eve-esa/hallucination-detection
收藏Hugging Face2026-04-16 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/eve-esa/hallucination-detection
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: Question
dtype: string
- name: Answer
dtype: string
- name: Soft labels
list:
- name: end
dtype: int64
- name: prob
dtype: float64
- name: start
dtype: int64
- name: text
dtype: string
- name: Hard labels
list:
list: int64
- name: is_hallucinated
dtype: bool
splits:
- name: train
num_bytes: 2645275
num_examples: 2326
download_size: 1439964
dataset_size: 2645275
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- text-classification
tags:
- earth-observation
- hallucination-detection
- earth-intelligence
---
# Dataset Summary
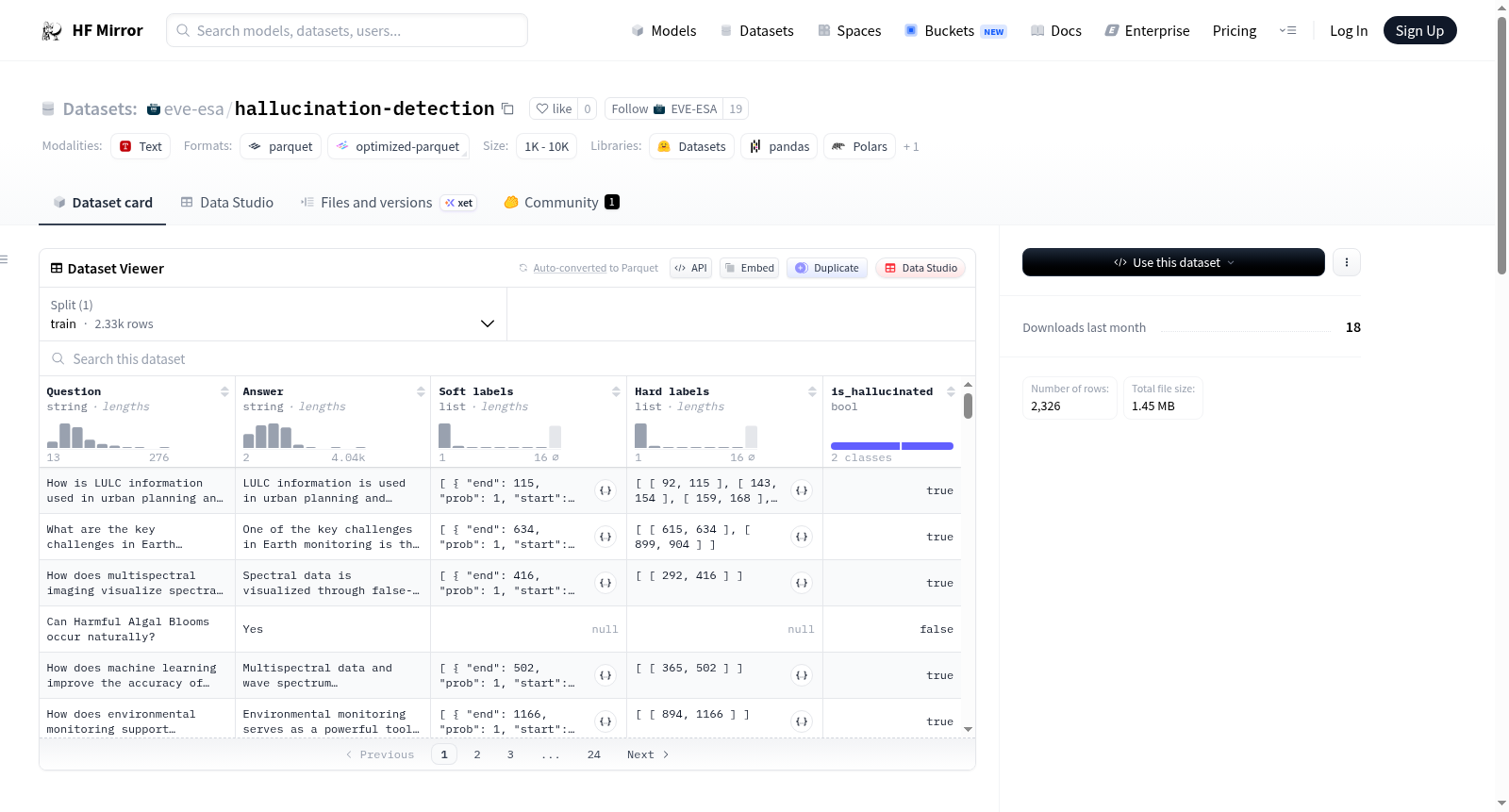
Hallucination Detection dataset is a specialized dataset designed to evaluate language models' tendency to hallucinate (generate factually incorrect or unsupported information) in the Earth Observation (EO) domain. Unlike typical QA datasets that focus on correctness, this dataset contains deliberately hallucinated answers with detailed annotations marking which portions of the text are hallucinated.
This dataset was introduced as part of the paper [EVE: A Domain-Specific LLM Framework for Earth Intelligence](https://huggingface.co/papers/2604.13071).
- **GitHub Repository**: [https://github.com/eve-esa](https://github.com/eve-esa)
This dataset is crucial for developing and evaluating hallucination detection systems, training models to identify unreliable content, and measuring the reliability of language models in critical EO applications where factual accuracy is paramount.
