Galgame_Speech_ASR_16kHz
收藏Hugging Face2024-10-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/litagin/Galgame_Speech_ASR_16kHz
下载链接
链接失效反馈资源简介:
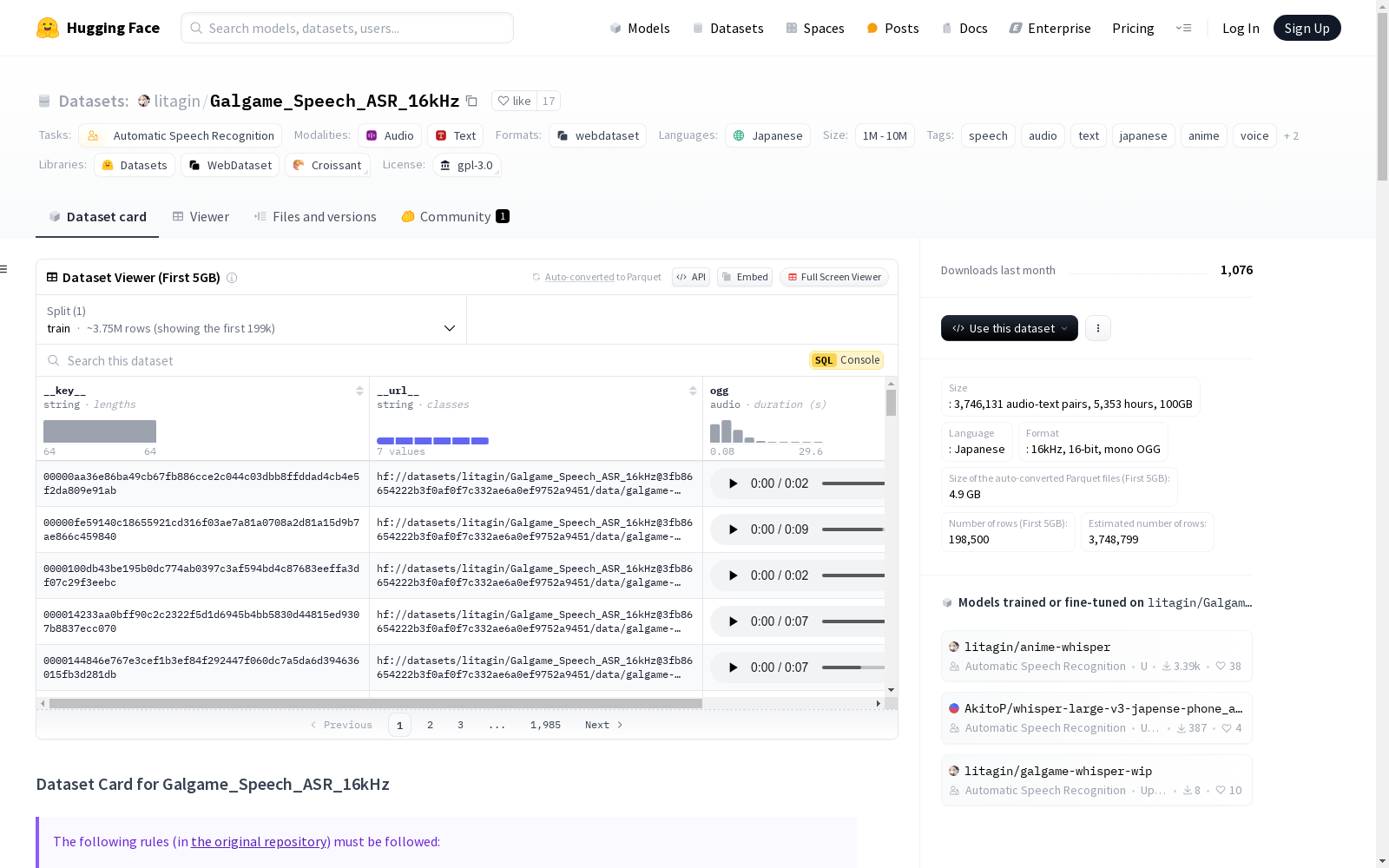
Galgame_Speech_ASR_16kHz 数据集是一个从视觉小说(Galgames)中提取的日语语音数据集,专门用于训练自动语音识别(ASR)模型。该数据集包含3,746,321个音频-文本对,总计5,355小时,大小为100.16 GB。数据集采用WebDataset格式,音频文件为16kHz、16位、单声道OGG格式。该数据集旨在微调ASR模型,如Whisper,特别适用于日语动漫风格的语音领域,包括NSFW内容。然而,由于音频质量较低(16kHz),该数据集不适用于文本到语音(TTS)或语音转换(VC)。数据集根据GNU通用公共许可证v3.0授权,并附加了禁止商业使用的限制,除非获得数据集中列出的所有提供商的明确许可。
The Galgame_Speech_ASR_16kHz dataset is a Japanese speech dataset extracted from visual novels (Galgames), specifically designed for training automatic speech recognition (ASR) models. This dataset contains 3,746,321 audio-text pairs, with a total duration of 5,355 hours and a total size of 100.16 GB. The dataset adopts the WebDataset format, where audio files are in 16kHz, 16-bit, mono OGG format. This dataset is intended for fine-tuning ASR models such as Whisper, and is particularly suitable for the Japanese anime-style speech domain, including NSFW content. However, due to the relatively low audio sampling rate (16kHz), this dataset is not applicable for text-to-speech (TTS) or voice conversion (VC) tasks. The dataset is licensed under the GNU General Public License v3.0, with an additional restriction prohibiting commercial use unless explicit permission is obtained from all providers listed in the dataset.
创建时间:
2024-10-10
原始信息汇总
Galgame_Speech_ASR_16kHz 数据集概述
