ragas-golden-dataset-v2
收藏Hugging Face2025-05-20 更新2025-05-21 收录
下载链接:
https://huggingface.co/datasets/dwb2023/ragas-golden-dataset-v2
下载链接
链接失效反馈官方服务:
资源简介:
RAGAS黄金数据集是一个合成的问答数据集,用于评估检索增强生成(Retrieval Augmented Generation, RAG)系统。它包含了从人工智能代理和代理性AI架构的学术文章中提取的高质量问答对。该数据集通过Prefect和RAGAS测试集生成器框架生成,能够创建基于输入文档的复杂、上下文丰富的评价数据。数据集包括不同复杂度的合成问题、源自源文档的地面真实答案、应检索的上下文信息以及问题和上下文的嵌入向量。
RAGAS Gold Dataset is a synthetic question-answering dataset designed for evaluating Retrieval Augmented Generation (RAG) systems. It contains high-quality question-answer pairs extracted from academic articles on AI agents and agentic AI architectures. This dataset is generated via the Prefect and RAGAS test set generator frameworks, which can create complex, context-rich evaluation data based on input documents. The dataset includes synthetic questions of varying complexity, ground-truth answers derived from source documents, context information that should be retrieved, as well as embedding vectors for both the questions and the context.
创建时间:
2025-05-20
原始信息汇总
数据集概述:ragas-golden-dataset-v2
数据集描述
RAGAS Golden Dataset是一个用于评估检索增强生成(RAG)系统的合成生成问答数据集。包含基于AI代理和代理AI架构学术论文生成的高质量问答对。
数据集摘要
- 生成工具:使用Prefect和RAGAS TestsetGenerator框架生成
- 生成方法:基于输入文档构建内部知识图谱,创建复杂且上下文丰富的评估数据
- 目的:支持RAG系统的无参考评估(包括检索效果、生成保真度和上下文相关性)
- 包含内容:
- 不同复杂度的合成生成问题
- 源自文档的真实答案
- 应检索的上下文信息
- 问题和上下文的嵌入向量
数据集结构
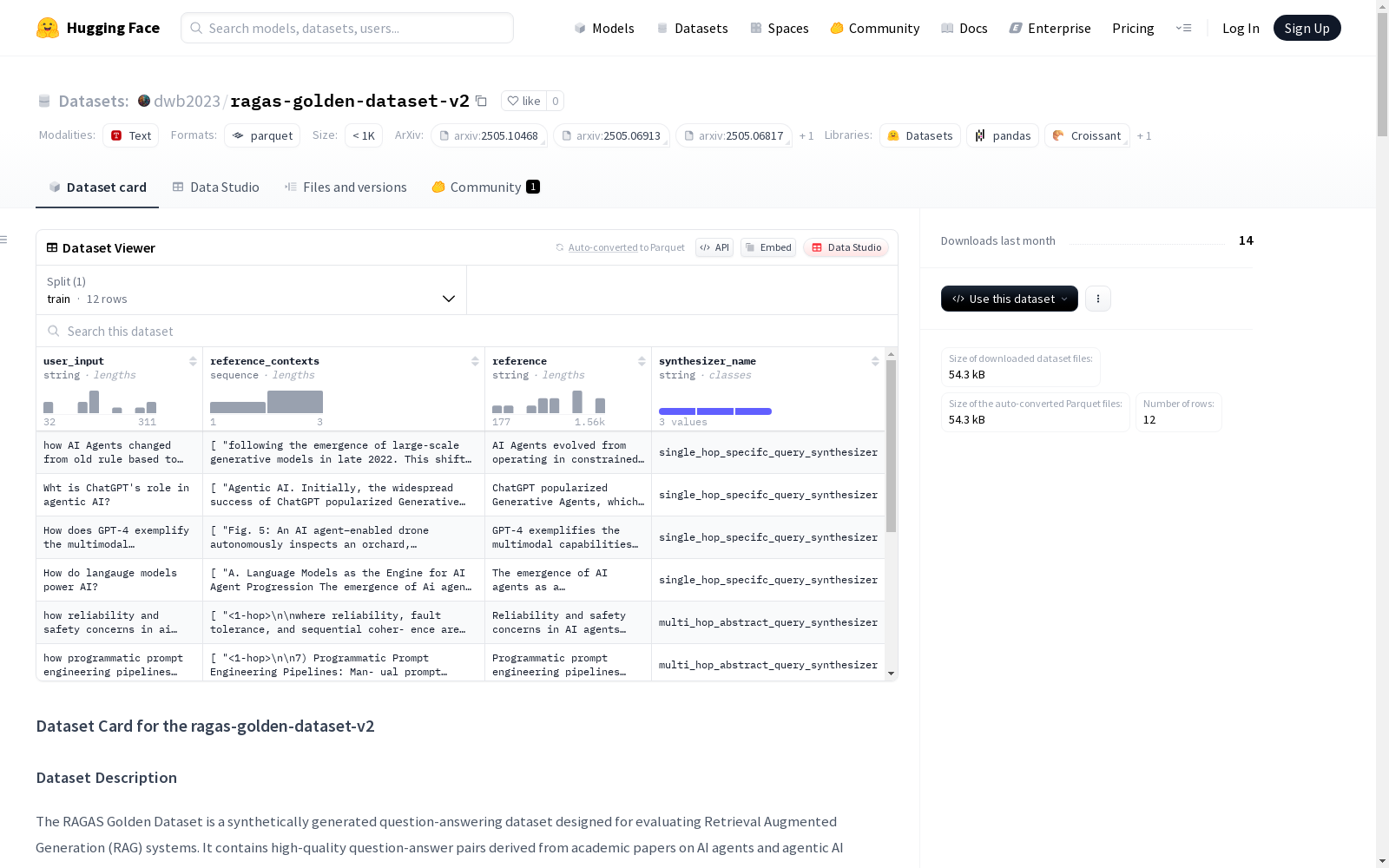
- 字段组成:
user_input:生成的问题文本(字符串)reference_contexts:应检索的相关文档上下文(字符串序列)reference:真实答案(字符串)synthesizer_name:问题生成器名称(字符串)
- 数据量:
- 训练集:12个样本
- 总大小:80,518字节
- 下载大小:54,324字节
支持任务
- RAG系统性能评估
- 问答能力基准测试
- 检索效果测试
- 生成保真度和忠实度评估
数据集创建
数据来源
- 三篇arXiv学术论文:
生成过程
- 使用LangChain的PyPDFDirectoryLoader提取文本内容
- 通过RAGAS TestsetGenerator构建知识图谱
- 基于知识图谱生成多样化问题类型(单跳/多跳、具体/抽象等)
- 识别每个问题的相关上下文
- 从上下文中创建真实答案
使用注意事项
局限性
- 领域局限:专注于AI代理相关学术内容
