multi-modal road pothole detection dataset
收藏arXiv2021-09-07 更新2024-07-25 收录
下载链接:
https://mias.group/GAL-Pothole-Detection/
下载链接
链接失效反馈官方服务:
资源简介:
本数据集由同济大学电子与信息工程学院创建,名为‘多模态道路坑洞检测数据集’,包含55个样本,涵盖RGB图像、亚像素深度图像及转换后的深度图像。数据集通过深度图像的转换算法,显著提高了道路损坏区域的辨识度,便于坑洞检测。该数据集适用于训练和评估基于深度学习的道路坑洞检测算法,旨在提高道路维护效率和交通安全。
This dataset was developed by the College of Electronics and Information Engineering of Tongji University, and is officially named "Multimodal Road Pothole Detection Dataset". It comprises 55 samples, including RGB images, sub-pixel depth images, and transformed depth images. By applying a dedicated depth image conversion algorithm, this dataset significantly enhances the distinguishability of road damage regions, thereby facilitating pothole detection tasks. This dataset is designed for training and evaluating deep learning-based road pothole detection algorithms, with the ultimate goal of improving road maintenance efficiency and traffic safety.
提供机构:
同济大学电子与信息工程学院
创建时间:
2021-09-07
搜集汇总
数据集介绍
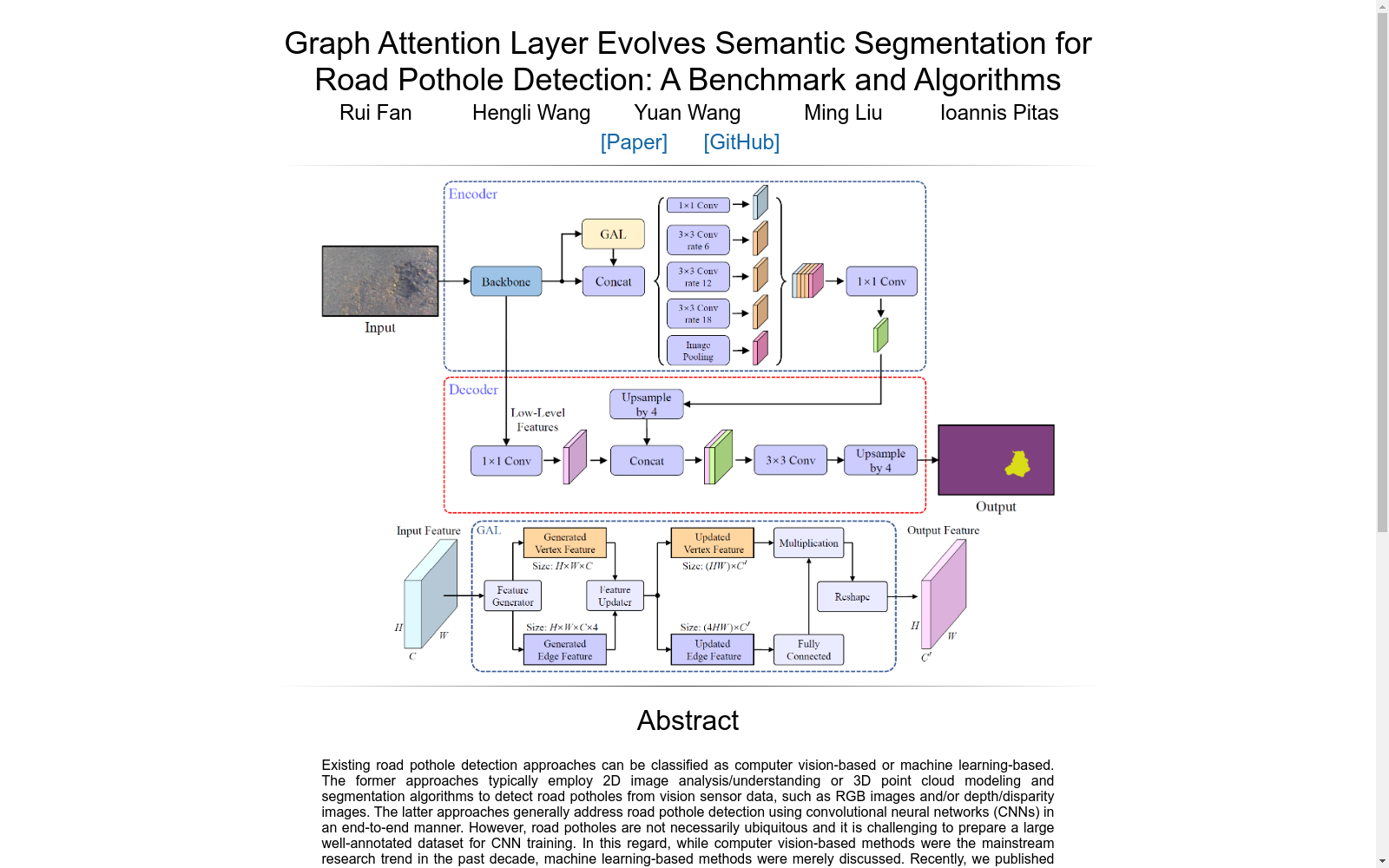
构建方式
在道路维护与自动驾驶领域,精准检测路面坑洼对保障交通安全至关重要。该数据集的构建依托立体视觉技术,采集了55组多模态道路视觉数据,涵盖RGB图像、亚像素视差图像及经视差变换处理后的图像。数据采集通过高分辨率立体相机完成,每幅图像分辨率达800×1312像素,对应14个不同坑洼实例。为确保数据多样性,样本覆盖多种道路场景与光照条件,并采用专业立体匹配算法生成密集亚像素视差图,再通过视差变换算法将原始视差转换为准逆透视视图,显著增强了损伤区域的视觉区分度。
特点
该数据集的核心特点在于其多模态结构与高区分度的损伤表征。数据集中包含三种模态的图像:RGB图像提供丰富的纹理信息,原始视差图像蕴含三维几何特征,而经变换的视差图像则通过算法优化,使得受损路面区域在数值分布上高度聚集,背景区域趋同,极大降低了语义分割的难度。此外,数据集标注精细,每个样本均提供像素级真实标签,支持端到端的深度学习模型训练。其样本分布涵盖不同大小、深度的坑洼,且包含孤立样本用于交叉验证,确保了评估的严谨性与泛化能力。
