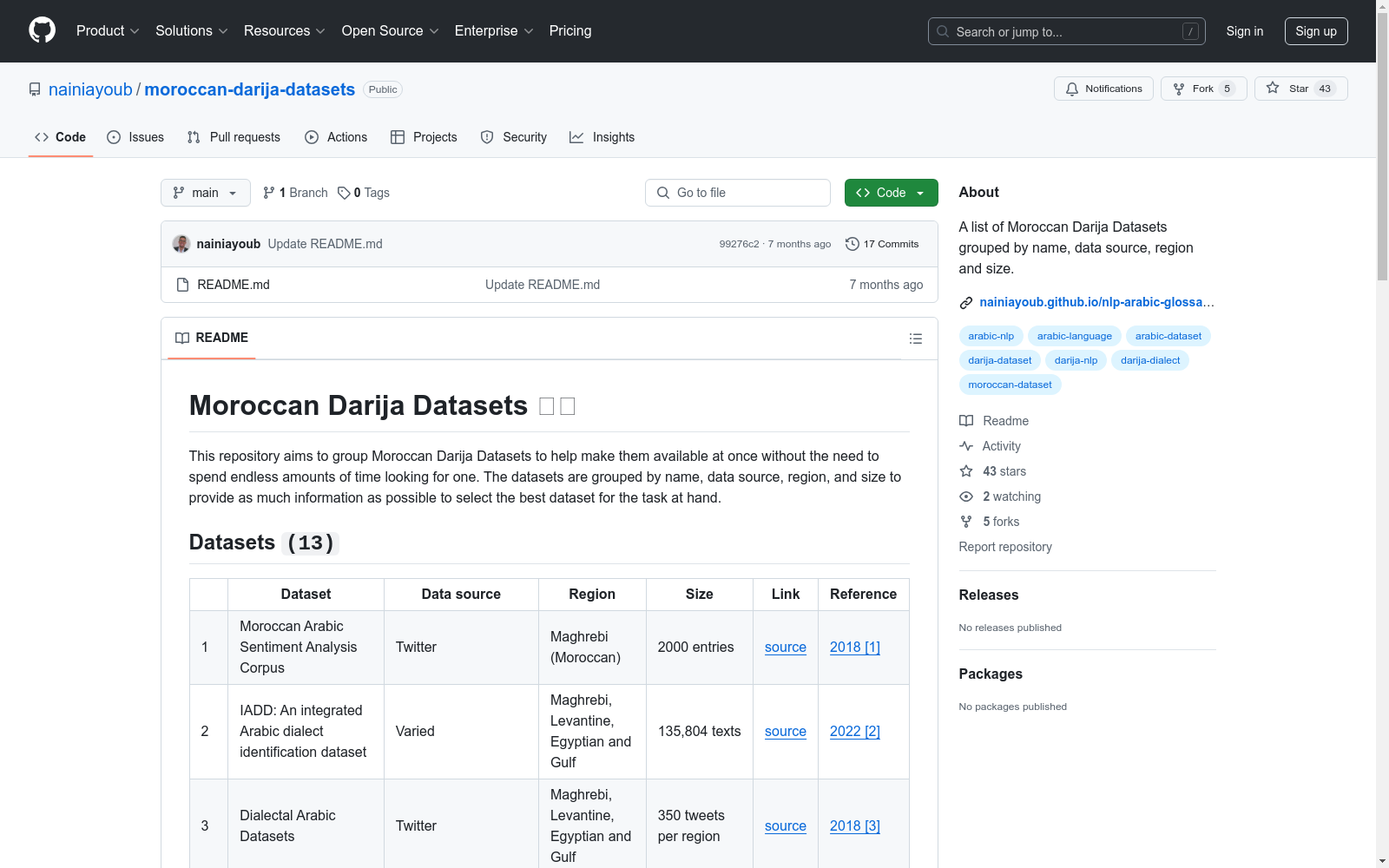
数据集列表
| 编号 | 数据集名称 | 数据来源 | 区域 | 大小 | 链接 | 参考文献 |
|---|---|---|---|---|---|---|
| 1 | 摩洛哥阿拉伯语情感分析语料库 | 马格里布(摩洛哥) | 2000条 | source | 2018 [1] | |
| 2 | IADD: 综合阿拉伯方言识别数据集 | 多源 | 马格里布、黎凡特、埃及和海湾 | 135,804条 | source | 2022 [2] |
| 3 | 方言阿拉伯语数据集 | 马格里布、黎凡特、埃及和海湾 | 350条/区域 | source | 2018 [3] | |
| 4 | MSDA开放数据集 | 社交媒体帖子 | 阿拉伯语 | - | source | 2020 [4] |
| 5 | 摩洛哥方言达里加开放数据集 | 开源贡献 | 马格里布(摩洛哥) | 超过13K | source | 2021 [5] |
| 6 | goud.ma:摩洛哥达里加新闻摘要数据集 | goud.ma | 马格里布(摩洛哥) | 158k新闻文章 | source | 2022 [6] |
| 7 | MNAD:摩洛哥新闻文章数据集 | 摩洛哥新闻网站 | 马格里布(摩洛哥) | 418,563文档 | source | 2021 [7] |
| 8 | QADI: QCRI阿拉伯方言识别 | 马格里布、黎凡特、埃及和海湾 | 540k条推文 | source | 2020 [8] | |
| 9 | Dvoice:摩洛哥方言阿拉伯语自动语音识别开源数据集 | 语音录音+文本转录 | 马格里布(摩洛哥) | 2392训练和600测试文件 | source | 2021 [9] |
| 10 | ASAYAR:阿拉伯-拉丁场景文本定位数据集 | 手动标注的摩洛哥不同高速公路图像 | 马格里布(摩洛哥) | 1763张图像 | source | 2020 [10] |
| 11 | OMCD:摩洛哥攻击性评论数据集 | YouTube评论 | 马格里布(摩洛哥) | 8024条摩洛哥方言评论 | source | 2023 [11] |
| 12 | MORED:摩洛哥建筑物电力消耗数据集 | 摩洛哥各种场所的电力消耗数据 | 马格里布(摩洛哥) | - | source | 2020 [12] |
| 13 | DarNERcorp:摩洛哥方言命名实体识别语料库 | 手动标注的摩洛哥方言语料库 | 马格里布(摩洛哥) | 65,905个令牌 | source | 2023 [13] |
以上数据集涵盖了从社交媒体到新闻文章,再到语音和图像数据的各种类型,主要用于支持摩洛哥达里加语的研究和应用。
搜集汇总
数据集介绍
构建方式
摩洛哥达里亚语数据集(Moroccan Darija Datasets)的构建方式多样且广泛,涵盖了从社交媒体、新闻网站到语音记录等多种数据来源。这些数据集通过不同的采集方法,如手动转录、自动抓取和开放贡献等方式,确保了数据的多样性和代表性。例如,Moroccan Arabic Sentiment Analysis Corpus从Twitter上收集了2000条推文,而Goud.ma新闻数据集则包含了158,000篇新闻文章。这种多源数据的整合,使得研究者能够针对不同的任务需求选择合适的数据集。
