Hyperphantasia
收藏arXiv2025-07-16 更新2025-07-18 收录
下载链接:
https://huggingface.co/datasets/shahab7899/Hyperphantasia
下载链接
链接失效反馈官方服务:
资源简介:
Hyperphantasia是一个合成基准,旨在评估多模态大型语言模型(MLLMs)的内心可视化能力。该数据集由四类精心设计的谜题组成,每个谜题都有三个难度级别,总共包含1200个样本。这些谜题旨在测试模型在推理、预测和抽象等任务中构建和操作内部视觉表示的能力。数据集已公开,可用于评估当前MLLMs在内心可视化能力方面的表现,并探索强化学习在提高视觉模拟能力方面的潜力。
Hyperphantasia is a synthetic benchmark developed to evaluate the mental visualization capabilities of multimodal large language models (MLLMs). This dataset comprises four categories of meticulously crafted puzzles, each with three difficulty levels, totaling 1200 samples. These puzzles are designed to test the model's capacity to construct and manipulate internal visual representations across tasks such as reasoning, prediction, and abstraction. The dataset is publicly available, allowing researchers to evaluate the performance of current MLLMs in terms of mental visualization capabilities and explore the potential of reinforcement learning in improving visual simulation abilities.
提供机构:
南加州大学电子与计算机工程系
创建时间:
2025-07-16
原始信息汇总
Hyperphantasia数据集概述
基本信息
- 许可证: MIT
- 数据集名称: Hyperphantasia
- 标签: mental_visualization, text, image, benchmark, puzzles
- 任务类别: multiple-choice, question-answering, visual-question-answering
- 语言: 英语 (en)
- 数据规模: 1K<n<10K
数据集描述
Hyperphantasia是一个合成的视觉问答(VQA)基准数据集,用于从视觉角度探究多模态大型语言模型(MLLMs)的心理可视化能力。该数据集揭示了最先进的模型在需要视觉模拟和想象的简单任务中表现不佳。
数据集内容
- 样本数量: 1200个
- 谜题类型: 4种不同的谜题
- 分类: 插值(Interpolation)和外推(Extrapolation)两类
- 难度级别: 三个难度级别,用于评估MLLMs心理可视化能力的范围和泛化性
使用信息
- 评估代码: 可在Github仓库中找到
搜集汇总
数据集介绍
构建方式
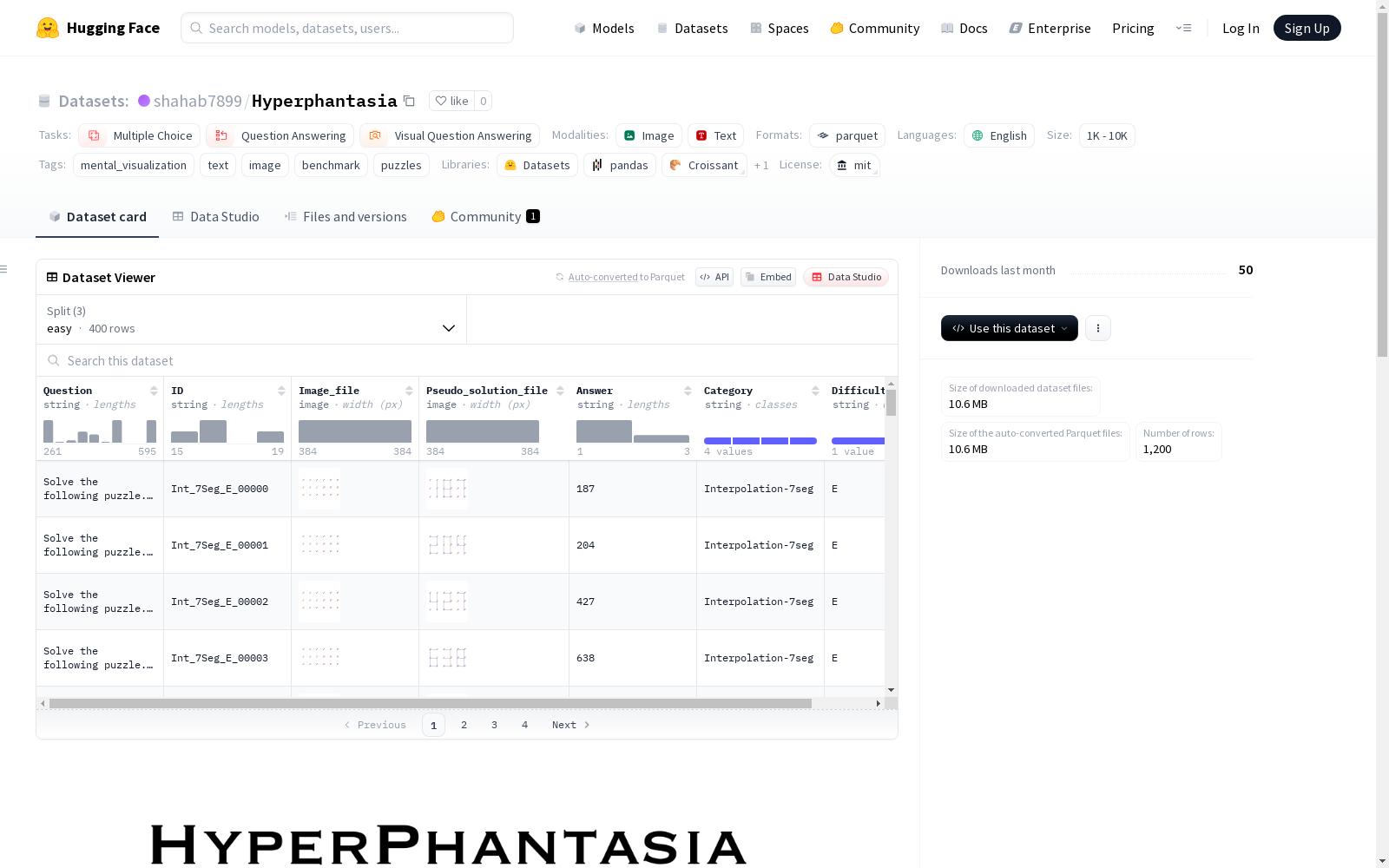
Hyperphantasia数据集的构建采用了系统性设计方法,旨在评估多模态大语言模型的心理可视化能力。研究团队通过程序化生成技术创建了四种不同类型的视觉谜题,涵盖插值和外推两大认知范畴。每个任务类型下设三个难度等级(简单、中等、困难),通过调整视觉线索的完整性和认知复杂度来精确控制难度参数。具体构建过程包括:七段数码管任务通过随机采样数字并转换为线段连接模式;连连看任务基于DomainNet数据集提取物体轮廓点阵;线性轨迹和抛物线轨迹任务则通过参数化建模生成几何图形。最终数据集包含1200个样本,每个难度等级各100个样本,确保了评估的全面性和统计显著性。
