Salesforce/cos_e
收藏Hugging Face2024-01-04 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/Salesforce/cos_e
下载链接
链接失效反馈官方服务:
资源简介:
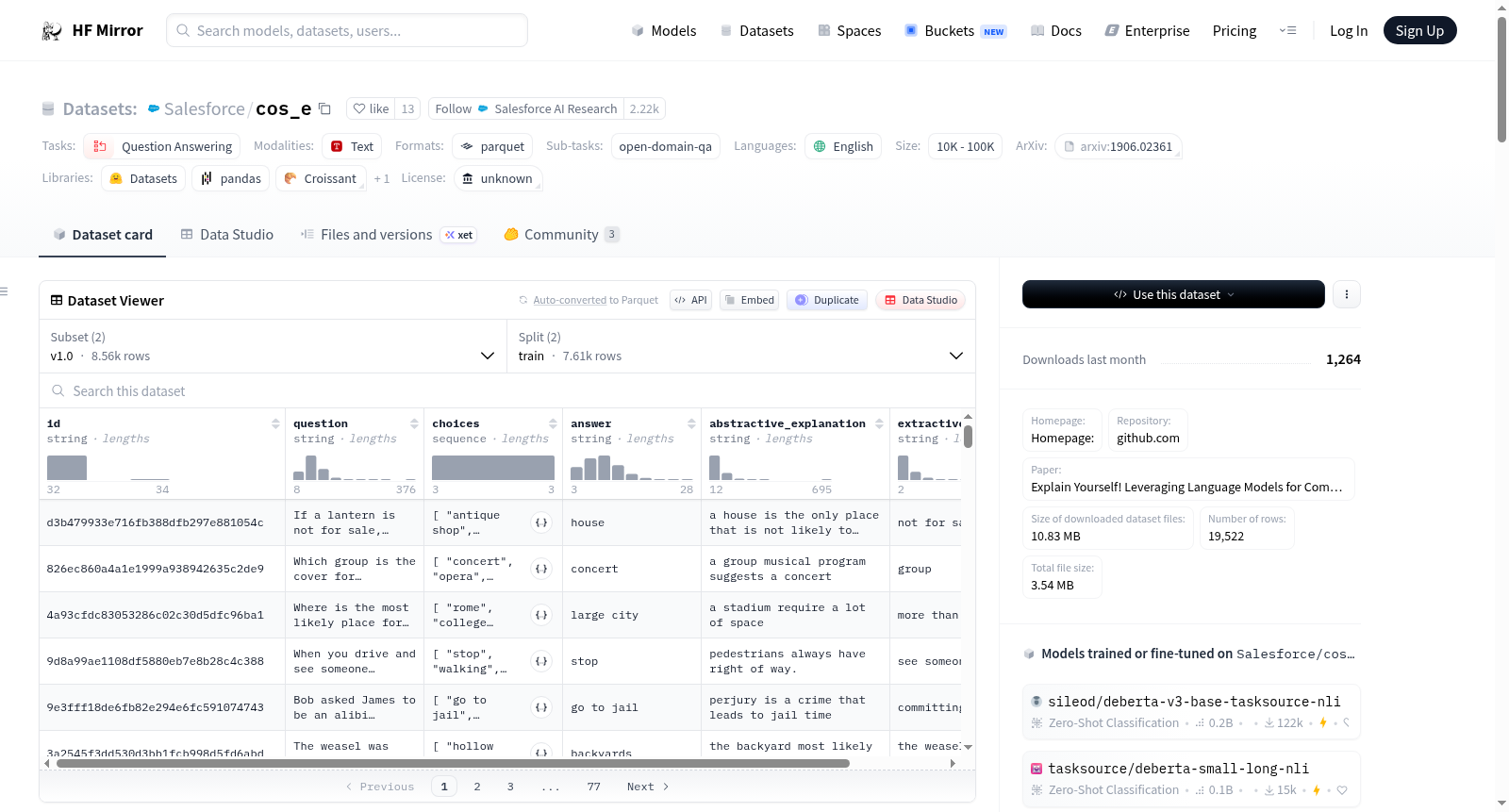
Commonsense Explanations (CoS-E) 数据集旨在训练语言模型,使其能够自动生成解释,这些解释可以在训练和推理过程中使用。数据集包含两个版本(v1.0和v1.11),每个版本都有训练集和验证集。数据集的字段包括id、question、choices、answer、abstractive_explanation和extractive_explanation。数据集的语言为英语,且为单语数据集。数据集的创建过程涉及众包,但具体的注释过程和注释者信息未提供。数据集的许可证信息未知。
The Commonsense Explanations (CoS-E) dataset is designed to train language models to automatically generate explanations that can be used during both training and inference stages. It has two versions, v1.0 and v1.11, each with a training split and a validation split. The dataset's fields include id, question, choices, answer, abstractive_explanation, and extractive_explanation. It is an English-only monolingual dataset. The dataset was created via crowdsourcing, but specific annotation procedures and annotator information are not provided. The license information of the dataset is unknown.
