nemotron-hq-1b-0to4k-testv334
收藏Hugging Face2026-05-19 更新2026-05-20 收录
下载链接:
https://huggingface.co/datasets/C10X/nemotron-hq-1b-0to4k-testv334
下载链接
链接失效反馈官方服务:
资源简介:
Nemotron HQ 1B 0-to-4K Test v334 是一个在Hugging Face平台上展示的数据集,旨在提供结构化的数据分割,以方便模型训练和评估。数据集包含高质量的文本数据,存储为Parquet格式,并根据序列长度组织为两个子集:短序列(长度范围为1到2048个token)和长序列(长度范围为2049到4096个token)。数据明确划分为训练集、评估集和测试集,每个分割都包含对应这两种长度范围的数据文件。
Nemotron HQ 1B 0-to-4K Test v334 is a dataset presented on the Hugging Face platform, designed to provide structured data splits for model training and evaluation. It contains high-quality text data in Parquet format, organized into two subsets based on sequence length: short sequences (ranging from 1 to 2048 tokens) and long sequences (ranging from 2049 to 4096 tokens). The data is explicitly divided into train, eval, and test splits, with each split including data files corresponding to both length ranges.
创建时间:
2026-05-16
原始信息汇总
根据您提供的数据集详情页面README文件内容,以下是该数据集的概述:
数据集名称
Nemotron HQ 1B 0-to-4K Test v334
数据集主页
- 地址:https://huggingface.co/datasets/C10X/nemotron-hq-1b-0to4k-testv334
数据集配置
- 配置名称:
default - 数据文件格式:Parquet
数据划分与文件路径
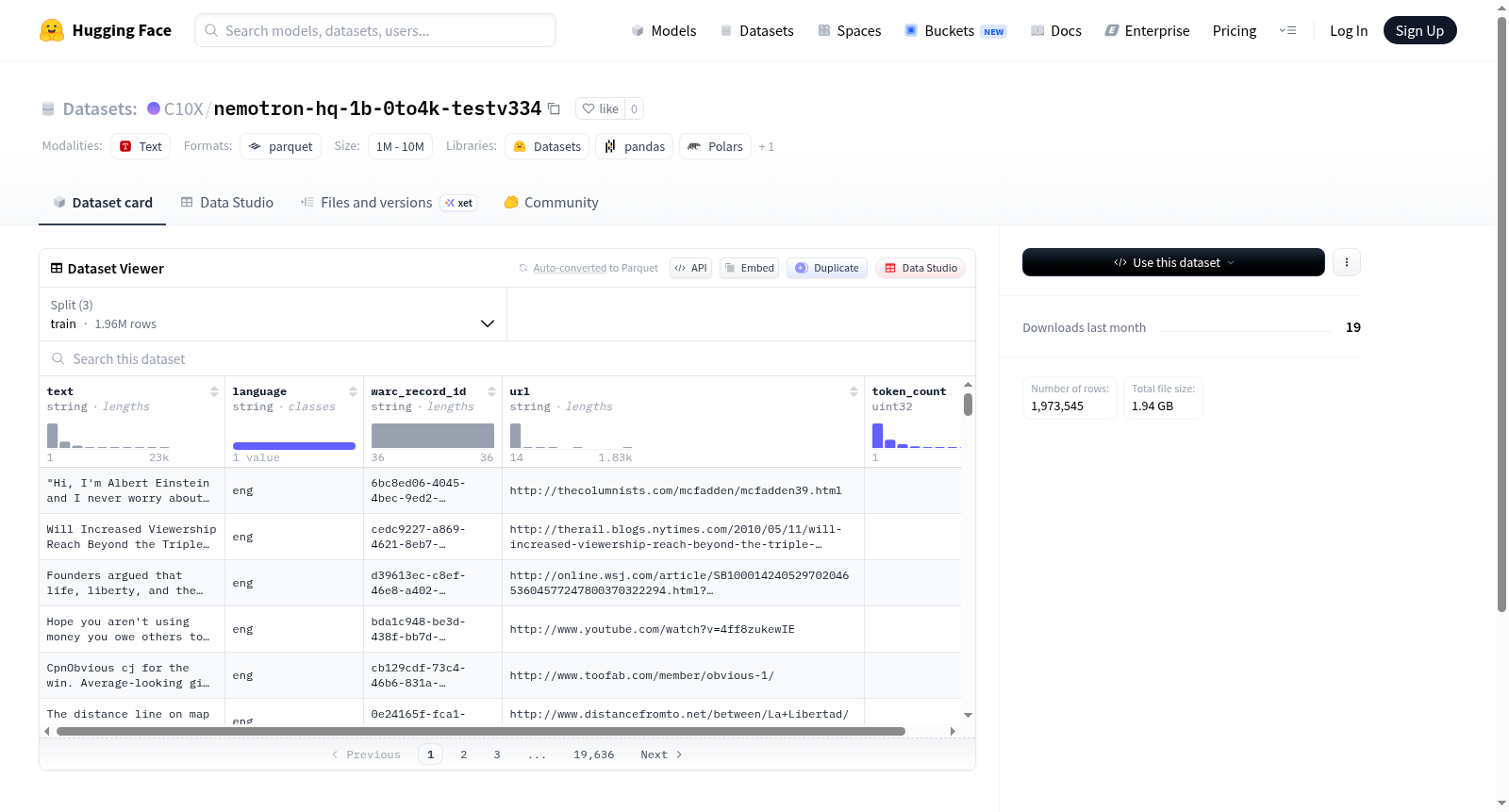
数据集包含三个划分,每个划分下包含短文本(1-2048长度)和长文本(2049-4096长度)两个子集:
| 划分 | 短文本子集(short_0001_2048) | 长文本子集(long_2049_4096) |
|---|---|---|
| train | train/short_0001_2048/hq_train_short_0001_2048.parquet |
train/long_2049_4096/hq_train_long_2049_4096.parquet |
| eval | eval/short_0001_2048/hq_eval_short_0001_2048.parquet |
eval/long_2049_4096/hq_eval_long_2049_4096.parquet |
| test | test/short_0001_2048/hq_test_short_0001_2048.parquet |
test/long_2049_4096/hq_test_long_2049_4096.parquet |
关键说明
- 数据集卡片通过显式定义划分映射,使得Hugging Face数据集查看器能够分别展示
train、eval和test三个子集。
搜集汇总
数据集介绍
构建方式
该数据集通过整合短序列(长度1至2048 token)与长序列(长度2049至4096 token)两种语料范畴的parquet文件构建而成。数据按照序列长度进行分层,形成短序列与长序列两大子集,并进一步划分为训练集、评估集与测试集三个标准划分,以确保模型能够在不同序列长度分布上得到充分训练与评估。