基本信息
- 语言: 日语
- 许可证: GPL-3.0
- 多语言性: 单语种
- 数据集名称: Galgame_Speech_ASR_16kHz
- 数据量: 1M<n<10M
- 任务类别: 自动语音识别
- 标签: 语音, 音频, 文本, 日语, 动漫, 声音, 视觉小说, 美少女游戏
数据集详情
- 大小:
- 3,746,321 个音频文件(均带有转录文本)
- 总计 5,355 小时
- 115 个 tar 文件,总计 100.16 GB,每个 tar 文件(除最后一个外)包含 32,768 个音频-文本对(OGG 和 TXT 文件),每个 tar 文件约 897 MB
- 语言: 日语
- 格式:
- WebDataset 格式
- 16kHz, 16-bit, 单声道 OGG 文件
数据集描述
- 大小: 3,746,321 个音频-文本对,5,355 小时,100GB
- 语言: 日语
- 格式: 16kHz, 16-bit, 单声道 OGG
数据集来源
所有音频文件和转录文本均来自 OOPPEENN/Galgame_Dataset。
修改内容
- 将音频文件重新采样为 16kHz OGG 格式(音量调整为 x0.9 以避免剪切)
- 使用随机 SHA-256 类似的哈希重命名所有文件
- 排除具有多个不同转录文本的音频文件
- 对转录文本进行归一化处理并根据结果过滤音频文件
使用场景
直接使用
- 微调 ASR 模型,如 Whisper,用于日语动漫类语音领域
- 训练 ASR 模型用于 NSFW 领域(如 aegi 和 chupa 声音),Whisper 和其他 ASR 模型大多无法识别
超出范围的使用
- 不适合用于 TTS(文本到语音)和 VC(语音转换),因为音频质量较低(16kHz)
数据集结构
- 数据集采用 WebDataset 格式
- 包含
galgame-speech-asr-16kHz-train-{000000..000114}.tar文件 - 每个 tar 文件包含音频(OGG)和文本(TXT)文件,文件名相同(SHA-256 类似的哈希)
如何使用
- 使用 🤗 Datasets 库加载数据集时,设置
streaming=True以避免一次性下载整个数据集
数据集创建动机
- 希望获得一个大规模的日语音频-文本对 ASR 语料库,用于动漫类语音领域,由专业声优配音,且转录文本准确率 100%
- 个人对 Whisper 无法识别 Galgame 中的 aegi 和 chupa 声音感到沮丧,因此希望训练一个能够识别这些声音的 ASR 模型
偏见、风险和局限性
- 数据集源自(动漫类)Galgame,因此语音与日常生活中的常规表达有很大不同
- 数据集包含 NSFW 音频(aegi 和 chupa)和台词,不适合所有受众
- 数据集不适合用于 TTS 和 VC,因为音频质量较低(16kHz)
- 数据集中女性声音多于男性声音,这可能会在基于该数据集训练的模型中引入性别偏见
AI搜集汇总
数据集介绍
构建方式
Galgame_Speech_ASR_16kHz数据集源自日本视觉小说(Galgame)的语音数据,专为训练自动语音识别(ASR)模型而设计。该数据集基于OOPPEENN/Galgame_Dataset进行二次开发,经过一系列修改以适应ASR任务。具体修改包括将音频文件重采样为16kHz的OGG格式,使用随机SHA-256哈希重命名文件,并排除具有多个不同转录的音频文件。此外,转录文本经过规范化处理,删除了不必要的符号和重复字符,仅保留日文平假名、片假名、汉字、字母、数字及特定符号。
