Edustories-en
收藏Hugging Face2024-09-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MU-NLPC/Edustories-en
下载链接
链接失效反馈官方服务:
资源简介:
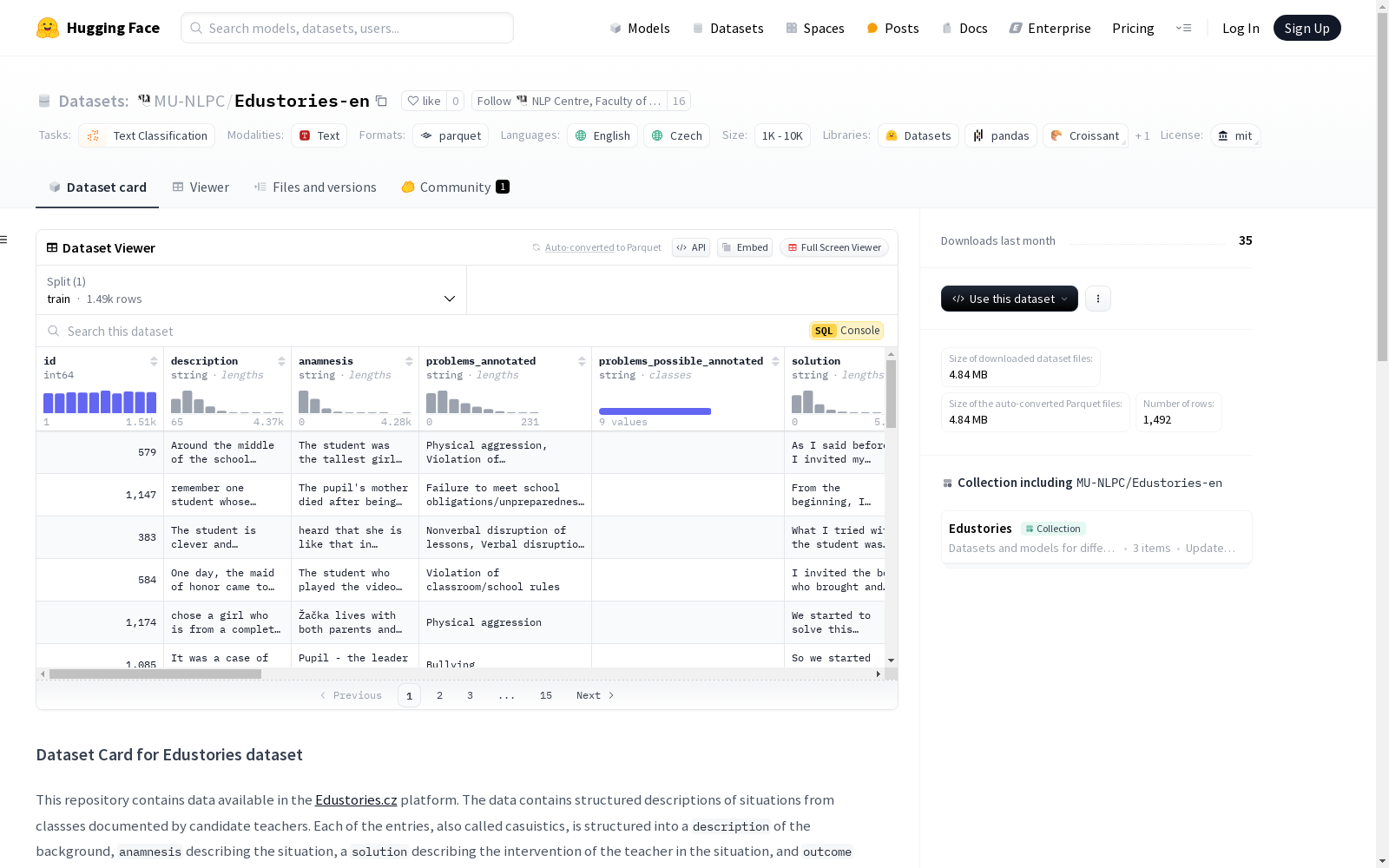
Edustories数据集包含从Edustories.cz平台获取的结构化情境描述,主要涉及候选教师在课堂中的案例。每个条目包括背景描述、情境描述、教师干预描述和干预结果描述。数据集还包括手动标注的类别,用于描述情境、干预和结果,以及学生的属性和教师的属性。捷克语的结构化故事部分也包含在内。数据集正在开发中,未来计划扩展更多未标注的故事。
提供机构:
NLP Centre, Faculty of Informatics, Masaryk University
创建时间:
2024-09-14
搜集汇总
数据集介绍
构建方式
Edustories-en数据集的构建过程体现了教育案例研究的系统化与标准化。该数据集源自Edustories.cz平台,通过半自动解析原始自由文本日志,并结合数据库中的附加信息,形成了结构化的教育案例描述。每个案例均经过匿名化处理,并由标注者手动关联多个类别,以最佳匹配所描述的情境、干预措施及其结果。数据收集由实习教师在其教学实践中完成,采用标准化表格记录,并经过多阶段匿名化处理,确保数据隐私。
特点
Edustories-en数据集的特点在于其高度结构化的教育案例描述与丰富的标注信息。每个案例包含背景描述、情境分析、教师干预措施及结果等结构化文本,并附有标注者手动关联的问题、解决方案及影响类别。此外,数据集还提供了学生与教师的属性信息,如年龄、诊断、教学经验等,为教育研究提供了多维度的分析视角。数据集支持双语(英语与捷克语),并包含不确定标注类别,为研究提供了灵活性。
使用方法
Edustories-en数据集适用于教育领域的文本分类与案例研究任务。研究者可通过分析结构化文本与标注信息,探索教学干预的效果、学生行为模式及教师决策过程。数据集中的不确定标注类别可用于评估标注一致性,而双语支持则为跨语言研究提供了便利。用户可通过HuggingFace平台下载数据集,并根据需求选择英语或捷克语版本进行深入研究。
