sentiments
收藏Hugging Face2024-08-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/mbzuai-ugrip-statement-tuning/sentiments
下载链接
链接失效反馈官方服务:
资源简介:
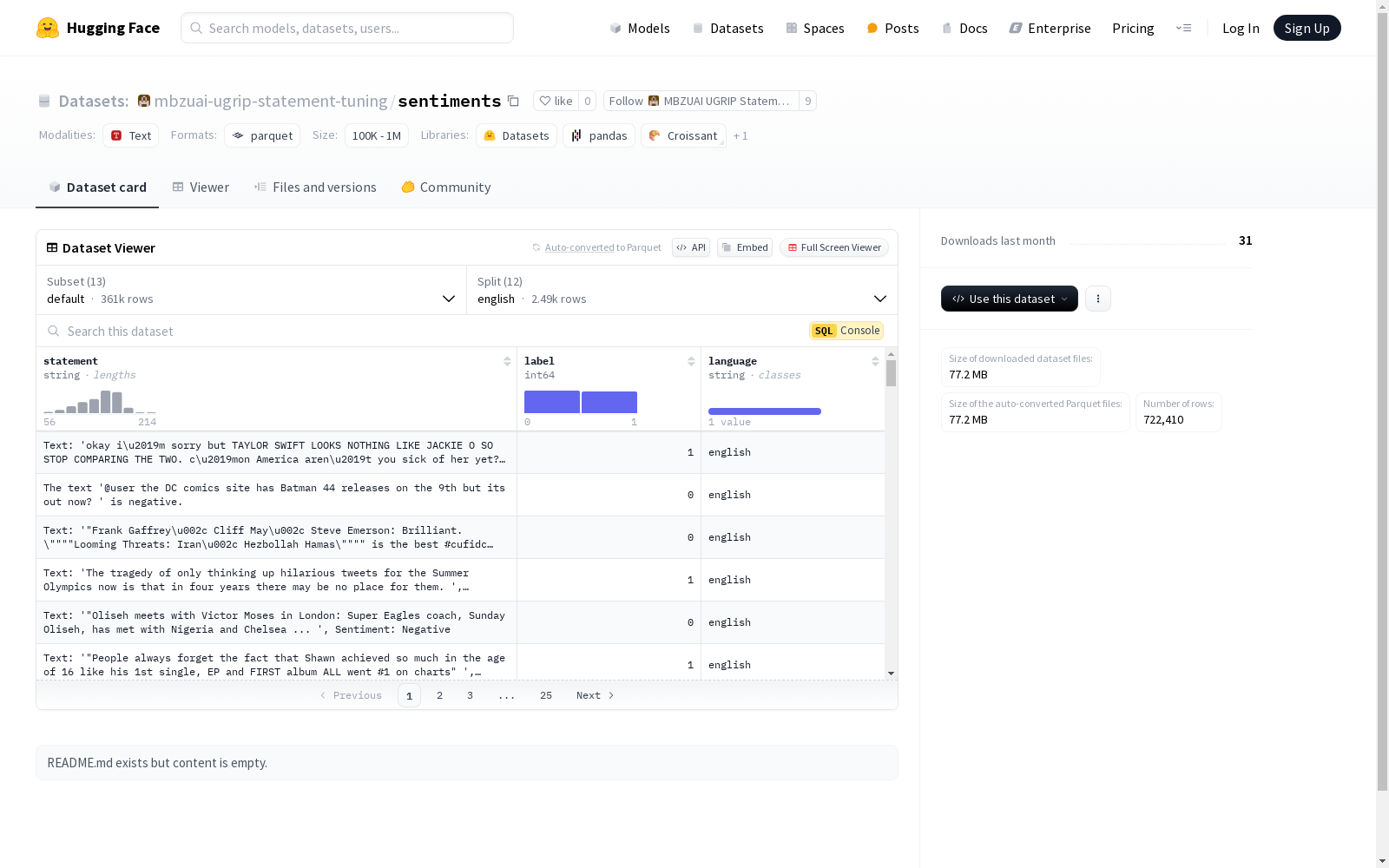
该数据集包含多种语言的文本数据,每条数据包含一个陈述(statement)、一个标签(label)和一个语言标识(language)。支持的语言包括英语、日语、中文、西班牙语、阿拉伯语、马来语、法语、印地语、德语、印度尼西亚语、葡萄牙语和意大利语。每个语言版本的数据量和文件路径都有详细记录。
This dataset contains multilingual text data. Each sample consists of a statement, a label, and a language identifier. Supported languages include English, Japanese, Chinese, Spanish, Arabic, Malay, French, Hindi, German, Indonesian, Portuguese, and Italian. The data volume and file path for each language version are fully documented.
