SGI-DeepResearch
收藏Hugging Face2025-12-10 更新2025-12-11 收录
下载链接:
https://huggingface.co/datasets/InternScience/SGI-DeepResearch
下载链接
链接失效反馈官方服务:
资源简介:
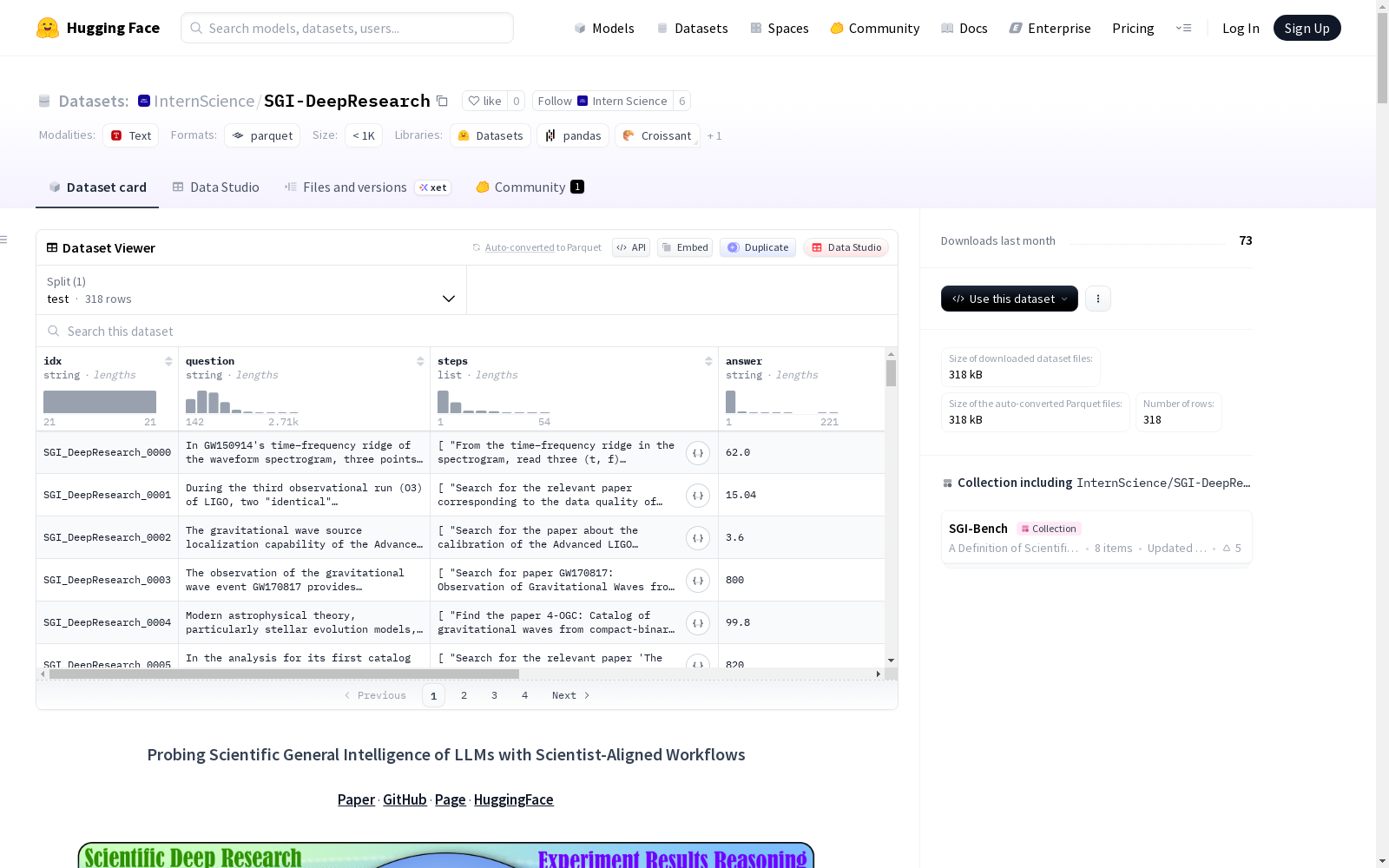
该数据集名为'用科学家对齐的工作流程探究LLMs的科学通用智能',是一个用于评估科学通用智能(SGI)的基准,涵盖完整的探究周期:深思熟虑、构思、行动和感知。数据集跨越10个学科,包含1000多个由专家策划的样本,灵感来源于《科学》杂志的125个重大问题。数据集具有高保真度,任务真实且具有挑战性,广泛代表性强。数据集特征包括idx、question、steps、answer、discipline、direction和type。
创建时间:
2025-12-03
原始信息汇总
数据集概述:SGI-DeepResearch
数据集基本信息
- 数据集名称:SGI-DeepResearch
- 发布机构/作者:InternScience
- 数据集地址:https://huggingface.co/datasets/InternScience/SGI-DeepResearch
- 数据集简介:该数据集是SGI-Bench(科学通用智能基准)的一部分,专注于评估大语言模型在“深度研究”任务上的表现。该基准旨在评估模型在完整科学探究循环(审议、构思、行动、感知)中的科学家对齐能力。
数据集结构与内容
- 数据格式:包含以下字段的结构化数据:
idx:字符串类型,样本索引。question:字符串类型,问题描述。steps:字符串列表,研究步骤。answer:字符串类型,答案。discipline:字符串类型,所属学科。direction:字符串类型,研究方向。type:字符串类型,问题类型。
- 数据规模:
- 总样本数:318
- 数据集大小:575,572 字节
- 下载大小:318,459 字节
- 数据划分:仅包含一个“test”测试集。
数据集背景与目标
- 核心概念:科学通用智能(Scientific General Intelligence, SGI),指能够像人类科学家一样,自主、熟练地导航完整、迭代的科学探究循环(审议、构思、行动、感知)的AI系统。
- 任务定位:本数据集对应SGI-Bench框架中的“审议”阶段,具体任务是“深度研究”,涉及多跳检索、综合和元分析风格的推理。
数据构建与特点
- 构建基础:数据构建受《科学》杂志125个重大问题的启发。
- 覆盖范围:涵盖10个学科领域。
