GLIMPSE
收藏github2025-08-23 更新2025-08-24 收录
下载链接:
https://github.com/aiming-lab/GLIMPSE
下载链接
链接失效反馈官方服务:
资源简介:
GLIMPSE是一个专门设计的基准测试,用于评估大型视觉语言模型是否真正用视频思考。它包含3,269个视频和超过4,342个高度视觉中心的问题,涵盖11个类别,包括轨迹分析、时间推理和取证检测等。所有问题都由人工标注者精心设计,需要观看完整视频并进行全视频上下文推理
GLIMPSE is a purpose-built benchmark designed to evaluate whether large vision-language models truly reason about videos. It comprises 3,269 videos and over 4,342 highly visual-centric questions, spanning 11 categories including trajectory analysis, temporal reasoning, forensic detection, and more. All questions are meticulously designed by human annotators, requiring viewers to watch the full video and perform full-video contextual reasoning.
创建时间:
2025-08-07
原始信息汇总
GLIMPSE 数据集概述
数据集基本信息
- 数据集名称:GLIMPSE
- 创建目的:评估大型视觉语言模型是否真正具备视频思考能力
- 数据规模:3,269个视频,4,342个高质量视觉中心问题
- 视频时长:20秒至2分钟
- 标注方式:人工精心设计
核心特征
- 人类精心设计问题:所有问题均由人工标注者精心设计,需要观看完整视频并进行全视频上下文推理
- 超越帧扫描:问题无法通过扫描选定帧或仅依赖文本来回答
- 严格验证:人类评估准确率达到94.82%
- 挑战性:即使最佳性能模型GPT-o3仅达到66.43%准确率
类别划分
数据集包含11个综合类别:
- 轨迹分析:分析物体运动模式、方向和位移
- 时序推理:理解事件的时间和顺序关系
- 定量估计:计算动态事件如重复动作或物体出现/消失
- 事件识别:确定事件发生及其顺序关系
- 反向事件推理:从部分信息重建事件流
- 场景上下文感知:理解视频中的背景变化
- 速度估计:通过分析时间位移计算移动物体的相对速度
- 电影动力学:通过分析前景-背景关系和运动模式识别摄像机运动
- 真实性分析:检测文本到视频模型生成的假视频
- 机器人评估:识别和评估机器人动作
- 多对象交互:分析多个实体间的交互
质量保证
- 人工标注:所有问题由英语熟练的研究人员制作
- 全视频要求:每个问题都需要理解整个视频
- 双向测试:是/否问题包含反向对以减少评估偏差
- 严格审查:多阶段质量控制确保视觉中心性和可回答性
性能表现
- 人类专家:94.82%准确率(黄金标准)
- 最佳模型:GPT-o3达到66.43%准确率
- 显著差距:最佳模型与人类表现存在28.39%的差距
- 类别差异:模型在场景上下文感知和真实性分析方面表现相对较好,在时序推理和轨迹分析方面表现较差
研究意义
揭示了LVLM仍然难以超越表面级推理,真正实现"视频思考"。GLIMPSE为评估和推进多模态AI的视频理解能力提供了新标准,突显了当前模型性能与真正视频理解之间的差距。
引用信息
