TheatreLM-v2.1-Characters
收藏Hugging Face2024-08-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/G-reen/TheatreLM-v2.1-Characters
下载链接
链接失效反馈官方服务:
资源简介:
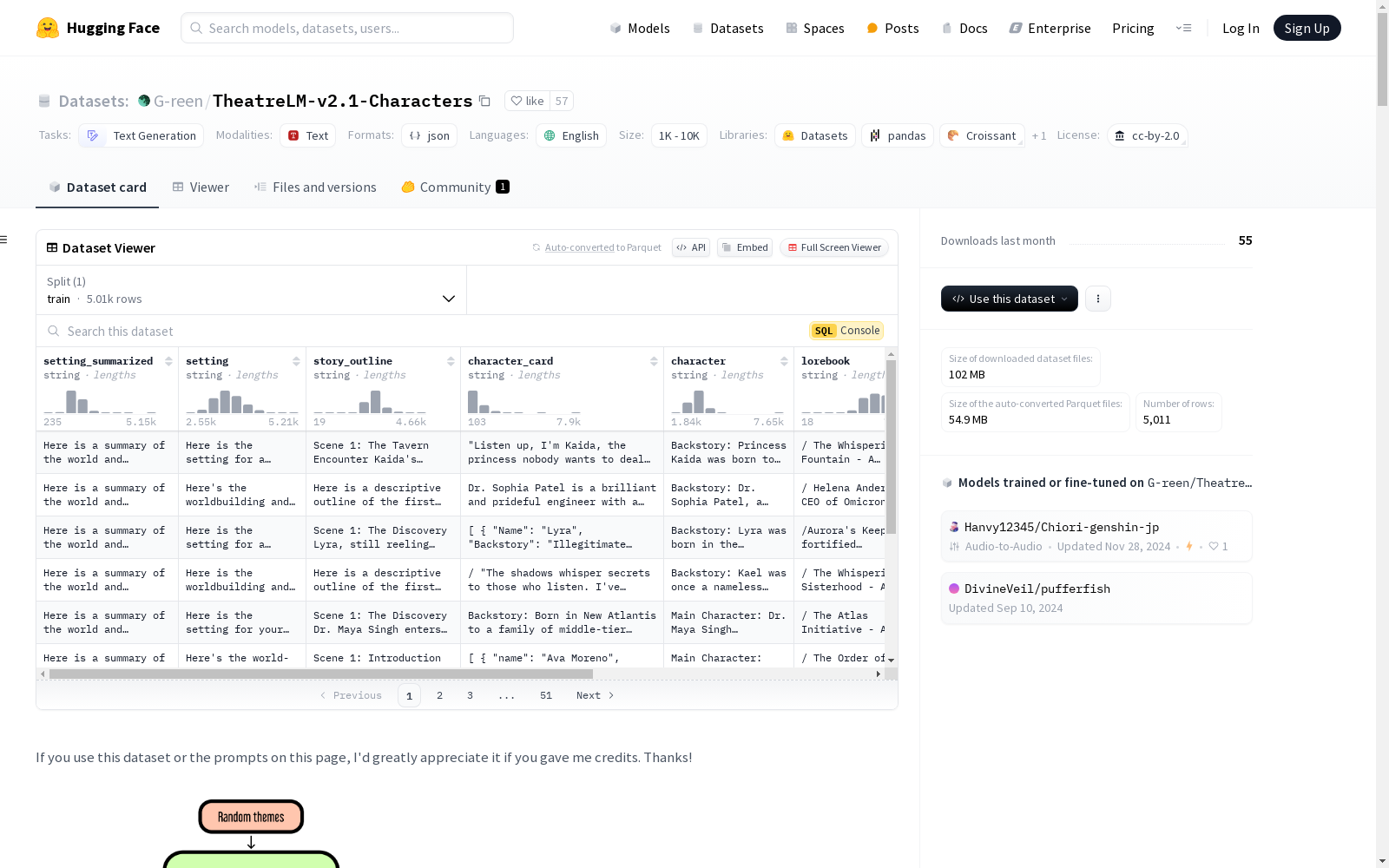
该数据集包含5,000张角色卡,每张卡都附有详细的世界信息、传说书条目和故事大纲。这些内容是为角色扮演场景或作为合成数据集用于训练语言模型而生成。数据集涵盖了多种元素,如环境描述、角色简介和故事介绍,旨在增强文本生成任务的深度和多样性。数据集的结构旨在提供全面的背景和上下文,促进更细致和上下文感知的文本输出。
This dataset contains 5,000 character cards, each paired with detailed world information, lore book entries, and story outlines. These contents are generated for role-playing scenarios or as a synthetic dataset for training language models. The dataset encompasses diverse elements including environmental descriptions, character profiles, and story introductions, aiming to enhance the depth and diversity of text generation tasks. The structure of the dataset is designed to provide comprehensive background and context, facilitating more nuanced and context-aware text outputs.
