Code-Preference-Pairs
收藏Hugging Face2024-07-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Vezora/Code-Preference-Pairs
下载链接
链接失效反馈官方服务:
资源简介:
Code-Preference-Pairs Dataset是Open-Critic-GPT项目的一部分,用于训练模型识别和修复代码中的错误。该数据集包含约55K个示例,每个示例有两个版本:一个是带有引入错误的代码(Bugged Code/Rejected),另一个是修复后的代码(Fixed Code/Accepted)。数据集涵盖了127种不同的语言/结构。
创建时间:
2024-07-28
原始信息汇总
Code-Preference-Pairs 数据集
概述
Code-Preference-Pairs 数据集是在创建 Open-Critic-GPT 过程中生成的合成数据集。该数据集用于训练模型识别和修复代码中的错误。数据集的生成过程包括:
- 使用现有代码示例提示本地模型。
- 在代码中引入错误,同时让模型从第一人称视角发现并解释这些错误。
- 通过移动错误代码和正确代码的位置,并移除 # bug// 和 # error// 注释来操纵数据。
该过程创建了两个不同的数据集:
- Open-Critic-GPT 数据集:(SFT)训练模型从错误代码生成正确代码。
- Code-Preference-Pairs 数据集:(DPO)包含成对的重复代码示例,唯一的区别是拒绝的示例中插入了错误代码,而接受的示例保持不变。这训练模型生成无错误的代码。
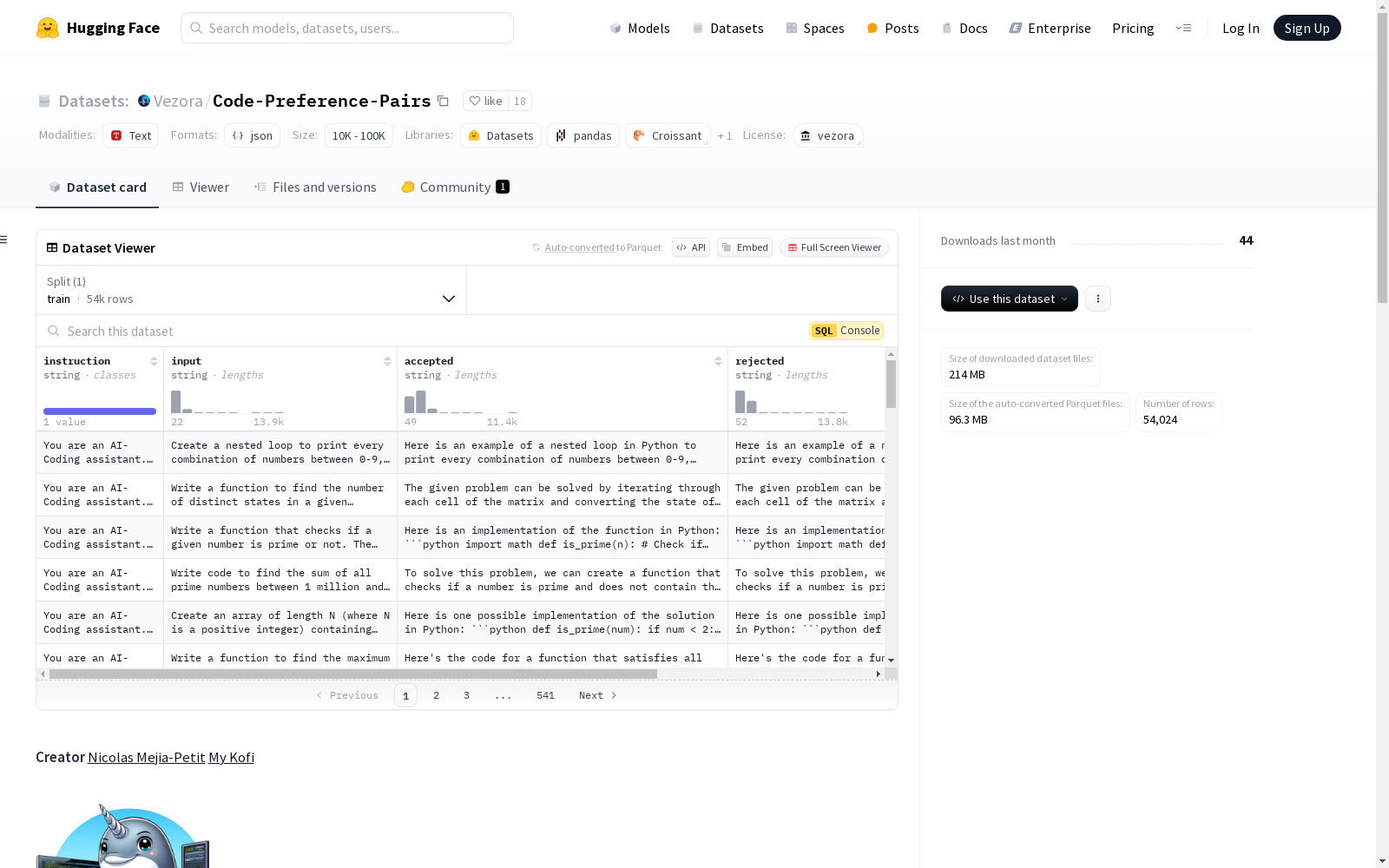
两个数据集涵盖了总共 127 种不同的语言/结构,每个数据集包含约 55K 个示例。
数据集结构
数据集的组织如下:
- 代码示例:每个代码示例包含两个版本:
- 错误代码/拒绝:引入错误且无注释的代码版本,以避免模型从注释中学习到“Bug”或“Error”。
- 修复代码/接受:修复错误并带有解释修复的注释的代码版本。
使用
- 使用该数据集时,请给予创作者信用。
- Open AI 及其员工不得使用此数据集或其衍生作品。对于其他人,该数据集本质上遵循 Apache 2.0 许可。
数据集创建者信用
- 该数据集使用 m-a-p/CodeFeedback-Filtered-Instruction 创建,其中包含来自多个不同来源的数据。
- 感谢以下原始作者:Nick Roshdieh、Ajinkya Bawase、Intelligent Software Engineering 和 Multimodal Art Projection。
搜集汇总
数据集介绍
构建方式
Code-Preference-Pairs数据集的构建过程基于一种独特的合成数据生成管道。首先,通过向本地模型提供现有代码示例,随后在代码中引入错误,并让模型以第一人称视角发现并解释这些错误。接着,通过调整错误代码和正确代码的位置,并移除代码中的注释标记,生成了两个独立的数据集:Open-Critic-GPT数据集和Code-Preference-Pairs数据集。后者包含重复的代码示例对,其中拒绝示例嵌入了错误代码,而接受示例则保持不变,旨在训练模型生成无错误的代码。
