KFTT
收藏Hugging Face2024-08-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Hoshikuzu/KFTT
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个日英翻译语料库,源自KFTT(京都自由翻译任务),包含日英语言对,特别关注与京都相关的维基百科文章。数据由专业翻译人员翻译和校对,适用于开发和评估日英机器翻译系统。数据集仅提供了一个训练集(train split),并且数据可以自由分发,遵循Creative Commons Attribution-Share-Alike License 3.0。
创建时间:
2024-08-24
原始信息汇总
数据集卡片 for KFTT
数据集概述
该语料库是从KFTT中提取的日英对数据集。KFTT是一个用于评估和发展日英机器翻译系统的任务。
数据集信息
特征
- translation
- en: 类型为字符串
- ja: 类型为字符串
数据分割
- train
- 字节数: 83189962
- 样本数: 218038
下载和数据集大小
- 下载大小: 48806189 字节
- 数据集大小: 83189962 字节
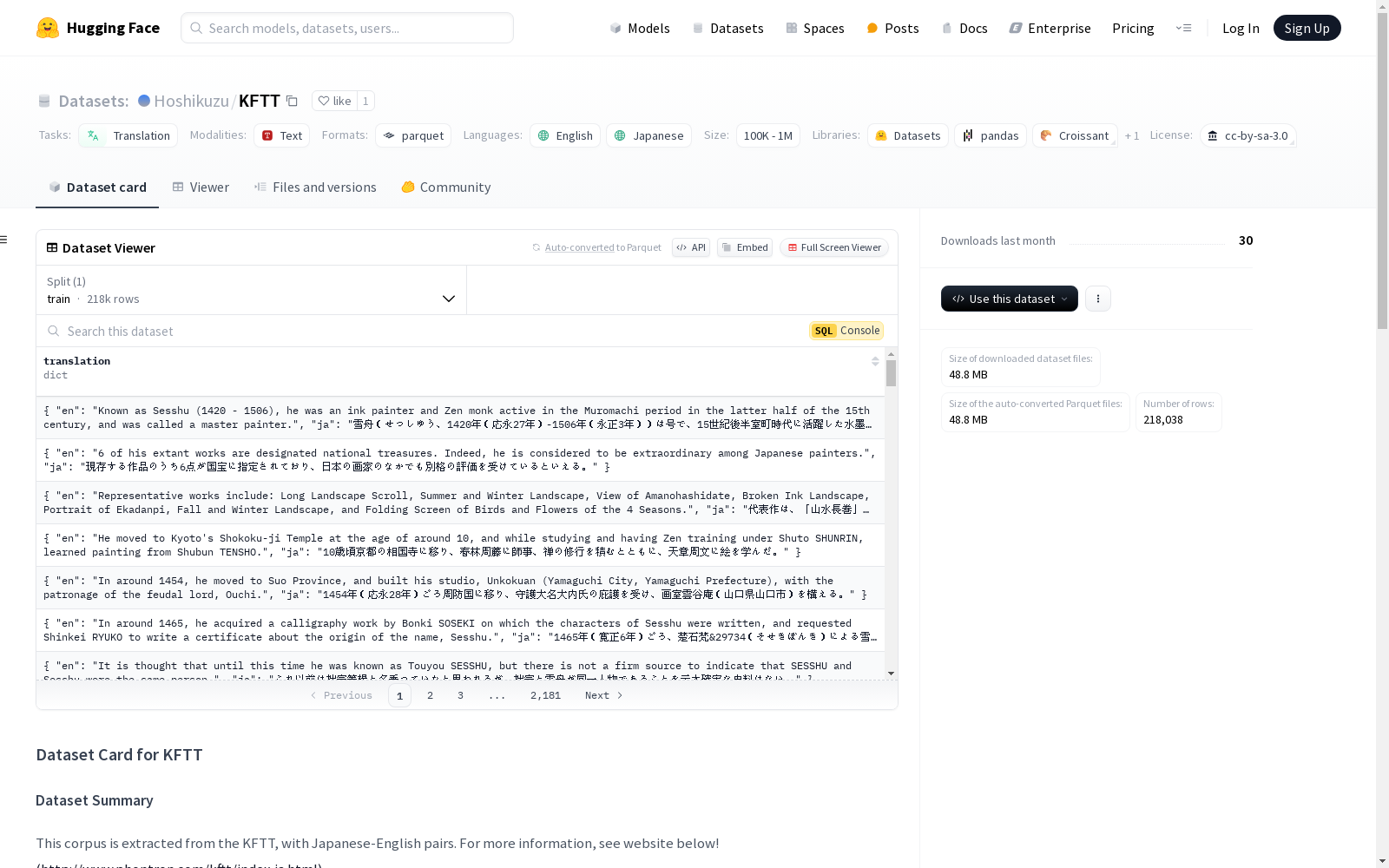
数据实例
例如: json { "en": "Known as Sesshu (1420 - 1506), he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century, and was called a master painter.", "ja": "雪舟(せっしゅう、1420年(応永27年)-1506年(永正3年))は号で、15世紀後半室町時代に活躍した水墨画家・禅僧で、画聖とも称えられる。" }
内容
京都自由翻译任务是一个专注于与京都相关的维基百科文章的日英翻译任务。数据最初由国家信息与通信技术研究所(NICT)准备并发布为日英双语维基百科京都文章语料库(我们仅使用数据,NICT并不特别支持或赞助此任务)。数据的特点如下:
- 由专业翻译人员翻译和校对的日英数据。日英语言对由于语言之间的差异而具有挑战性,是一个仍需大量工作的语言对(截至2011年2月)。
- 专业领域的百科全书文本。因此,存在许多有趣且困难的现象,如音译和源语言中存在但目标语言中不存在的概念的语义翻译。
- 根据知识共享署名-相同方式共享3.0许可自由分发。该任务使用的处理数据也在相同条件下分发。
数据分割
仅提供train分割。
引用信息
json Graham Neubig, "The Kyoto Free Translation Task," http://www.phontron.com/kftt, 2011. @misc{neubig11kftt, author = {Graham Neubig}, title = {The {Kyoto} Free Translation Task}, howpublished = {http://www.phontron.com/kftt}, year = {2011} }
搜集汇总
数据集介绍
构建方式
