有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
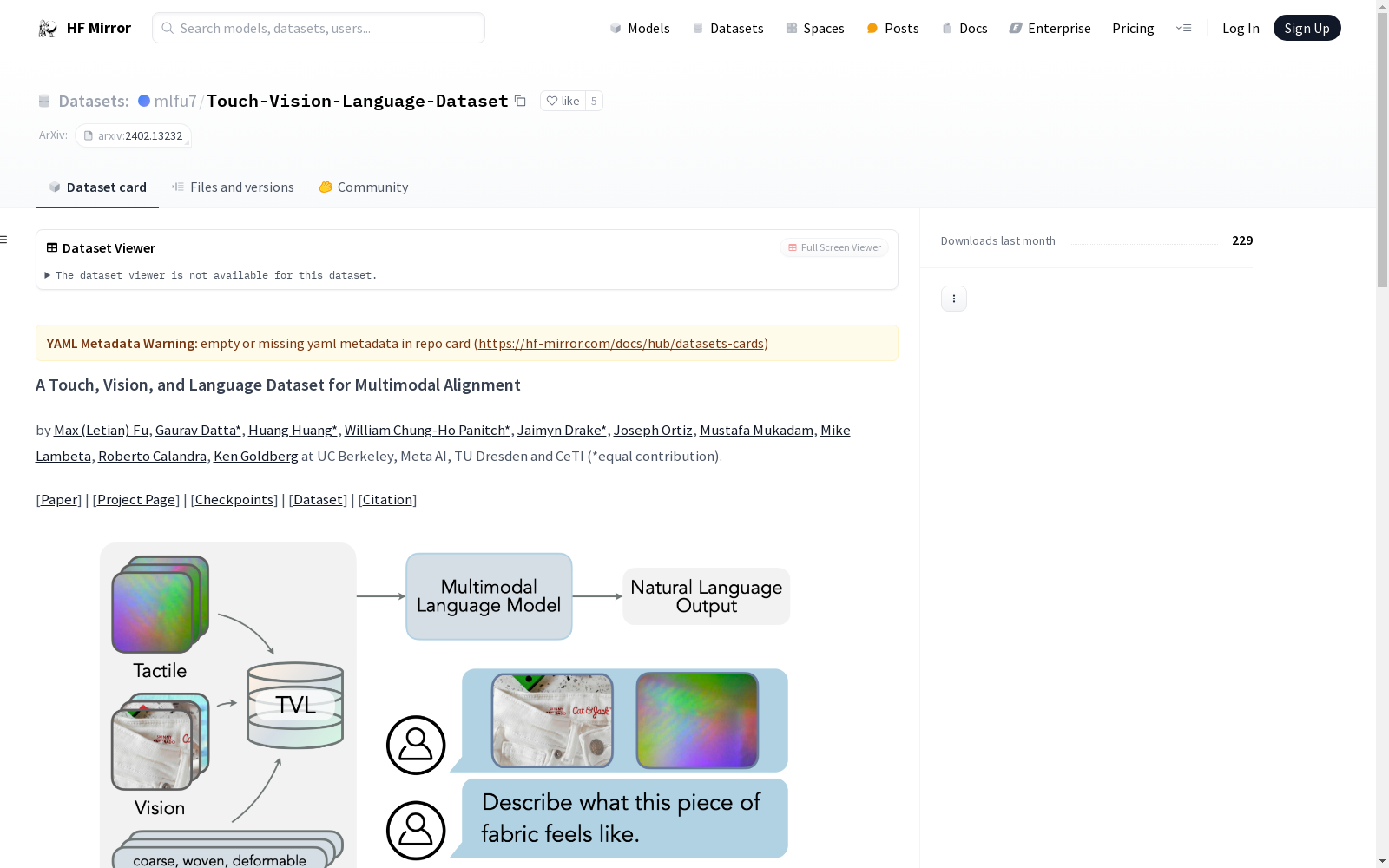
该数据集名为“A Touch, Vision, and Language Dataset for Multimodal Alignment”,用于多模态对齐研究。数据集被分片为8个zip文件,使用时需先下载并解压。
bash
git clone git@hf.co:datasets/mlfu7/Touch-Vision-Language-Dataset cd Touch-Vision-Language-Dataset zip -s0 tvl_dataset_sharded.zip --out tvl_dataset.zip unzip tvl_dataset.zip
tvl_dataset ├── hct │ ├── data1 │ │ ├── contact.json │ │ ├── not_contact.json │ │ ├── train.csv │ │ ├── test.csv │ │ ├── finetune.json │ │ └── 0-1702507215.615537 │ │ ├── tactile │ │ │ └── 165-0.025303125381469727.jpg │ │ └── vision │ │ └── 165-0.025303125381469727.jpg │ ├── data2 │ │ ... │ └── data3 │ ... └── ssvtp ├── train.csv ├── test.csv ├── finetune.json ├── images_tac │ ├── image_0_tac.jpg │ ... ├── images_rgb │ ├── image_0_rgb.jpg │ ... └── text ├── labels_0.txt ...