- 构建流程:由100多名研究生/博士生标注,并经过持续的专家参与式审查。数据经过规则清理、模型检查和专家质量保证,以确保可执行性和答案的唯一性。
- 难度控制:通过过滤掉超过50%的强语言模型能够解决的样本,以保持高挑战性。
评估框架
- 评估方式:采用智能体评估框架,包含问题选择、指标定制、预测与评估、报告生成四个阶段。
- 工具支持:可使用网络搜索、PDF解析器、Python解释器、文件阅读器、指标函数等工具。
- 任务指标:对于深度研究任务,主要使用精确匹配(EM)和松弛标签匹配(SLA)等指标。
相关资源
- 论文:https://internscience.github.io/SGI-Page/paper.pdf
- 项目主页:https://internscience.github.io/SGI-Page/
- GitHub代码库:https://github.com/InternScience/SGI-Bench
- HuggingFace集合:https://huggingface.co/collections/InternScience/sgi-bench
搜集汇总
数据集介绍
构建方式
在科学智能评估领域,SGI-DeepResearch数据集的构建体现了严谨的专家驱动范式。其原始语料源自《科学》杂志提出的125个重大科学问题,覆盖了十个核心学科领域。构建过程由超过百名研究生与博士作为标注者,在持续的专家循环评审监督下,完成问题的设计与构造。为确保数据的高质量与可执行性,后续通过规则过滤、模型校验与专家质量评估相结合的方式进行数据清洗,并移除了被超过半数主流大语言模型轻易解决的样本,从而保证了数据集的挑战性与科学性。
特点
该数据集的核心特征在于其与科学家工作流的高度对齐性,旨在评估模型贯穿完整科学探究周期的通用智能。数据集将科学探究解构为深思、构思、行动与感知四个阶段,并具体化为深度研究、想法生成、干湿实验与多模态推理等任务族。其样本不仅具有高度的学科代表性与真实性,更通过精心设计的难度筛选机制,维持了相当的挑战门槛,能够有效区分不同模型在复杂科学推理与执行层面的能力差异。
使用方法
使用SGI-DeepResearch数据集进行评估,需遵循其提供的代理化评估框架。评估流程被结构化为问题选择、指标定制、预测与评分、报告生成四个可追溯的阶段。用户需配置相应的工具环境,如网络搜索、Python解释器等,并针对不同任务类型运行指定的脚本序列。例如,对于深度研究任务,需依次执行答案生成与评分脚本。该框架支持自定义科学家对齐的评估指标,增强了评估的可复现性,并能产出具有行动指导意义的深度分析报告。
背景与挑战
背景概述