提供机构:
MBZUAI UGRIP Statement Tuning
创建时间:
2024-08-01
原始信息汇总
数据集概述
数据集配置
阿拉伯语 (Arabic)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 468004
- 样本数: 2435
- 下载大小: 187657 字节
- 数据集大小: 468004 字节
中文 (Chinese)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 30420137
- 样本数: 160399
- 下载大小: 14156530 字节
- 数据集大小: 30420137 字节
默认 (Default)
- 特征:
statement: 字符串label: 64位整数language: 字符串
- 分割:
english:- 字节数: 393918
- 样本数: 2485
japanese:- 字节数: 53826202
- 样本数: 160356
chinese:- 字节数: 32184526
- 样本数: 160399
spanish:- 字节数: 325604
- 样本数: 2439
arabic:- 字节数: 492354
- 样本数: 2435
malay:- 字节数: 1024644
- 样本数: 6263
french:- 字节数: 367743
- 样本数: 2475
hindi:- 字节数: 307080
- 样本数: 2454
german:- 字节数: 298242
- 样本数: 2408
indonesian:- 字节数: 3518289
- 样本数: 14591
portuguese:- 字节数: 314949
- 样本数: 2450
italian:- 字节数: 342823
- 样本数: 2450
- 下载大小: 38641710 字节
- 数据集大小: 93396374 字节
英语 (English)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 366583
- 样本数: 2485
- 下载大小: 169002 字节
- 数据集大小: 366583 字节
法语 (French)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 342993
- 样本数: 2475
- 下载大小: 141033 字节
- 数据集大小: 342993 字节
德语 (German)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 274162
- 样本数: 2408
- 下载大小: 126387 字节
- 数据集大小: 274162 字节
印地语 (Hindi)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 284994
- 样本数: 2454
- 下载大小: 129800 字节
- 数据集大小: 284994 字节
印度尼西亚语 (Indonesian)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 3314015
- 样本数: 14591
- 下载大小: 1364537 字节
- 数据集大小: 3314015 字节
意大利语 (Italian)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 315873
- 样本数: 2450
- 下载大小: 139217 字节
- 数据集大小: 315873 字节
日语 (Japanese)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 51901930
- 样本数: 160356
- 下载大小: 21448616 字节
- 数据集大小: 51901930 字节
马来语 (Malay)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 968277
- 样本数: 6263
- 下载大小: 434926 字节
- 数据集大小: 968277 字节