使用方法
使用该数据集时,用户可直接通过HuggingFace的datasets库加载,利用预设的'train'、'eval'和'test'参数访问对应划分。加载后,可根据任务需求选择全量数据或按序列长度子集进行过滤,例如仅使用短序列或长序列数据进行特定场景的模型性能评估。数据集以高效的parquet格式存储,支持快速读写与分布式处理。
背景与挑战
背景概述
Nemotron HQ 1B 0-to-4K Test v334 数据集由 NVIDIA 研究团队于2025年创建,旨在为大规模语言模型提供高质量、长上下文的训练与评估语料。该数据集聚焦于文本序列长度从0到4096个token的精细划分,通过将数据分为短文本(1-2048 token)与长文本(2049-4096 token)两部分,支持模型在多种上下文长度下的性能验证。作为 Nemotron 系列模型的重要组成部分,该数据集继承了 NVIDIA 在高效稀疏注意力机制与长文本生成领域的积累,其发布显著推动了自然语言处理中长文档理解与生成任务的研究进展,为社区提供了标准化测试基准。
当前挑战
当前数据集面临的核心挑战包括:其一,领域问题层面,长上下文建模中模型对远距离依赖的捕捉仍存在瓶颈,尤其在2049-4096 token区间,自注意力机制的复杂度与信息衰减问题亟待突破;其二,构建过程中,数据必须严格划分长度区间以确保训练与测试分布一致,但自然地长文本中语义连贯性难以保证,导致部分样本存在噪声;此外,预训练语料的版权与隐私过滤、多语言覆盖不足,也增加了数据集泛化应用的难度。
常用场景
经典使用场景
在自然语言处理与大规模语言模型的研究领域中,Nemotron-HQ-1B-0to4K-Testv334数据集以其精细化的序列长度划分而备受瞩目。该数据集将文本样本按长度划分为短序列(1至2048 tokens)与长序列(2049至4096 tokens)两个子集,专为评估和微调语言模型在不同上下文窗口下的理解与生成能力而设计。经典使用场景包括:对比模型在处理短文本与长文本时的性能差异,验证模型对长程依赖关系的捕获效果,以及测试模型在有限长度约束下的信息压缩与推理能力。研究者常利用该数据集构建阶梯式评估基准,系统性地考察模型从局部语义到全局语篇的渐进式理解水平。
解决学术问题
该数据集精准地回应了当前语言模型研究中的核心学术困境:如何量化模型在不同上下文长度下的泛化能力与鲁棒性。传统的单一长度基准难以揭示模型在长短文本间的性能波动,而Nemotron-HQ-1B-0to4K-Testv334通过结构化分片,使研究者得以深入探究长度变化对模型注意力机制、记忆衰减和语义连贯性的影响。它解决了模型在长文本中存在的“上下文遗忘”与“表征稀释”等关键问题,并为改进位置编码、优化稀疏注意力机制提供了可复现的评估平台。这一数据集的发布推动了语言模型长文本处理理论的成熟,促使学界从静态性能比较转向动态能力诊断。
实际应用
在实际产业应用中,该数据集为构建高效、可靠的对话系统、文档摘要工具和生成长篇文章的AI写作助手提供了关键的验证工具。企业可以借助其短序列子集快速迭代模型对问答、指令遵循等即时交互任务的响应质量,而长序列子集则用于评估模型在合同解析、学术文献综述、技术文档生成等需深度理解上下文的场景中的表现。数据集中预设的train、eval、test三分离设计,使得自动化评估流水线能够无缝集成,大幅降低了模型部署前的验证周期。此外,该数据集还可辅助构建面向特定行业的长文本处理基准,例如法律案例分析、医疗报告生成或金融报告解读等。
数据集最近研究
最新研究方向
该数据集聚焦于长文本建模领域的前沿探索,特别是针对大规模语言模型在0至4K token长度范围内的泛化能力与训练稳定性。通过精心设计的短文本(1-2048 token)与长文本(2049-4096 token)分层拆分,该数据集为研究渐进式扩展上下文窗口的训练策略提供了标准化评估基准。当前热点方向包括:利用此类区分序列长度的数据集验证RoPE位置编码的外推能力、探索分段式训练对模型记忆长程依赖关系的影响,以及在推理时通过KV-cache压缩实现高效长文本处理。该数据集的发布推动了语言模型在忠实性、相关性等维度上向真实世界的对话与文档分析场景靠拢,对于构建能够处理法律、医疗等超长专业文件的智能系统具有奠基意义。
以上内容由遇见数据集搜集并总结生成