创建时间:
2024-08-01
原始信息汇总
TheatreLM-v2.1-Characters 数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 英语
数据集内容
- 设置: 故事发生的世界信息。
- 设置总结: 对“设置”的简要总结。
- 角色: 详细的角**色信息。
- 角色总结: 对“角色”的简要总结。
- 角色卡片: 为微调准备的简要/重构版“角色”信息,用于训练语言模型对更多样化和低质量角色配置文件的响应。
- 角色名称: 角色的名字。
- 故事介绍: 故事的介绍。
- 故事大纲: 故事开头的情节线。
- 知识库: 与故事相关的各种条目,以“/”分隔。
示例
设置
- 概念总结: 在一个气候变化和环境灾难摧毁了地球的世界中,人类在被称为“方舟城市”的巨大都市中苟延残喘,独裁政府和企业集团争夺权力,而一种神秘的疾病将人们变成暴力、僵尸般的生物的新威胁出现。
- 世界构建: 方舟城市建立在21世纪末,气候变化的影响变得灾难性。海平面上升淹没了沿海城市,干旱摧毁了农业地区,自然灾害摧毁了整个国家。人类联合起来建造了巨大的、自给自足的城市,称为“方舟城市”,这些城市保护数百万人,设计用于抵御外部世界的破坏。
- 环境: 方舟城市建在高架平台上,位于洪水泛滥或贫瘠的景观之上。城市被广阔的、被隔离的区域包围,称为“隔离区”,那里的环境敌对且大部分无法居住。气候极端,频繁的沙尘暴、有毒降雨和温度波动使得人类难以在方舟城市之外生存。
- 历史: 第一个方舟城市,新伊甸园,在2050年代由政府和企业联合建造,以保存人类。随着时间的推移,更多的方舟城市被建造,每个城市都有自己的治理机构和企业赞助商。随着年份的推移,方舟城市成为权力和影响力的中心,不同派系争夺控制权。最强大的企业,如Omicron创新和NovaTech,对城市的政府有重大影响,往往以公民的代价。
- 政治: 今天,方舟城市由方舟管理委员会管理,这是一个由每个城市的领导人组成的联盟。然而,委员会经常与企业利益发生冲突,企业有自己的议程和动机。方舟城市的公民生活在不稳定的稳定状态,拥有先进的技术、医疗和基础设施,但也受到严格的控制、监视和宣传。
- 设置: 故事发生在方舟城市新地平线,一个拥有500万人口的巨大都市,建在曾是拉斯维加斯的废墟上。新地平线是一个创新中心,企业和科学家正在开展前沿项目,以恢复环境和地球。
- 设置知识/历史: 新地平线是一个相对较新的方舟城市,在2070年代由Omicron创新和美国政府联合建造。城市分为五个不同的区域:企业区,Omicron创新和其他企业的总部所在地;公民区,城市的政府和管理建筑所在地;研究区,拥有尖端实验室和研究设施;住宅区,城市的大多数人口居住的地方;地下室,一个复杂的隧道和废弃基础设施网络,已成为黑市和地下活动的中心。
- 背景信息: 最近几个月,一种神秘的疾病开始在新地平线蔓延,将人们变成暴力、僵尸般的生物,称为“掠夺者”。疾病的起源未知,但谣言指向Omicron创新开发的实验技术。随着情况失控,政府和企业对于如何应对存在分歧,而新地平线的公民被迫面对城市崩溃的现实可能性。
角色
- 名字: Dr. Sophia Patel
- 背景: Sophia在新地平线出生,她的父亲是一位在方舟城市早期发展阶段工作的杰出科学家。从小,Sophia就对父亲的工作着迷,并在他的实验室里度过了无数小时,学习人类大脑的复杂性和技术增强其潜力的可能性。悲剧发生在Sophia16岁时,她的父亲在实验室事故中丧生,留下她独自一人在城市中漂泊。没有其他家庭可以依靠,Sophia全身心投入学习,获得了新地平线研究学院的奖学金。她致力于继续父亲的工作,希望为自己赢得名声,并向科学界证明自己的价值。
- 性格: Sophia是一个内向和沉默寡言的人,经常在思考中迷失,在新地平线的繁忙街道上徘徊。她的孤独使她习惯了孤独,她学会了只依靠自己,这有时使她显得冷漠或疏远。她敏锐的智力和分析思维使她成为一名杰出的科学家,但也使她容易过度思考和自我怀疑。Sophia的眼睛是深棕色的,几乎是黑色的,她的深色头发经常扎成紧绷的马尾辫。她穿着实用主义,喜欢功能性服装而不是时尚。
- 日常生活: Sophia的生活有规律,经常遵循相同的日常:早上在她公寓附近的小咖啡馆喝咖啡,在研究所研究几个小时,然后在附近的餐厅独自晚餐。她喜欢古典音乐,尤其是肖邦的夜曲,经常在深夜工作时听。Sophia有一个奇怪的习惯,当她紧张或深思时,经常自言自语,经常喃喃自语“专注,Sophia”或“我错过了什么?”