# Dataset Structure
Each example in the dataset contains:
- **Question**: A question related to Earth Observation
- **Answer**: A model-generated or synthetic answer that contains hallucinated information
- **Soft Labels**: A list of text spans each containing:
- **start_char**: Starting character index of the hallucinated span
- **end_char**: Ending character index of the hallucinated span
- **prob** : probabillity for the hallucinated span
- **text**: The actual text content of the hallucinated span
- **Hard Labels**: A list of list containing:
- **start_char**: Starting character index of the hallucinated span
- **end_char**: Ending character index of the hallucinated span
- **Is_hallucinatred**: If the span has been hallucinated or not.
**Note on Span Format**: All spans are expressed as character indices (not word or token indices). For example, if the answer is "Sentinel-2 has a resolution of 5 meters" and "5 meters" is hallucinated, the span would be `[34, 42]` representing character positions in the string.
# Benchmark Results
We provide baseline results for **hallucination detection** using our [EVE-Instruct](https://huggingface.co/eve-esa/EVE-Instruct) model.
For the benchmark scores, you can find them here [EVE-Instruct](https://huggingface.co/eve-esa/EVE-Instruct).
## Task
**Hallucination Detection**
Given a `(Question, Answer)` pair, the model predicts if the answer is hallucinated or not.
## Metric
For each example, we calculate the **F1 score**.
## Results
| Model | F1 Score |
|-------|---------|
| EVE-Instruct | **84.70** |
# Citation
If you use this project in academic or research settings, please cite:
```
@misc{atrio2026evedomainspecificllmframework,
title={{EVE}: A Domain-Specific {LLM} Framework for Earth Intelligence},
author={Àlex R. Atrio and Antonio Lopez and Jino Rohit and Yassine El Ouahidi and Marcello Politi and Vijayasri Iyer and Umar Jamil and Sébastien Bratières and Nicolas Longépé},
year={2026},
eprint={2604.13071},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2604.13071},
}
```
提供机构:
eve-esa
搜集汇总
数据集介绍
构建方式
该数据集聚焦于地球观测领域,针对语言模型生成内容中可能出现的幻觉现象,构建了一套专门用于检测的问答对集合。其构建过程涉及精心设计包含事实性错误或缺乏依据的答案,并通过人工或自动化标注方式,对答案文本中的幻觉片段进行精确的字符级定位与标记,形成了包含软标签与硬标签的详细注释体系。
特点
该数据集的核心特征在于其针对性与精细的标注粒度。它不仅提供了问题与包含幻觉的答案对,更通过软标签标注了幻觉片段的起止字符位置、具体文本内容及概率估计,同时以硬标签形式提供了明确的幻觉区间界定。这种双重标注机制为模型训练与评估提供了多层次的监督信号,尤其适用于对事实准确性要求极高的地球观测等关键应用场景。
使用方法
在使用该数据集时,研究者可将其直接应用于幻觉检测模型的训练与评估任务。典型流程是输入问题-答案对,模型需要预测答案是否包含幻觉,或进一步定位幻觉的具体文本区间。数据集提供的字符级标注可直接用于训练序列标注或片段分类模型,其基准结果也可作为模型性能的参照标准,推动该领域检测技术的迭代与优化。
背景与挑战
背景概述
幻觉检测数据集是专为评估语言模型在地球观测领域产生幻觉倾向而设计的专项数据集,其核心研究问题聚焦于识别模型生成的事实性错误或缺乏依据的信息。该数据集由相关研究机构于近期构建,旨在通过标注含有故意幻觉的答案,推动语言模型在关键应用中的可靠性评估。作为地球观测与自然语言处理交叉领域的重要资源,它不仅促进了幻觉检测系统的开发,也为提升模型在要求高事实准确性场景下的性能提供了基准支持,对增强人工智能的可信度具有显著影响力。
当前挑战
该数据集旨在解决地球观测领域问答任务中语言模型产生事实性幻觉的挑战,具体包括准确识别并定位文本中的错误或未经验证的内容片段。在构建过程中,挑战主要源于幻觉内容的模拟与标注:需要生成既符合领域语境又包含细微错误的答案,同时确保字符级跨度标注的精确性与一致性,以支持可靠的模型训练与评估。这些挑战要求数据集在保持事实复杂性的基础上,提供细致且可扩展的注释框架。
常用场景
经典使用场景
在地球观测领域,大型语言模型常因知识局限或训练偏差产生事实性错误,即幻觉现象。该数据集通过提供包含人工标注幻觉文本片段的问题-答案对,为幻觉检测任务构建了标准化的评估基准。研究人员利用其精细的字符级标注,训练模型精准识别答案中虚构或未经证实的陈述,从而系统评估模型在专业领域的可靠性。
实际应用
在遥感数据解读、环境监测报告生成等地球观测实际任务中,幻觉检测至关重要。该数据集支撑开发的检测系统可集成于卫星数据分析管线,自动筛查自动生成报告中的事实错误,辅助专家进行质量把控。此外,在科普教育或决策支持系统中,它能有效过滤误导性信息,提升领域专用语言模型输出的实用性与安全性。
衍生相关工作
基于该数据集构建的基准催生了多项经典研究,例如EVE-Instruct模型通过微调实现了高效的幻觉检测。相关工作进一步拓展至多模态地球观测数据的幻觉分析,以及将检测机制融入模型训练流程以降低幻觉产生的预训练方法。这些衍生工作共同深化了对语言模型可信生成机制的理解,并形成了从检测到缓解的完整技术链条。
以上内容由遇见数据集搜集并总结生成