bibtex @misc{zhou2025glimpselargevisionlanguagemodels, title={GLIMPSE: Do Large Vision-Language Models Truly Think With Videos or Just Glimpse at Them?}, author={Yiyang Zhou and Linjie Li and Shi Qiu and Zhengyuan Yang and Yuyang Zhao and Siwei Han and Yangfan He and Kangqi Li and Haonian Ji and Zihao Zhao and Haibo Tong and Lijuan Wang and Huaxiu Yao}, year={2025}, eprint={2507.09491}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2507.09491}, }
搜集汇总
数据集介绍
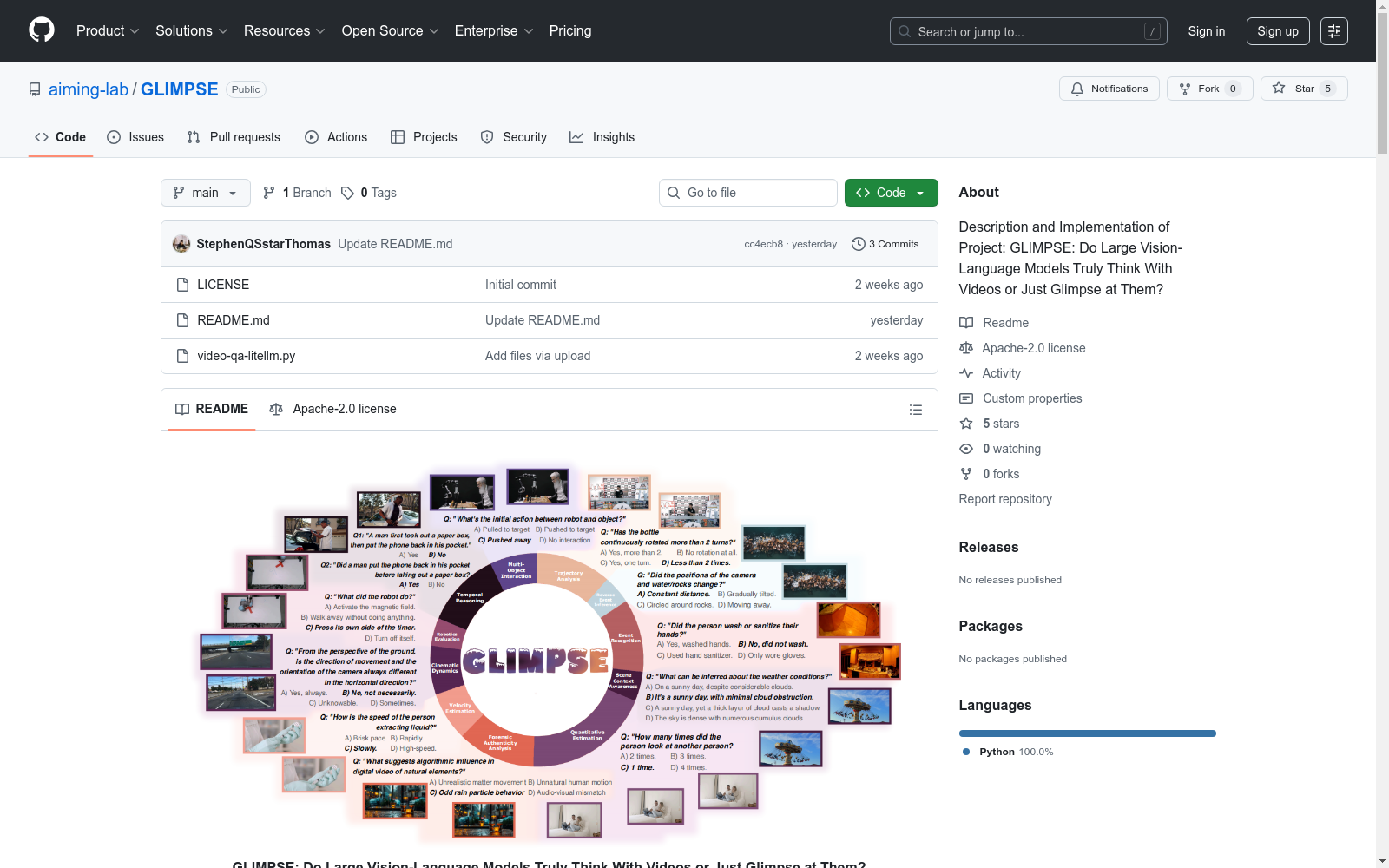
构建方式
在视频理解研究领域,GLIMPSE数据集的构建遵循严谨的三阶段流程:首先从多样化场景中采集3,269段时长介于20秒至2分钟的视频素材,确保内容复杂度与时效性的平衡;随后由专业研究人员手工设计4,342个高度视觉中心化的问题-答案对,涵盖轨迹分析、时序推理等11个认知维度;最终通过双向测试与多轮质量审查机制,保证每个问题均需完整视频上下文理解方能解答,杜绝帧级片面推理的可能性。
特点
该数据集的核心特征体现在其对人类认知过程的深度模拟:所有问题均需基于动态视觉时序关系进行推理,而非静态帧分析。其问题体系涵盖轨迹分析、速度估算、多对象交互等11个精密设计的类别,每类问题均要求模型展现时空连贯性理解能力。特别设计的反向事件推理与真实性检测任务,进一步挑战模型对视频内容的深层逻辑解析能力,与人类94.82%的评估准确率形成鲜明对比。
使用方法
研究者可通过安装litellm及计算机视觉基础工具包快速部署实验环境,配置主流大模型API密钥后即可运行评估脚本。数据集支持对开源与闭源视频-语言模型进行统一测试,通过标准化接口获取模型在11个认知维度的性能表现。评估结果可清晰揭示模型在时序推理、轨迹分析等薄弱环节,为提升多模态模型的视频认知能力提供精准诊断依据。
背景与挑战
背景概述
GLIMPSE数据集由研究团队于2025年创建,旨在评估大型视觉语言模型是否真正具备视频理解能力。该数据集包含3,269个视频和4,342个高度视觉中心化的问题,涵盖轨迹分析、时序推理、法医检测等11个类别。其核心研究问题聚焦于模型能否超越静态图像分析,实现深层次的时空交互推理,对推动多模态人工智能在视频理解领域的发展具有重要影响力。
当前挑战
GLIMPSE解决的领域挑战在于现有视频基准往往依赖关键帧扫描,缺乏对时间连贯性和动态交互的深度推理。构建过程中的挑战包括确保每个问题必须观看完整视频才能解答,避免模型通过局部帧或文本线索作弊,同时维持问题的高视觉中心化和人类评估的准确性,这要求严格的质量控制和双向测试设计。
常用场景
经典使用场景
在视频理解研究领域,GLIMPSE数据集被广泛用于评估多模态大模型对视频内容的深度认知能力。该数据集通过精心设计的11个类别问题,要求模型必须完整观看视频并理解时空动态关系,而非仅捕捉关键帧信息。研究者利用这一基准测试模型在轨迹分析、时序推理和真实性验证等复杂任务中的表现,从而推动模型从表层感知向深层理解演进。
解决学术问题
GLIMPSE有效解决了当前视频理解研究中模型过度依赖静态帧特征而忽视时序连贯性的核心问题。通过引入需要全局视频上下文推理的高质量问答对,该数据集填补了现有基准在评估动态场景理解能力方面的空白。其人类级标注精度与模型性能间的显著差距,为学术界提供了量化评估模型视频认知深度的新范式,推动了多模态推理机制的理论创新。
衍生相关工作
GLIMPSE催生了多个视频理解方向的创新研究,包括基于时序注意力的视频编码器设计和多粒度时空推理框架。该数据集启发的Video-LLaMA2和Chat-UniVi等模型在架构上增强了长期依赖建模能力。后续工作还拓展了其在医疗视频分析中的应用,如内镜操作轨迹追踪和手术动作分解,推动了跨领域的视频认知技术发展。
以上内容由遇见数据集搜集并总结生成