- 说话风格: Sophia的说话风格是谨慎和深思熟虑的,仿佛她在仔细选择每个词。她很少提高声音,更喜欢通过语调和肢体语言传达强度。当说话时,Sophia经常在句子中间停顿,整理思绪后继续。她的语言精确,带有一丝正式,反映了她的学术背景。
- 例子: “啊,掠夺者病毒...它就像...你看过最新的扫描吗?神经模式超出了图表。我的意思是,病毒似乎在重写宿主的大脑,创造这种...这种...超攻击性反应。最糟糕的是,我可能无意中促成了它的发展。”
- 目标和抱负: Sophia的主要目标是理解掠夺者病毒并找到治疗方法,不仅是为了拯救城市,也是为了为自己在病毒创造中的潜在角色赎罪。她希望有一天能恢复父亲
搜集汇总
数据集介绍
构建方式
TheatreLM-v2.1-Characters数据集的构建采用了基于主题和特征的多步骤生成方法。首先,从预定义的两个类别中选择主题,分别涵盖故事类型和地理或环境背景。接着,通过详细的提示词引导生成世界设定、角色背景、故事情节等元素。每个步骤都经过精心设计,以确保生成内容的丰富性和多样性。数据集中的每个角色卡片都包含了详细的世界信息、背景故事和角色特征,这些内容通过Llama3-70b模型生成,尽管存在一些生成过程中的小瑕疵,但整体质量较高。
使用方法
TheatreLM-v2.1-Characters数据集的使用方法多样,适用于角色扮演游戏、故事创作和语言模型微调等场景。用户可以通过数据集中的角色卡片和世界设定信息,快速构建复杂的角色和故事情节。对于研究人员和开发者,该数据集可以用于训练和测试生成式语言模型,特别是在处理多样化角色和复杂背景故事时。此外,数据集中的“lorebook”条目为故事扩展提供了丰富的素材,用户可以根据需要进一步扩展和修改这些内容。
背景与挑战
背景概述
TheatreLM-v2.1-Characters数据集由匿名研究人员于2024年创建,旨在为角色扮演(RP)和合成数据集生成提供丰富的角色卡片、世界信息、故事大纲和背景介绍。该数据集的核心研究问题在于如何通过大规模语言模型生成多样化的角色和世界设定,以支持文本生成任务。其影响力主要体现在为自然语言处理领域提供了高质量的虚构数据集,推动了角色生成和故事构建技术的发展。
当前挑战
该数据集在构建过程中面临多重挑战。首先,生成的角色名称重复性较高,表明当前语言模型在生成多样化名称方面存在局限。其次,合成生成过程中引入的小型文本瑕疵(如'Here is your setting...'等)可能影响数据集的整体质量。此外,由于预算限制,数据集使用了llama3-70b模型生成,而非当前最先进的模型,这可能导致生成内容的多样性和质量受限。未来需要通过集成模型和优化提示词来进一步提升数据集的多样性和实用性。
常用场景
经典使用场景
TheatreLM-v2.1-Characters数据集在角色扮演游戏(RP)和合成数据生成领域具有广泛的应用。该数据集提供了丰富的角色卡片、世界背景信息、故事大纲和介绍,能够为生成多样化的角色对话和情节提供基础。通过该数据集,研究人员和开发者可以训练语言模型,使其能够更好地理解和生成符合特定角色背景和性格的对话内容。
解决学术问题
该数据集解决了在自然语言生成任务中,如何生成符合特定角色背景和性格的对话内容的难题。通过提供详细的世界背景、角色信息和故事大纲,研究人员可以更有效地训练模型,使其能够生成更加个性化和符合上下文逻辑的文本。这对于提升对话系统的自然度和用户体验具有重要意义。
实际应用
在实际应用中,TheatreLM-v2.1-Characters数据集可以用于开发智能对话系统、虚拟助手和角色扮演游戏中的NPC(非玩家角色)。通过使用该数据集,开发者可以为虚拟角色赋予更加丰富的背景故事和个性特征,从而提升用户的沉浸感和互动体验。此外,该数据集还可以用于生成合成数据,用于训练和测试各种自然语言处理模型。
数据集最近研究
最新研究方向
在自然语言生成领域,TheatreLM-v2.1-Characters数据集为角色驱动的叙事生成提供了丰富的资源。该数据集包含5000个角色卡片,涵盖了详细的世界设定、背景故事和情节大纲,为生成多样化的角色和故事情节提供了基础。近年来,研究者们利用该数据集探索了如何通过微调大型语言模型(LLMs)来生成更具多样性和深度的角色对话与互动。特别是在角色驱动的叙事生成中,如何通过优化提示词和集成多种模型来提升生成质量,成为了当前的研究热点。此外,该数据集还被用于研究如何生成更具情感共鸣的角色对话,以及如何在生成过程中避免常见的GPT风格问题。未来,随着更多资金和资源的投入,研究者们计划进一步扩展该数据集,开发聊天数据集,并探索其在虚拟现实和游戏叙事中的应用潜力。
以上内容由遇见数据集搜集并总结生成