特点
该数据集包含3,746,131个音频-文本对,总时长达5,353.9小时,数据量约为100GB。所有音频文件均为16kHz、16位单声道OGG格式,转录文本经过严格规范化处理,确保100%的准确性。数据集以WebDataset格式存储,包含115个tar文件,每个文件约包含32,768个音频-文本对。数据集的语音内容主要来自日本视觉小说中的专业配音演员,具有浓厚的动漫风格,尤其适合训练识别动漫语音的ASR模型。
使用方法
使用该数据集时,可通过Hugging Face的Datasets库加载,设置`streaming=True`以避免一次性下载整个数据集。数据集适用于微调Whisper等ASR模型,尤其适合处理动漫风格的日语语音。此外,数据集还可用于训练识别NSFW领域(如aegi和chupa语音)的ASR模型,但需注意其音频质量较低,不适合用于文本到语音(TTS)或语音转换(VC)任务。
背景与挑战
背景概述
Galgame_Speech_ASR_16kHz数据集是一个专注于日语视觉小说(Galgame)领域的语音识别数据集,旨在为自动语音识别(ASR)模型如Whisper提供训练数据。该数据集由OOPPEENN/Galgame_Dataset衍生而来,经过重新采样和文本规范化处理,以适应ASR任务的需求。数据集创建于2024年,主要研究人员通过从原始数据集中筛选和修改音频文件,生成了3,746,131个音频-文本对,总时长达到5,353.9小时。该数据集的发布为日语语音识别领域,尤其是动漫风格语音的识别提供了重要的资源支持。
当前挑战
Galgame_Speech_ASR_16kHz数据集面临的主要挑战包括:1)领域问题的挑战,即如何准确识别动漫风格语音,尤其是NSFW(非适合工作场所)内容中的特殊语音(如aegi和chupa),这些语音在现有ASR模型中往往难以识别;2)构建过程中的挑战,包括音频文件的重新采样、文本规范化以及数据筛选,特别是处理长音频文件和多转录文本的复杂性。此外,数据集的低音频质量(16kHz)限制了其在文本到语音(TTS)和语音转换(VC)任务中的应用。
常用场景
经典使用场景
Galgame_Speech_ASR_16kHz数据集专为训练日语自动语音识别(ASR)模型而设计,尤其适用于处理日本视觉小说(Galgame)中的语音数据。该数据集包含了大量由专业声优录制的日语语音及其对应的文本转录,适用于训练如Whisper等ASR模型,特别是在处理动漫风格语音时表现出色。
实际应用
在实际应用中,Galgame_Speech_ASR_16kHz数据集可用于开发针对日本视觉小说和动漫内容的语音识别系统。这些系统可以应用于游戏开发、动漫制作以及相关娱乐产业,帮助自动生成字幕或进行语音驱动的交互设计。此外,该数据集还可用于教育领域,帮助学习者通过语音识别技术提高日语听力能力。
衍生相关工作
基于Galgame_Speech_ASR_16kHz数据集,许多相关研究工作得以展开。例如,研究人员利用该数据集训练了专门针对动漫风格语音的ASR模型,显著提升了模型在识别特定语音类型时的准确性。此外,该数据集还催生了一系列关于语音识别模型优化的研究,特别是在处理低质量音频和复杂语音模式时的技术改进。
以上内容由AI搜集并总结生成


