boldt-dc-1b-orpo-onpolicy-de
收藏Hugging Face2026-05-17 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/mayflowergmbh/boldt-dc-1b-orpo-onpolicy-de
下载链接
链接失效反馈官方服务:
资源简介:
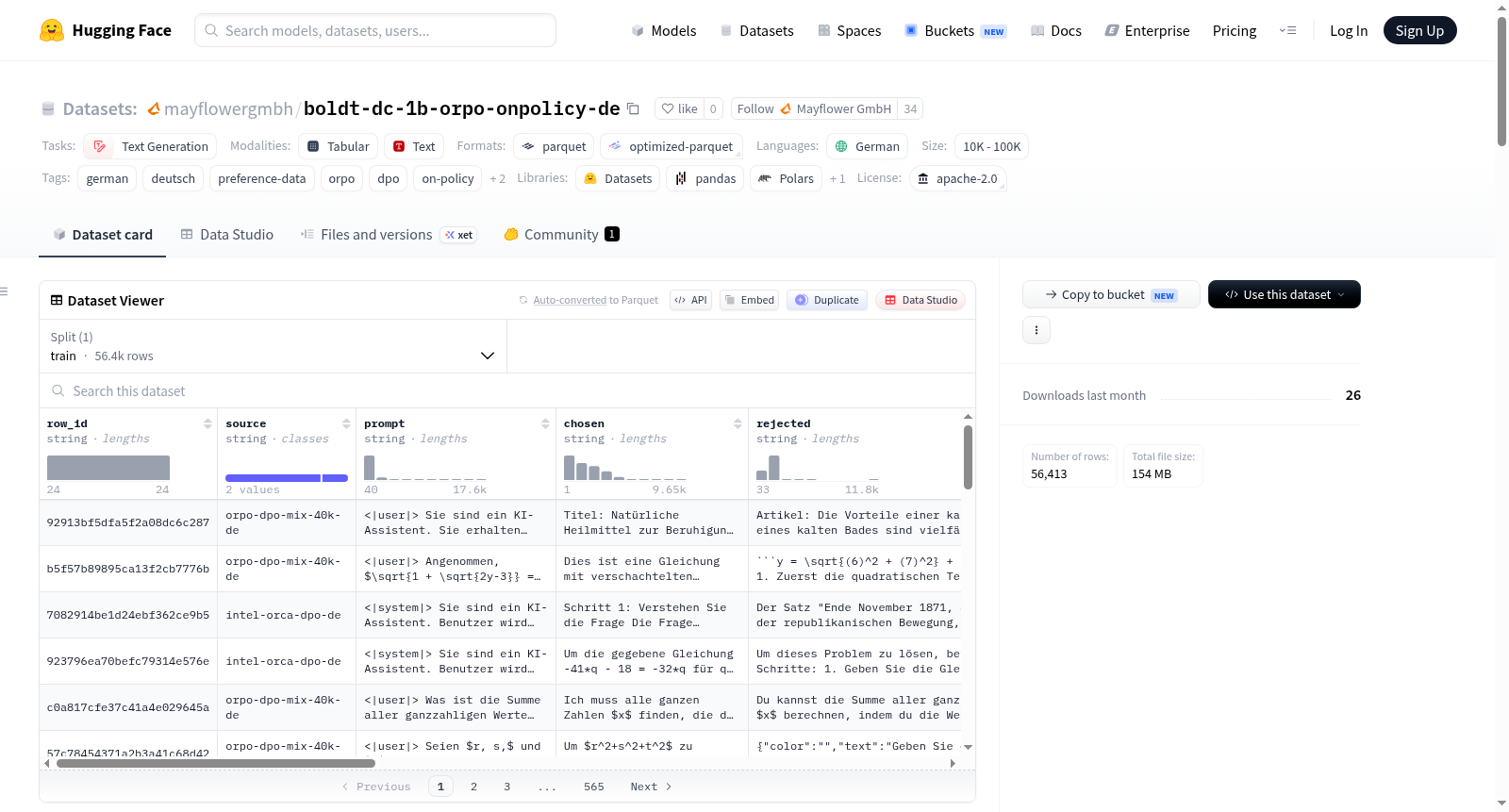
Boldt-DC-1B On-Policy ORPO (German) 是一个包含56,413个样本的德语偏好数据集,专门用于基于策略的在线对齐优化(如ORPO/DPO)训练。其核心创新在于rejected(被拒绝)响应由经过监督微调(SFT)的特定模型mayflowergmbh/boldt-dc-1b-german-it-16k在贪婪解码下生成,直接针对该模型的实际失败模式提供对比信号。数据集由两个德语偏好源数据集(orpo-dpo-mix-40k-de和intel-orca-dpo-de)合并并去重构建。每个样本包含15个字段,如完整对话历史提示(prompt,使用Boldt聊天令牌格式化)、优选助手响应(chosen)、SFT模型生成的贪婪延续响应(rejected)以及原始被拒响应(original_rejected)等。还提供元数据,包括token长度统计、生成参数(模型、引擎、种子、温度)和拒绝响应标记(is_refusal)。预期用途是用于boldt-dc-1b-german-it-16k模型及其相近后代的偏好对齐微调,以及分析该SFT模型的特定故障模式。但需注意,对比信号强度因样本而异,chosen响应质量依赖于源数据集,且重复或幻觉模式可能特定于12.5亿参数规模的Llama架构SFT模型行为。
Boldt-DC-1B On-Policy ORPO (German) is a German preference dataset with 56,413 samples, specifically designed for on-policy alignment optimization training such as ORPO/DPO. Its core innovation is that the rejected responses are not from a generic weak baseline but are generated by a specific supervised fine-tuned (SFT) model mayflowergmbh/boldt-dc-1b-german-it-16k under greedy decoding, providing contrastive signals directly targeting the models actual failure modes. The dataset is constructed by merging and deduplicating two German preference source datasets (orpo-dpo-mix-40k-de and intel-orca-dpo-de). Each sample includes 15 fields, such as the full conversational history prompt (prompt, formatted with Boldt chat tokens), the preferred assistant response (chosen) from the source dataset, the greedy continuation response generated by the specified SFT model (rejected), and the original rejected response