在人工智能与科学发现交叉领域,评估模型是否具备类似科学家的系统性探究能力,即科学通用智能,成为一个前沿核心问题。SGI-DeepResearch数据集由InternScience团队于近期构建,其灵感源自《科学》杂志提出的125个重大科学问题,旨在通过一个与科学家工作流对齐的基准,全面评估大语言模型在深度研究、思想生成、实验设计与多模态推理等完整科学探究周期中的表现。该数据集覆盖十个学科,包含逾千个由专家精心策划的样本,其构建过程采用了持续性的专家参与式审核与高难度过滤机制,确保了任务的真实性与挑战性,为推进AI驱动的自主科学研究提供了关键的评估工具与理论框架。
当前挑战
该数据集旨在解决的领域挑战在于,如何系统性地评估AI模型在复杂、开放式的科学探究全周期中的综合能力,这超越了传统的单一任务评测,要求模型整合知识检索、创造性思维、行动规划与感知解释。在构建过程中,挑战主要集中于确保数据的高保真度与可执行性,这需要协调百余位研究生与博士注释者,并依赖专家进行持续的质量控制;同时,为维持基准的高难度,需设计有效策略以过滤那些能够被当前主流大语言模型轻易解决的样本,从而保证评测能够有效区分不同模型的科学智能水平。
常用场景
经典使用场景
在人工智能与科学交叉的前沿领域,SGI-DeepResearch数据集为评估大语言模型的科学通用智能提供了基准框架。该数据集的核心应用场景在于系统性地测评模型在完整科学探究循环中的表现,尤其侧重于“深度研究”这一环节。研究者利用其多跳检索、综合分析与元分析式推理任务,能够精确衡量模型在复杂科学问题上的信息整合与逻辑推演能力,从而揭示模型是否具备类似科学家的系统性思维模式。
衍生相关工作
围绕SGI-DeepResearch数据集,已催生了一系列聚焦于提升AI科学推理能力的研究。其提出的智能体评估框架启发了后续工作对评估过程可复现性与偏差控制的改进。同时,数据集内集成的测试时强化学习方法,为优化开放域科学构思任务中的新颖性指标提供了新颖范式。这些衍生工作共同推动了面向复杂科学工作流的AI评估与训练方法学的发展,为构建下一代科学AI奠定了方法论基础。
数据集最近研究
最新研究方向
在科学通用智能评估领域,SGI-DeepResearch数据集正推动前沿研究聚焦于智能体驱动的完整科学探究循环评估。该数据集以《科学》杂志125个重大问题为灵感,构建了涵盖十个学科的专家级任务,其核心在于模拟科学家从深思、构思、行动到感知的迭代工作流程。当前研究热点集中于无真实标注条件下的测试时强化学习,通过在线检索动态基线优化生成内容的新颖性,将开放式科学构思转化为可测量的优化目标。这一方向不仅提升了大型语言模型在复杂科学推理中的自主性,也为多目标奖励设计如严谨性、可行性与安全性评估开辟了新路径,标志着人工智能从被动知识处理向主动科学发现能力演进的关键一步。
以上内容由遇见数据集搜集并总结生成


