TC-Bench
收藏arXiv2024-06-13 更新2024-06-21 收录
下载链接:
https://weixi-feng.github.io/tc-bench
下载链接
链接失效反馈官方服务:
资源简介:
TC-Bench是一个专注于视频生成中时间组合性的基准数据集,由加州大学圣巴巴拉分校和滑铁卢大学合作创建。该数据集包含120个精心设计的文本提示和对应的真实视频,覆盖了广泛的视觉实体、场景和风格。数据集的创建过程涉及多轮人机交互,通过GPT-4生成提示,并由人工筛选和匹配YouTube视频。TC-Bench主要用于评估视频生成模型在处理时间维度上的组合变化能力,如属性转换、物体关系变化和背景切换,旨在解决视频生成中的时间组合性问题。
TC-Bench is a benchmark dataset focusing on temporal compositionality in video generation, co-created by the University of California, Santa Barbara and the University of Waterloo. This dataset includes 120 carefully curated text prompts and their corresponding ground-truth videos, covering a wide spectrum of visual entities, scenes and styles. The development of the dataset involved multiple rounds of human-computer interaction: prompts were generated via GPT-4, followed by manual screening and matching with YouTube videos. TC-Bench is primarily utilized to assess the ability of video generation models to handle compositional changes in the temporal dimension, such as attribute transitions, alterations in object relationships and background switching, with the aim of resolving the issue of temporal compositionality in video generation.
提供机构:
加州大学圣巴巴拉分校 2滑铁卢大学
创建时间:
2024-06-13
搜集汇总
数据集介绍
构建方式
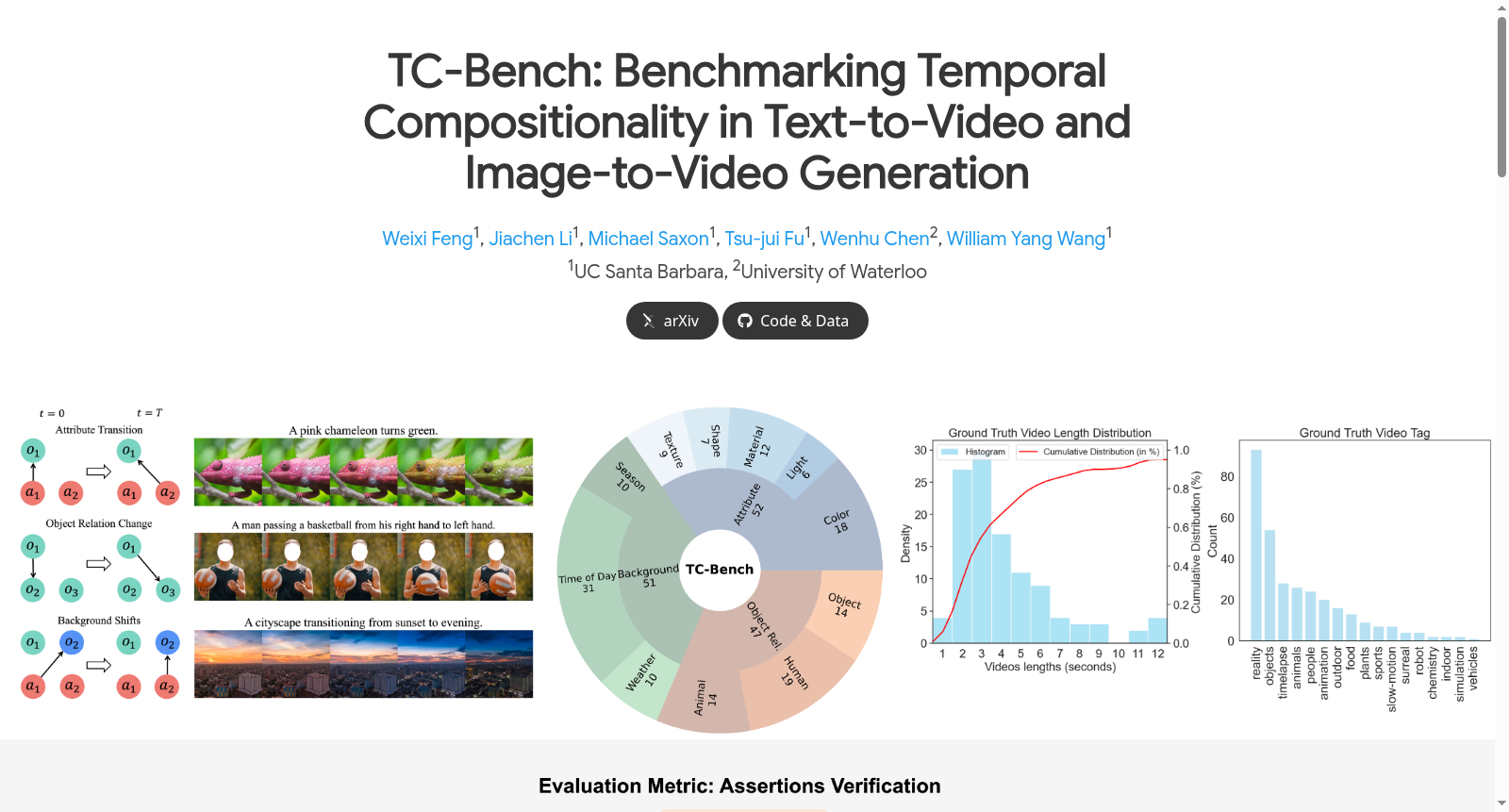
在视频生成领域,评估模型对时间维度上概念组合变化的处理能力至关重要。TC-Bench的构建采用了一种精心设计的多轮人机协同方法。研究团队首先基于场景图理论定义了三种时间组合性变化类型:属性过渡、对象关系变化和背景转换。通过结合人工编写的提示模板与GPT-4的生成能力,创建了明确描述场景初始与最终状态的文本提示。随后,通过人工标注从YouTube平台筛选与提示高度匹配的真实视频,经过多轮迭代调整,最终形成了包含150个文本提示的TC-Bench-T2V子集和120个文本-视频对的TC-Bench-I2V子集。这种构建方式确保了数据集的多样性和现实性,同时通过明确的场景状态描述减少了语义模糊性。
特点
TC-Bench的核心特点在于其专注于时间组合性这一视频生成中的关键挑战。数据集通过精心设计的提示明确规定了场景的初始与最终状态,要求生成视频必须展现概念随时间的动态组合变化,如物体属性的渐变或对象关系的转换。其提示涵盖了广泛的视觉实体、场景和风格,包括颜色、形状、材质等多种属性变化,以及传递、放置等动态关系。此外,数据集不仅支持文本到视频模型的评估,还通过配对的真实视频扩展了对图像到视频模型的适用性,特别是生成式帧插值任务。这种设计使得TC-Bench能够深入揭示模型在时间维度上理解与合成组合变化的能力。