for traceability (original_rejected). The dataset also provides detailed metadata, including token length statistics, generation parameters (model, engine, seed, temperature), and a flag indicating whether the response is a refusal (is_refusal). The intended use is for preference alignment fine-tuning of the boldt-dc-1b-german-it-16k model and its close descendants, as well as for analyzing specific failure modes of this SFT model. It should be noted that the strength of contrastive signals varies by sample, the quality of chosen responses depends on the source datasets, and observed repetition or hallucination patterns may be specific to the behavior of the 1.25B parameter Llama-architecture SFT model.
提供机构:
Mayflower GmbH
创建时间:
2026-05-17
搜集汇总
数据集介绍
构建方式
该数据集基于两个德国偏好数据集——`johannhartmann/orpo-dpo-mix-40k-llama3-de`与`mayflowergmbh/intel_orca_dpo_pairs_de`——进行融合与统一,构建了包含`prompt`、`chosen`和`original_rejected`字段的基础结构。随后,利用`mayflowergmbh/boldt-dc-1b-german-it-16k`监督微调模型,以贪婪解码方式为每个提示生成了`rejected`响应,该响应反映了模型自身的实时输出而非外部替代答案。生成过程在RTX A6000上以bf16精度批量执行,采用左填充与长度分桶策略,吞吐率达到约2.78提示/秒。最终,经过空响应、过短内容、提示截断等筛选步骤,保留了56,413条高质量偏好对。
特点
该数据集的显著特征在于其`on-policy`属性:`rejected`字段精准记录了目标模型在贪婪解码下的实际输出,使得每对偏好数据均呈现出模型当下失败模式与理想回应之间的具体差距,从而在ORPO或DPO训练中提供更为锐利的梯度信号。所有偏好对的`chosen`与`rejected`均不相等且无近语义重复,确保了训练信号的真实性。此外,数据集保留了原始来源的`original_rejected`字段以支持溯源分析,并内置了提示令牌长度、拒绝标记等元信息,便于研究人员进行细致诊断。
使用方法
该数据集可直接整合至TRL库的`ORPOTrainer`或`DPOTrainer`中,因`prompt`字段已内嵌Boldt对话令牌格式且以`<|assistant|>
`结尾,无需额外应用聊天模板。通过HuggingFace的`datasets`库调用`load_dataset`函数即可便捷加载,例如`load_dataset("mayflowergmbh/boldt-dc-1b-orpo-onpolicy-de", split="train")`。需注意,其`on-policy`特性仅针对生成`rejected`的基座模型,若用于训练不同模型,将退化为离线偏好数据。该数据集特别适用于`mayflowergmbh/boldt-dc-1b-german-it-16k`及其近缘模型的后训练阶段。