特点
该数据集的核心特征体现在其认知维度的创新设计上。不同于传统视觉基准主要测试被动感知能力,Hyperphantasia专注于评估主动构建心理表象的高级认知功能。四大任务类型分别针对视觉模式补全(七段数码管和连连看)和运动轨迹预测(线性与抛物线轨迹)等核心认知能力。数据集通过精确控制点阵密度、轨迹可见比例等超参数实现难度梯度化,其中困难级别仅保留40%的视觉信息,极大提升了任务的认知挑战性。特别值得注意的是,所有任务均采用合成生成方式,既保证了数据多样性,又避免了真实图像带来的偏见干扰,为模型能力评估提供了纯净的实验环境。
使用方法
使用该数据集时需遵循标准化评估协议。研究者需将384×384像素的谜题图像与结构化提示词共同输入待测模型,要求模型在解释推理过程后将最终答案封装于<ANSWER>标签内。评估过程采用零温度参数确保结果确定性,并允许三次响应生成机会以处理格式错误。对于七段数码管等特殊任务,可选择性添加视觉辅助线进行消融实验。数据集支持多种评估模式:既可直接测试原始心理可视化能力,也可通过强化学习框架(如GRPO算法)进行微调实验。官方提供的Huggingface数据集和GitHub评估代码库实现了全流程的标准化,包括难度分级统计、人类基线对比以及跨模型性能分析等功能模块。
背景与挑战
背景概述
Hyperphantasia数据集由南加州大学电气与计算机工程系的Mohammad Shahab Sepehri等研究人员于2025年提出,旨在评估多模态大语言模型(MLLMs)的心理可视化能力。心理可视化是人类认知的核心组成部分,涉及在内部构建和操作视觉表征以支持推理、预测和抽象等任务。尽管MLLMs在被动视觉感知任务上取得了显著进展,但在主动构建视觉模式以支持问题解决的能力评估方面仍存在空白。Hyperphantasia通过四种精心设计的谜题任务填补了这一空白,为研究MLLMs在视觉推理和想象能力方面的表现提供了标准化评估工具。该数据集的发布推动了多模态模型在动态视觉理解领域的深入研究。
当前挑战
Hyperphantasia数据集面临的挑战主要体现在两个方面:领域问题挑战和构建过程挑战。在领域问题方面,心理可视化任务要求模型具备高度的视觉推理和想象能力,而当前MLLMs在此类任务上的表现远不及人类,尤其是在处理复杂视觉模式或需要动态模拟的任务时。构建过程中的挑战包括:1) 设计具有不同难度级别的任务以系统评估模型能力;2) 确保生成的谜题既能反映真实世界的视觉问题,又能避免引入偏见或简化过度;3) 平衡任务的多样性与评估的一致性,以全面衡量模型的心理可视化能力。此外,数据集的构建还需克服模型对视觉输入的鲁棒性不足问题,例如在七段数码管任务中,模型即使面对明确的视觉线索仍表现不佳。
常用场景
经典使用场景
Hyperphantasia数据集专为评估多模态大语言模型(MLLMs)的心理可视化能力而设计,其经典使用场景包括通过四种精心设计的谜题任务(如七段数字识别、点连接物体辨识、线性轨迹预测和抛物线轨迹预测)来测试模型在视觉推理、空间模拟和动态预测等认知任务中的表现。这些任务通过三个难度级别(简单、中等、困难)逐步增加复杂性,为研究者提供了系统分析模型在视觉构造与动态推理能力上的基准工具。
实际应用
在自动驾驶、机器人导航和增强现实等需要动态视觉理解的领域,Hyperphantasia的评估框架具有直接应用价值。例如,自动驾驶系统需预测周围物体的运动轨迹,而该数据集的抛物线轨迹任务可量化模型在此类物理模拟任务中的可靠性。其难度分级机制还能辅助企业针对特定应用场景选择适配的模型复杂度。
衍生相关工作
该数据集推动了认知增强型多模态模型的研究浪潮,衍生出基于强化学习的心理可视化训练框架(如GRPO改进方案)。其任务设计思想影响了后续空间推理评测基准(如LEGO-Puzzles和SRBench),并启发了对模型视觉鲁棒性的深入研究,例如针对七段数字任务中模型对几何模式识别缺陷的专项分析。
以上内容由遇见数据集搜集并总结生成