使用方法
使用TC-Bench进行评估时,研究者首先将文本提示输入文本到视频模型,或将起始与结束帧输入图像到视频模型,以生成相应视频。评估过程采用数据集提出的TCR和TC-Score指标,这些指标基于视觉语言模型对生成视频的断言验证。具体而言,通过GPT-4生成针对关键帧的断言问题,覆盖过渡完成度、过渡对象一致性和其他对象三个维度,再使用视觉语言模型验证这些断言。对于图像到视频模型,还会结合CLIP特征相似性来评估帧间一致性。这种评估方法能够量化模型完成时间组合性变化的能力,并与人类判断具有较高相关性,为模型改进提供了明确方向。
背景与挑战
背景概述
在视频生成领域,随着扩散模型和大规模视频数据集的进步,文本到视频(T2V)和图像到视频(I2V)生成技术取得了显著发展。然而,现有评估基准多聚焦于简单动作或静态场景,未能充分衡量视频中随时间演进的概念组合与关系转变,即时间组合性。为填补这一空白,加州大学圣塔芭芭拉分校与滑铁卢大学的研究团队于2024年提出了TC-Bench基准。该基准旨在系统评估生成视频中物体属性、对象关系及背景场景随时间变化的组合性,通过精心设计的文本提示、真实世界视频对及鲁棒评估指标,推动视频生成模型在时间维度上的语义理解与一致性生成能力。
当前挑战
TC-Bench所针对的核心领域挑战在于视频生成中的时间组合性建模,即要求模型不仅理解文本提示中的初始与最终状态,还需在时间轴上合成平滑且符合逻辑的概念转变。具体而言,模型需克服三大挑战:在属性转换中准确呈现物体属性的渐进变化;在对象关系变化中维持主体一致性并模拟合理的交互动态;在背景转换中协调前景对象与背景场景的时序一致性。在数据集构建过程中,研究团队面临真实世界视频与提示对齐的困难,需通过多轮人工迭代确保视频内容精确反映组合性转变,同时避免语义歧义。此外,开发与人类判断高度相关的评估指标亦是一大挑战,需设计基于视觉语言模型的断言验证机制,以量化生成视频的组合性完成度与对齐质量。
常用场景
经典使用场景
在视频生成领域,评估模型对时间维度上概念组合与演变的忠实度是一项核心挑战。TC-Bench作为专门针对时间组合性的基准测试,其经典使用场景在于系统性地评测文本到视频(T2V)与图像到视频(I2V)生成模型能否准确合成出随时间推移而发生的属性转换、物体关系变化及背景迁移。通过精心设计的文本提示词与对应的真实视频对,该数据集为模型生成视频中概念的涌现、绑定与过渡提供了标准化的评估框架,使得研究者能够量化模型在时间组合性上的表现,从而揭示其在理解动态场景描述与保持跨帧一致性方面的能力边界。
实际应用
在实际应用层面,TC-Bench为开发高质量视频生成系统提供了关键的评估工具与改进方向。例如,在影视特效预演、动态广告生成、教育内容制作以及交互式媒体创作中,模型需要准确理解并合成如“物体颜色渐变”、“物品传递过程”或“场景时光流转”等复杂时间组合变化。该数据集的评估结果能够帮助工程师识别现有模型在时序逻辑理解与跨帧一致性合成上的薄弱环节,进而指导模型架构优化、训练数据构建以及提示词工程。通过推动模型在时间组合性上的性能提升,最终促进生成视频在真实性、叙事连贯性与用户意图对齐方面达到更高标准。
衍生相关工作
TC-Bench的提出催生并衔接了多项围绕视频生成组合性与评估的经典研究工作。在方法层面,其评估框架启发了对多阶段生成策略的探索,例如基于LLM生成帧级提示或布局的Free-Bloom、LVD等方法,以及结合文本到图像模型与视频插帧技术的SDXL+SEINE基线。在评估体系上,它与VBench、EvalCrafter、FETV等综合性视频评估基准形成互补,共同推动了视频生成评估向更细粒度、更贴近人类感知的方向发展。同时,其基于断言与视觉语言模型的评估思路,也为后续开发更强大的视频理解模型与端到端的视频对齐度量提供了重要的方法论参考与研究起点。
以上内容由遇见数据集搜集并总结生成