特点
该数据集的显著特点在于其多样性和地域针对性。数据集不仅涵盖了摩洛哥达里亚语的多种应用场景,如情感分析、命名实体识别和语音识别,还包含了不同阿拉伯方言的对比数据。此外,数据集的规模差异显著,从数千条记录到数十万条不等,满足了从小规模实验到大规模应用的不同需求。这种多样化的数据结构为语言学研究和自然语言处理提供了丰富的资源。
使用方法
使用摩洛哥达里亚语数据集时,研究者可以根据具体任务选择合适的数据集。例如,进行情感分析时,可以选择Moroccan Arabic Sentiment Analysis Corpus;而进行语音识别研究时,则可选用Dvoice数据集。数据集的下载和使用通常通过GitHub或相关平台进行,部分数据集还提供了详细的文档和引用信息,便于学术研究和实际应用。研究者在使用时应遵循数据集的许可协议,并参考相关文献以确保研究的准确性和可靠性。
背景与挑战
背景概述
摩洛哥达里亚语(Moroccan Darija)数据集的创建旨在汇集多种与摩洛哥达里亚语相关的数据资源,以促进对该语言的研究与应用。该数据集由多个研究机构和研究人员共同贡献,涵盖了从2018年至2023年的多个研究项目。核心研究问题包括情感分析、方言识别、命名实体识别、语音识别等多个领域。这些数据集的发布不仅为摩洛哥达里亚语的自然语言处理(NLP)研究提供了丰富的资源,还为跨语言和跨文化的研究提供了宝贵的数据支持,推动了该领域的技术进步。
当前挑战
摩洛哥达里亚语数据集面临的主要挑战包括:1) 数据多样性和质量控制,由于数据来源广泛,涵盖社交媒体、新闻、语音记录等多种形式,确保数据的准确性和一致性是一个重要问题;2) 方言的复杂性和变异性,摩洛哥达里亚语作为阿拉伯语的一个方言,具有高度的地域性和语言变异,这对模型的泛化能力提出了挑战;3) 数据标注的难度,尤其是涉及情感分析、命名实体识别等任务时,人工标注的成本和准确性是构建高质量数据集的关键障碍。
常用场景
经典使用场景
摩洛哥达里亚语数据集(Moroccan Darija Datasets)在自然语言处理领域中,主要用于处理摩洛哥方言的语言任务。这些数据集涵盖了从情感分析到命名实体识别等多种任务,尤其在社交媒体文本分析中表现突出。例如,Moroccan Arabic Sentiment Analysis Corpus 提供了2000条来自Twitter的摩洛哥方言语料,适用于情感分析模型的训练与评估。
实际应用
在实际应用中,摩洛哥达里亚语数据集被广泛应用于社交媒体监控、新闻摘要生成和语音识别系统等领域。例如,Goud.ma新闻数据集可用于训练自动摘要生成模型,帮助摩洛哥用户快速获取新闻要点。此外,Dvoice数据集为摩洛哥方言的自动语音识别提供了基础,推动了本地化语音助手和翻译工具的开发。
衍生相关工作
基于摩洛哥达里亚语数据集,研究者们开发了多种先进的自然语言处理模型。例如,IADD数据集促进了阿拉伯方言识别模型的研究,而OMCD数据集则为社交媒体中的有害内容检测提供了新的解决方案。此外,DarNERcorp数据集的发布激发了更多关于摩洛哥方言命名实体识别的研究,推动了该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