葡萄牙语 (Portuguese)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 280649
- 样本数: 2450
- 下载大小: 115824 字节
- 数据集大小: 280649 字节
西班牙语 (Spanish)
- 特征:
statement: 字符串label: 64位整数
- 分割:
train:- 字节数: 298775
- 样本数: 2439
- 下载大小: 132791 字节
- 数据集大小: 298775 字节
搜集汇总
数据集介绍
构建方式
sentiments数据集的构建基于多语言文本的情感分析任务,涵盖了阿拉伯语、中文、英语、法语、德语、印地语、印尼语、意大利语、日语、马来语、葡萄牙语和西班牙语等多种语言。数据集的构建过程通过收集不同语言的自然语言文本,并对其进行情感标注,形成结构化的训练数据。每个语言配置均包含‘statement’(文本内容)和‘label’(情感标签)两个核心特征,确保了数据的多样性和广泛适用性。
使用方法
sentiments数据集的使用方法较为灵活,用户可根据具体需求选择特定语言配置进行下载和使用。数据集以标准化的格式存储,支持直接加载至机器学习框架中进行训练和测试。用户可通过HuggingFace平台获取数据文件,并利用‘statement’和‘label’字段进行情感分类模型的开发与评估。此外,数据集的多语言特性使其适用于跨语言情感分析、多语言模型训练等研究场景。
背景与挑战
背景概述
sentiments数据集是一个多语言情感分析数据集,涵盖了阿拉伯语、中文、英语、法语、德语、印地语、印尼语、意大利语、日语、马来语、葡萄牙语和西班牙语等多种语言。该数据集的创建旨在为跨语言情感分析研究提供丰富的语料资源,推动自然语言处理领域在多语言环境下的情感理解能力。通过包含多种语言的文本数据,sentiments数据集为研究者提供了一个统一的平台,用于比较和分析不同语言之间的情感表达差异及其共性。该数据集的影响力不仅体现在其多语言覆盖的广度上,还体现在其为跨文化情感分析模型的开发与评估提供了重要支持。
当前挑战
sentiments数据集在构建和应用过程中面临多重挑战。首先,情感分析本身具有高度主观性,不同语言和文化背景下的情感表达方式差异显著,如何准确标注和统一情感标签是一个复杂的问题。其次,数据集的构建需要处理多语言文本的收集、清洗和标注,尤其是在低资源语言中,获取高质量的情感标注数据尤为困难。此外,跨语言情感分析模型的开发需要克服语言间的语义差异和文化背景差异,这对模型的泛化能力提出了更高的要求。最后,数据集的规模和质量在不同语言之间存在不平衡,部分语言的样本量较少,可能影响模型的训练效果和评估结果的可靠性。
常用场景
经典使用场景
在自然语言处理领域,sentiments数据集被广泛用于情感分析任务。通过分析文本中的情感倾向,研究者能够训练模型以识别和分类不同语言中的情感表达。该数据集的多语言特性使其成为跨语言情感分析研究的理想选择,尤其是在处理阿拉伯语、中文、英语等多种语言的文本时,能够有效提升模型的泛化能力。
解决学术问题
sentiments数据集解决了情感分析领域中的多语言情感分类问题。传统的情感分析模型往往局限于单一语言,难以应对全球化背景下的多语言需求。该数据集通过提供多种语言的标注数据,帮助研究者开发出能够跨语言识别情感倾向的模型,推动了情感分析技术的国际化和普及化。
实际应用
在实际应用中,sentiments数据集被广泛应用于社交媒体监控、客户反馈分析和市场情绪预测等领域。例如,企业可以通过分析社交媒体上的用户评论,了解消费者对产品或服务的情感倾向,从而优化营销策略。此外,该数据集还被用于开发多语言情感分析工具,帮助跨国公司在全球范围内进行情感监控和舆情分析。
数据集最近研究
最新研究方向
在情感分析领域,sentiments数据集因其多语言支持和大规模标注数据而备受关注。近年来,研究者们利用该数据集探索跨语言情感分析的迁移学习模型,旨在通过一种语言的训练数据提升其他语言的情感分类性能。此外,随着预训练语言模型(如BERT、GPT)的广泛应用,sentiments数据集被用于微调这些模型,以提升其在特定语言和文化背景下的情感理解能力。特别是在低资源语言(如马来语、印尼语)的情感分析任务中,该数据集为模型提供了宝贵的训练资源,推动了多语言情感分析技术的发展。
以上内容由遇见数据集搜集并总结生成