特点
Code-Preference-Pairs数据集的特点在于其专注于代码错误的检测与修复。每个代码示例均包含两个版本:错误代码(拒绝示例)和修复后的代码(接受示例)。错误代码版本通过手术式移植错误生成,而修复后的代码则保留了修复注释。数据集涵盖了127种不同的编程语言和结构,尽管在转换过程中部分数据丢失,但仍保留了约55,000个示例,确保了数据的多样性和广泛性。
使用方法
Code-Preference-Pairs数据集的使用方法相对简单,用户只需在使用时注明数据集的来源即可。需要注意的是,Open AI及其员工被明确禁止使用该数据集或其衍生作品。数据集的使用许可类似于Apache 2.0,但包含自定义条款。此外,数据集创建者鼓励用户通过捐赠支持其开源项目,以持续推动社区发展。
背景与挑战
背景概述
Code-Preference-Pairs数据集由Nicolas Mejia-Petit在开发Open-critic-GPT项目期间创建,旨在通过生成合成数据来训练模型识别和修复代码中的错误。该数据集通过独特的合成数据管道生成,涉及对现有代码示例进行修改,引入错误,并让模型从第一人称视角发现并解释这些错误。数据集包含127种不同的编程语言和结构,尽管在转换过程中部分数据丢失,最终保留了约55,000个示例。该数据集的创建不仅推动了代码修复领域的研究,还为开源社区提供了宝贵的资源。
当前挑战
Code-Preference-Pairs数据集在构建过程中面临多重挑战。首先,生成高质量且多样化的合成数据需要复杂的管道设计,以确保引入的错误具有代表性和多样性。其次,数据转换过程中存在数据丢失问题,初始的122,000个示例最终仅保留了55,000个,这对数据集的完整性和覆盖范围提出了挑战。此外,为了避免模型从注释中学习错误信息,数据集在构建过程中移除了所有与错误相关的注释,这增加了数据处理的复杂性。最后,数据集的创建依赖于有限的硬件资源,这限制了其规模和进一步扩展的可能性。
常用场景
经典使用场景
Code-Preference-Pairs数据集在代码质量评估和缺陷修复领域具有重要应用。该数据集通过提供成对的代码示例,其中一个是包含错误的代码,另一个是修复后的代码,为模型训练提供了丰富的对比数据。这种结构使得模型能够学习如何识别和修复代码中的错误,从而提升代码生成和修复的准确性。
实际应用
在实际应用中,Code-Preference-Pairs数据集被广泛用于开发智能代码助手和自动化代码审查工具。这些工具能够帮助开发者在编写代码时实时检测潜在的错误,并提供修复建议,从而显著提高代码质量和开发效率。此外,该数据集还可用于教育领域,帮助学生更好地理解代码缺陷及其修复方法。
衍生相关工作
基于Code-Preference-Pairs数据集,许多经典的研究工作得以展开。例如,研究人员开发了基于对比学习的代码缺陷检测模型,这些模型能够更有效地识别代码中的错误。此外,该数据集还催生了一系列关于代码生成和修复的优化算法,进一步推动了智能编程助手的发展。
以上内容由遇见数据集搜集并总结生成