- 问题分布:合成生成可能无法反映真实用户查询模式
- 规模限制:仅包含12个样本
- 潜在偏见:继承源文档和LLM生成过程的偏见
社会影响
- 促进开发更准确可靠的RAG系统
- 通过高质量评估数据提升AI应用的事实准确性
附加信息
许可
- MIT License
引用信息
bibtex @misc{dwb2023_ragas_golden_dataset, author = {dwb2023}, title = {RAGAS Golden Dataset}, year = {2023}, publisher = {Hugging Face}, howpublished = {https://huggingface.co/datasets/dwb2023/ragas-golden-dataset} }
相关论文引用
包含RAGAS框架论文和三篇源论文的引用信息(详见原始文档)
搜集汇总
数据集介绍
构建方式
在人工智能领域,评估检索增强生成(RAG)系统的性能至关重要。该数据集通过RAGAS TestsetGenerator框架构建,采用知识图谱技术从arXiv上的三篇学术论文中提取信息。具体流程包括文档加载与处理、知识图谱构建、多样化问题生成以及上下文与答案的自动标注。整个生成过程由Prefect工作流协调,确保了数据的系统性和可重复性。
特点
该数据集聚焦于AI代理与智能架构领域,其核心价值在于提供了高质量的合成评估数据。数据记录包含生成的问题文本、相关上下文列表、标准答案以及生成器名称等信息。通过知识图谱技术生成的多样化问题类型,包括单跳与多跳查询、具体与抽象问题等,能够全面评估RAG系统在检索效果、生成保真度等方面的性能。
使用方法
该数据集主要服务于检索增强生成系统的评估与基准测试。研究人员可通过加载数据集中的问题、上下文和标准答案,系统评估RAG系统在各类查询下的表现。使用时应考虑数据的合成特性,建议结合其他真实用户查询数据进行补充验证。数据集采用标准结构存储,可通过HuggingFace库直接加载,便于集成到现有评估流程中。
背景与挑战
背景概述
RAGAS Golden Dataset v2是由dwb2023于2023年构建的合成问答数据集,旨在评估检索增强生成(RAG)系统的性能。该数据集基于Shahul Es等人提出的RAGAS框架,通过算法生成高质量的问题-答案对,其源数据来自arXiv上关于AI代理和代理架构的三篇学术论文。数据集采用知识图谱技术构建,能够生成保持原始内容忠实度的复杂、上下文丰富的评估数据,为RAG系统的检索有效性、生成保真度和上下文相关性等维度的评估提供了重要基准。
当前挑战
该数据集面临的挑战主要体现在两个方面:在领域问题层面,虽然为RAG系统评估提供了标准化数据,但合成生成的问题可能与真实用户查询存在差异,且局限于AI代理学术领域,对其他领域的泛化能力有限;在构建过程层面,依赖LLM生成机制可能引入模型固有偏见,知识图谱技术虽能捕捉文档结构但可能遗漏细微语义,且当前数据集规模较小(仅12个示例),难以全面覆盖各类查询场景。此外,源学术论文本身的内容偏差也会通过生成过程传递至数据集。
常用场景
经典使用场景
在检索增强生成(RAG)系统的评估领域,ragas-golden-dataset-v2数据集作为一项关键基准工具,其经典应用场景主要体现在对系统多维度性能的全面测评。该数据集通过精心设计的合成问题-答案对,能够有效评估RAG系统在信息检索准确性、生成内容忠实度以及上下文相关性等方面的表现,特别适用于比较不同架构模型在复杂查询场景下的性能差异。
解决学术问题
该数据集主要解决了RAG系统评估中缺乏高质量基准数据的核心问题。通过算法生成的多样化问题类型(包括单跳/多跳查询、具体/抽象问题)及其对应的标准答案,研究者无需依赖人工标注即可系统性地评估模型性能。这种参考无关的评估范式显著降低了研究门槛,为RAG技术的迭代优化提供了可量化的科学依据。
衍生相关工作
基于该数据集衍生的经典研究包括RAGAS评估框架的持续优化工作,以及各类针对特定领域(如医疗、法律)的适配性研究。部分学者扩展了其知识图谱构建方法,开发出支持多模态输入的评估体系。数据集提供的预处理流程也被借鉴应用于其他专业领域的基准数据生成。
以上内容由遇见数据集搜集并总结生成