KFTT数据集源自京都自由翻译任务,专注于与京都相关的维基百科文章。该数据集由日本信息通信研究机构(NICT)最初准备并发布,作为维基百科京都文章日英双语语料库的一部分。数据经过专业翻译人员的翻译和校对,确保了语言对的高质量。数据集以日英双语对的形式呈现,涵盖了丰富的百科文本内容,特别关注了语言之间的差异和翻译难点。
特点
KFTT数据集的特点在于其专注于日英翻译任务,语言对之间的差异显著,尤其是在语义翻译和音译方面存在挑战。数据内容为百科文本,涉及专业领域的术语和概念,增加了翻译的复杂性。此外,数据集在Creative Commons Attribution-Share-Alike 3.0许可下自由分发,确保了其广泛的可访问性和使用自由度。
使用方法
使用KFTT数据集时,可以通过Hugging Face的`datasets`库进行加载。用户只需调用`load_dataset`函数并指定数据集名称即可获取数据。若数据加载时间较长,可通过设置`streaming=True`参数实现流式加载,提升效率。数据集仅提供训练集,适用于日英机器翻译系统的评估与开发。
背景与挑战
背景概述
KFTT(Kyoto Free Translation Task)数据集由Graham Neubig于2011年创建,旨在为日英机器翻译系统的评估与开发提供支持。该数据集基于日本国立信息通信技术研究所(NICT)提供的京都相关维基百科文章的双语语料库,并由专业翻译人员进行翻译与校对。KFTT的创建标志着日英翻译领域的一个重要里程碑,尤其是在处理语言差异和领域特定文本方面。其数据涵盖了百科全书式的专业领域文本,为研究者在处理音译、语义翻译等复杂现象时提供了宝贵的资源。该数据集在机器翻译领域具有广泛的影响力,尤其是在日英翻译任务中,为后续研究提供了重要的基准。
当前挑战
KFTT数据集在解决日英机器翻译问题时面临多重挑战。首先,日英语言之间存在显著的语法和语义差异,例如日语的主语省略和复杂的敬语系统,这些特性使得翻译任务尤为复杂。其次,数据集中的文本涉及京都相关的专业领域内容,包含大量文化特定词汇和概念,这对翻译模型的跨语言语义理解能力提出了更高要求。此外,构建过程中需确保翻译质量,专业翻译人员的参与虽然提升了数据的准确性,但也增加了数据采集和处理的成本与时间。最后,尽管数据集在特定领域具有代表性,但其规模相对有限,可能限制了模型在更广泛场景下的泛化能力。
常用场景
经典使用场景
KFTT数据集在机器翻译领域中被广泛用于训练和评估日语到英语的翻译模型。由于其数据来源于京都相关的维基百科文章,且经过专业翻译人员的校对,该数据集特别适合用于研究复杂语言现象,如专有名词的音译和跨文化概念的语义转换。
实际应用
在实际应用中,KFTT数据集被广泛用于开发商业和学术用途的日语到英语翻译工具。这些工具不仅帮助用户理解日语内容,还在国际交流、学术研究和跨文化合作中发挥了重要作用。特别是在涉及京都历史、文化和旅游信息的翻译任务中,该数据集的表现尤为突出。
衍生相关工作
基于KFTT数据集,许多经典的研究工作得以展开。例如,研究人员利用该数据集开发了多种先进的神经机器翻译模型,这些模型在翻译质量和效率上取得了显著提升。此外,该数据集还催生了一系列关于跨语言信息检索和多语言文本生成的研究,进一步拓展了其在自然语言处理领域的应用范围。
以上内容由遇见数据集搜集并总结生成