提供了TVL触觉编码器和TVL-LLaMA的检查点,详细信息请参考官方代码发布和论文。
如果使用该数据集,请引用以下论文:
@article{fu2024tvl, title={A Touch, Vision, and Language Dataset for Multimodal Alignment}, author={Letian Fu and Gaurav Datta and Huang Huang and William Chung-Ho Panitch and Jaimyn Drake and Joseph Ortiz and Mustafa Mukadam and Mike Lambeta and Roberto Calandra and Ken Goldberg}, journal={arXiv preprint arXiv:2402.13232}, year={2024} }
学生课堂行为数据集 (SCB-dataset3)
学生课堂行为数据集(SCB-dataset3)由成都东软学院创建,包含5686张图像和45578个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和趴桌。数据集覆盖从幼儿园到大学的不同场景,通过YOLOv5、YOLOv7和YOLOv8算法评估,平均精度达到80.3%。该数据集旨在为学生行为检测研究提供坚实基础,解决教育领域中学生行为数据集的缺乏问题。
arXiv 收录
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
URPC系列数据集, S-URPC2019, UDD
URPC系列数据集包括URPC2017至URPC2020DL,主要用于水下目标的检测和分类。S-URPC2019专注于水下环境的特定检测任务。UDD数据集信息未在README中详细描述。
github 收录
中国行政区划数据
本项目为中国行政区划数据,包括省级、地级、县级、乡级和村级五级行政区划数据。数据来源于国家统计局,存储格式为sqlite3 db文件,支持直接使用数据库连接工具打开。
github 收录
用于陆面模拟的中国土壤数据集(第二版)
本研究对中国范围内0-2米六个标准深度层(0-5、5-15、15-30、30-60、60-100和100-200厘米)的23种土壤物理和化学属性进行了90米空间分辨率的制图。该数据集源自第二次土壤普查的8979个土壤剖面,世界土壤信息服务的1540个土壤剖面,第一次全国土壤普查的76个土壤剖面,以及区域数据库的614个土壤剖面。该数据集包括pH值、砂粒、粉粒、粘粒、容重、有机碳含量、砾石、碱解氮、总氮、阳离子交换量、孔隙度、总钾、总磷、有效钾、有效磷和土壤颜色(包括蒙赛尔颜色和RGB两种形式)。数据集的缺失值为“fillvalue = -32768”。数据集以栅格格式提供,有Tiff和netCDF两种格式。为了满足陆面建模中不同应用对空间分辨率的不同要求,CSDLv2 提供了 90 米、1 公里和 10公里空间分辨率的版本。各个土壤属性的单位参见说明文档。该数据集相对于第一版具有更好的数据质量,可广泛应用于陆面过程模拟等地学相关研究。
国家青藏高原科学数据中心 收录