提供机构:
Salesforce
原始信息汇总
数据集概述
基本信息
- 数据集名称: Commonsense Explanations (CoS-E)
- 语言: 英语
- 许可: 未知
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据集: 扩展自commonsense_qa
- 任务类别: 问答
- 任务ID: 开放领域问答
- PapersWithCode ID: cos-e
- 美观名称: Commonsense Explanations
数据集配置
v1.0
- 特征:
id: 字符串question: 字符串choices: 字符串序列answer: 字符串abstractive_explanation: 字符串extractive_explanation: 字符串
- 分割:
train: 7610个样本, 2067971字节validation: 950个样本, 260669字节
- 下载大小: 1588340字节
- 数据集大小: 2328640字节
v1.11
- 特征:
id: 字符串question: 字符串choices: 字符串序列answer: 字符串abstractive_explanation: 字符串extractive_explanation: 字符串
- 分割:
train: 9741个样本, 2702777字节validation: 1221个样本, 329897字节
- 下载大小: 1947552字节
- 数据集大小: 3032674字节
数据集结构
数据实例
v1.0
- 下载大小: 4.30 MB
- 生成数据集大小: 2.34 MB
- 总磁盘使用量: 6.64 MB
- 示例: json { "abstractive_explanation": "this is open-ended", "answer": "b", "choices": ["a", "b", "c"], "extractive_explanation": "this is selected train", "id": "42", "question": "question goes here." }
v1.11
- 下载大小: 6.53 MB
- 生成数据集大小: 3.05 MB
- 总磁盘使用量: 9.58 MB
- 示例: json { "abstractive_explanation": "this is open-ended", "answer": "b", "choices": ["a", "b", "c"], "extractive_explanation": "this is selected train", "id": "42", "question": "question goes here." }
数据字段
v1.0
id: 字符串question: 字符串choices: 字符串列表answer: 字符串abstractive_explanation: 字符串extractive_explanation: 字符串
v1.11
id: 字符串question: 字符串choices: 字符串列表answer: 字符串abstractive_explanation: 字符串extractive_explanation: 字符串
数据分割
| 配置名称 | 训练集样本数 | 验证集样本数 |
|---|---|---|
| v1.0 | 7610 | 950 |
| v1.11 | 9741 | 1221 |
搜集汇总
数据集介绍
构建方式
在常识推理研究领域,构建高质量的解释性数据集对于提升模型的可解释性至关重要。CoS-E数据集源自Commonsense QA的扩展,通过众包方式精心构建。数据收集过程聚焦于生成与常识问答配对的多维度解释,涵盖抽象性与抽取性两种类型。标注工作由经过筛选的众包人员完成,确保了数据的多样性与可靠性。数据集包含两个版本,v1.0与v1.11,分别提供了不同规模的训练与验证样本,以适应多样化的研究需求。
特点
该数据集的核心特征在于其双重解释机制,同时提供抽象性解释与抽取性解释,为模型训练提供了丰富的语义监督信号。数据实例以结构化形式呈现,每个样本包含问题、多项选择答案及对应的解释文本,便于直接应用于开放域问答任务。数据规模适中,涵盖超过一万个样本,平衡了数据丰富性与计算效率。其单语种(英语)设计专注于常识推理的深度探索,为自然语言处理领域提供了宝贵的基准资源。
使用方法
在模型开发过程中,CoS-E数据集主要用于训练语言模型生成常识解释,可集成至CAGE框架以增强推理能力。研究人员可通过HuggingFace平台直接加载数据集,利用其标准化的数据分割进行训练与验证。典型应用包括微调预训练模型,以同时优化答案预测与解释生成任务。数据字段清晰明确,支持灵活的实验设计,例如对比抽象性与抽取性解释对模型性能的影响,推动可解释人工智能的前沿进展。
背景与挑战
背景概述
在自然语言处理领域,常识推理一直是人工智能系统面临的核心难题之一。Salesforce公司于2019年推出的常识解释数据集(CoS-E),由Nazneen Fatema Rajani等研究人员创建,旨在通过提供人类生成的解释来增强语言模型的推理能力。该数据集基于Commonsense QA扩展而来,其核心研究问题聚焦于如何让模型不仅给出答案,还能生成合理的解释,从而提升模型的可解释性与推理可靠性。CoS-E的提出推动了可解释人工智能在常识推理方向的发展,为后续研究提供了重要的基准资源。
当前挑战
CoS-E数据集致力于解决开放域问答中常识推理的可解释性挑战,要求模型不仅选择正确答案,还需生成抽象与抽取式解释,这考验模型对隐含知识的理解与表达。在构建过程中,数据收集依赖于众包,确保解释的多样性与质量面临挑战,例如标注一致性与语义深度的平衡。此外,从源数据扩展时,需保持解释与问题之间的逻辑连贯性,避免引入偏见或噪声,这对数据清洗与验证提出了较高要求。
常用场景
经典使用场景
在自然语言处理领域,常识推理任务长期面临模型缺乏可解释性的挑战。CoS-E数据集通过提供丰富的抽象性与抽取性解释标注,为训练语言模型生成常识解释奠定了数据基础。该数据集最经典的使用场景在于支持CAGE框架,使模型能够在推理过程中自动生成解释,从而提升问答系统的透明度和可靠性。研究人员利用这些标注数据,训练模型不仅输出答案,还能生成合乎逻辑的解释,推动了可解释人工智能在常识推理方向的发展。
解决学术问题
CoS-E数据集主要针对常识推理中模型决策过程不透明这一核心学术问题。传统模型往往给出答案而缺乏推理依据,该数据集通过提供人工标注的解释,使得研究者能够开发出能够同时生成答案与解释的模型。这解决了模型可解释性不足的难题,促进了人工智能从黑箱向白箱的转变。其意义在于为评估和提升模型推理能力提供了标准化的基准,影响了后续诸多关于可信人工智能的研究工作。
衍生相关工作
基于CoS-E数据集,学术界衍生了一系列关于可解释常识推理的经典研究工作。其提出的CAGE框架启发了后续如ECQA等数据集的构建,这些数据集进一步扩展了解释的多样性和复杂性。许多研究以此为基础,探索如何将解释生成与答案预测进行联合优化,或利用解释作为额外的监督信号来增强模型鲁棒性。此外,该数据集也促进了如知识增强型语言模型等方向的发展,推动了常识推理与可解释人工智能两大领域的交叉融合。
以上内容由遇见数据集搜集并总结生成