背景与挑战
背景概述
在大型语言模型的后训练对齐阶段,偏好数据集的构建质量直接决定了模型微调(如ORPO、DPO)的效果。然而,传统偏好数据集常采用离策略(off-policy)范式,即从固定基线模型中选取的“拒绝”回答未必反映当前模型的真实失效模式,导致梯度信号模糊。为克服这一局限,Mayflower GmbH于2026年发布了Boldt-DC-1B On-Policy ORPO(German),一个包含56,413条德语偏好的数据集。其核心创新在于,每条数据中的“拒绝”字段并非外部替代回答,而是专有模型mayflowergmbh/boldt-dc-1b-german-it-16k在贪心解码下的实际输出。该数据集聚焦于解决德语大模型的后训练对齐问题,通过保留模型自身的错误案例,为ORPO/DPO提供更锐利的对比信号,在德语自然语言处理社区中具有重要的基准价值。
当前挑战
该研究首先需应对领域核心问题——偏好数据集的“切题性”挑战。传统离策略数据中,“拒绝”回答与目标模型的行为脱节,削弱了偏好对比的指导意义。Boldt-DC-1B通过生成式采样,将模型实时输出作为“拒绝”样本,但这一策略又引发构建过程中的多重困难:其一,需确保提示格式精确匹配训练环境,防止因字节差异引入噪声;其二,生成耗时显著,在单张RTX A6000上以约2.78条/秒速率处理56,413条数据,需平衡效率与质量;其三,过滤环节须剔除空输出、短答案及冗余对,但保持合理的梯度多样性;此外,“拒绝”回答长度受限于384个token,可能无法揭示长文本中的完整失效模式,且“选择”回答继承自社区数据集,未经验证的准确性构成潜在风险。
常用场景
经典使用场景
该数据集专为德语大语言模型的对齐微调而设计,尤其适用于ORPO(Online Policy Optimization)或DPO(Direct Preference Optimization)等偏好学习范式。其核心价值在于提供了一种“在线策略”性质的偏好数据:每条样本中的rejected回答并非来自外部弱基线模型,而是直接由目标模型(如mayflowergmbh/boldt-dc-1b-german-it-16k)在贪婪解码下自身生成的输出。这种设计使得模型在训练过程中能够直面自己当前的失败模式,从而获得更为锐利和精确的梯度信号,有效加速对齐进程。研究者可直接将数据接入TRL库中的ORPOTrainer或DPOTrainer,省去繁琐的聊天模板格式化步骤,实现快速迭代实验。
衍生相关工作
该数据集及其构建思路已衍生出多项关键技术工作:其生成脚本(scripts/16_build_orpo_onpolicy_de.py)与报告体系(如reports/orpo_on_policy_build.json)为后续研究者提供了可复现的在线偏好数据构建管道;基于本数据训练的ORPO模型常被作为基线,用于对比不同偏好算法(如IPO、SimPO)在小参数德语模型上的效果;其提出的“在线拒绝采样+清洗过滤”流程(如5-gram Jaccard去重、长度截断策略)已被其他语种(如法语、西班牙语)的类似数据集采纳。此外,该数据集催生了对“离线策略vs在线策略”在低资源语言对齐中效果的对比分析,成为德语LLM领域偏好优化研究的重要参考基准。
数据集最近研究
最新研究方向
在德语大语言模型对齐研究领域,该数据集代表了基于策略的偏好优化方法的前沿探索。它通过让模型自身生成被拒绝的回答,实现了真正的在线策略学习,从而精准捕获模型当前的薄弱环节并提供强烈的梯度信号。这种自我对抗的训练范式不仅显著提升了ORPO/DPO等对齐技术的效率,还为分析1.25B参数规模德语模型的重复与幻觉模式提供了珍贵诊断数据。其构建过程中严格的去重与质量控制,确保了每一条偏好对都蕴含实质性的对比信号,为德语开源社区的大模型对齐研究树立了新的方法论标杆。
以上内容由遇见数据集搜集并总结生成