背景与挑战
背景概述
Edustories-en数据集由捷克马萨里克大学的Jan Nehyba、Jiřina Karasová和Michal Štefánik等研究人员于2023年至2026年间创建,旨在收集和分析教育实践中的案例研究。该数据集源自Edustories.cz平台,记录了实习教师在教学实践中收集的课堂情境案例。每个案例包含背景描述、情境分析、教师干预措施及结果等结构化信息,并通过半自动解析和人工标注的方式,将每个案例与预定义的问题、解决方案和结果类别相关联。该数据集为教育研究提供了丰富的实证数据,有助于深入理解教学干预的效果及其对学生的影响。
当前挑战
Edustories-en数据集在构建过程中面临多重挑战。首先,数据来源于自由文本的课堂记录,需通过半自动解析和人工标注将其转化为结构化数据,这一过程对数据质量和一致性提出了较高要求。其次,标注过程中存在不确定性,部分标签由标注者在不确定的情况下分配,可能影响数据的可靠性。此外,数据集目前尚处于开发阶段,部分条目缺失,需在后续标注轮次中补充。最后,由于数据涉及学生和教师的个人信息,确保数据的匿名化和隐私保护也是构建过程中的重要挑战。
常用场景
经典使用场景
Edustories-en数据集在教育研究领域具有广泛的应用,尤其是在教师培训和教育干预策略的评估中。该数据集通过结构化的案例描述,帮助研究者分析教师在课堂中遇到的具体问题及其解决方案。这些案例不仅涵盖了学生的背景信息,还包括教师的干预措施和最终结果,为教育研究提供了丰富的实证数据。
实际应用
在实际应用中,Edustories-en数据集被广泛用于教师培训课程的设计与评估。通过分析数据集中的案例,教育机构可以为新教师提供更具针对性的培训内容,帮助他们更好地应对课堂中的复杂情境。此外,该数据集还可用于开发智能教育系统,通过自动化分析课堂案例,为教师提供个性化的教学建议。
衍生相关工作
基于Edustories-en数据集,许多经典研究工作得以展开。例如,研究者利用该数据集开发了基于机器学习的教育干预效果预测模型,能够根据课堂案例预测不同干预措施的潜在效果。此外,该数据集还催生了多项关于教师行为与学生表现之间关系的研究,为教育心理学和教育政策制定提供了重要的理论支持。
以上内容由遇见数据集搜集并总结生成