使用方法
该数据集主要用于训练与评估语义分割卷积神经网络在路面坑洼检测任务上的性能。研究人员可采用十二折交叉验证策略,将53个样本划分为12个子集,分别以RGB、视差及变换视差图像作为输入,训练如DeepLabv3+、U-Net等先进网络。数据使用前需进行标准化与增强处理,如随机翻转、旋转和平移,以提升模型鲁棒性。评估指标包括像素级精确率、召回率、交并比等,通过对比不同模态下的性能,可验证视差变换的有效性。此外,数据集支持图注意力层等新型模块的嵌入研究,以优化特征表示,推动道路损伤检测技术的发展。
背景与挑战
背景概述
多模态道路坑洼检测数据集由范睿、王恒立、王源、刘明及Ioannis Pitas等学者于2021年发布,标志着道路基础设施智能监测领域的重要进展。该数据集作为首个融合立体视觉技术的多模态资源,涵盖了RGB图像、亚像素视差图像及经视差变换处理的图像,旨在应对传统人工检测方法在效率、安全性与客观性上的局限。其核心研究聚焦于利用计算机视觉与机器学习技术,特别是语义分割卷积神经网络,实现道路坑洼的精准识别与定位,为自动化道路维护系统提供了关键的数据支撑与算法基准,显著推动了智能交通与路面病害检测研究的深化。
当前挑战
在道路坑洼检测领域,主要挑战在于坑洼形态的多样性与非普适性,以及复杂环境干扰如路面污渍、阴影等因素导致的误检与漏检。传统方法依赖大量高质量标注数据,而坑洼样本的稀缺性与标注成本高昂制约了机器学习模型的泛化能力。数据集构建过程中,需克服多模态数据对齐、视差图像精确估计及变换算法的稳健性等技术难题,同时确保不同模态间信息的一致性与互补性。此外,如何设计高效网络架构以融合多源特征,并提升模型在真实场景中的鲁棒性与实时性,亦是当前研究的关键挑战。
常用场景
经典使用场景
在道路基础设施智能检测领域,多模态道路坑洼检测数据集为基于深度学习的语义分割算法提供了关键的训练与评估基准。该数据集通过提供同步采集的RGB图像、亚像素视差图像及经过变换的视差图像,构建了多模态视觉数据框架。其经典应用场景集中于训练卷积神经网络进行像素级道路坑洼分割,尤其利用变换后的视差图像中损伤区域与完好路面间的高度可区分性,显著提升了模型在复杂道路环境下的检测鲁棒性与准确性。
解决学术问题
该数据集有效解决了道路坑洼检测研究中标注数据稀缺、单一模态信息有限以及传统方法依赖人工设计特征等核心学术问题。通过提供精确标注的多模态数据,它支持端到端的机器学习方法开发,减少了对经验性图像处理算法的依赖。其引入的视差变换技术将立体视觉数据转化为更易分割的表示形式,为基于深度信息的语义分割模型提供了优化基础,推动了自动化道路损伤检测从理论探索向实用化迈进。
衍生相关工作
基于该数据集,研究者提出了图注意力层这一创新模块,可嵌入多种语义分割网络中以优化特征表示。经典衍生工作包括GAL-DeepLabv3+等模型,它们在基准测试中展现了优越性能。该数据集还催生了针对多模态数据融合、领域自适应以及注意力机制的研究,例如采用对抗域适应技术提升模型泛化能力。这些工作不仅推动了道路坑洼检测的进步,也为通用场景理解任务提供了可迁移的技术框架。
以上内容由遇见数据集搜集并总结生成


