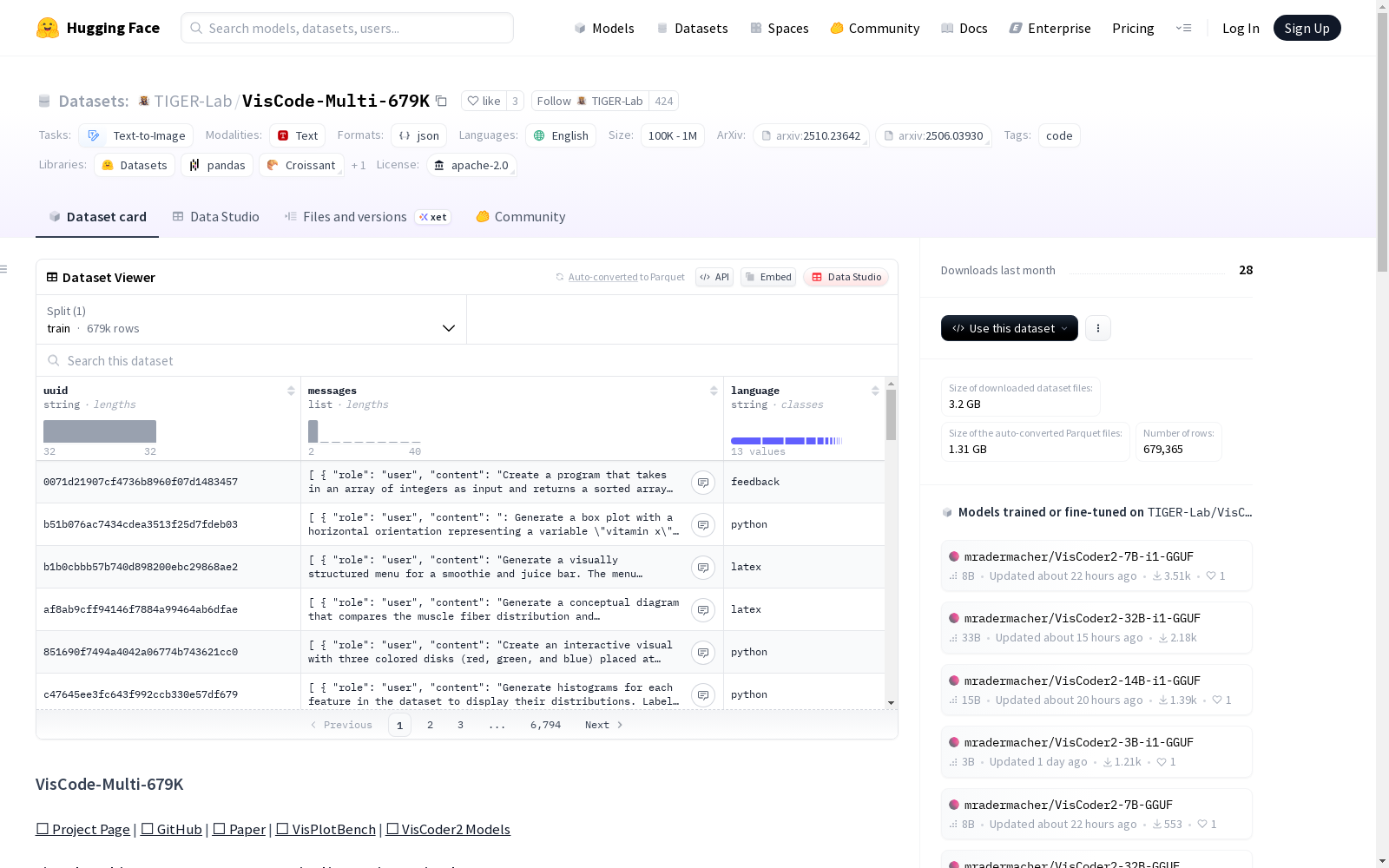
VisCode-Multi-679K
收藏VisCode-Multi-679K 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 文本到图像
- 语言: 英语
- 标签: 代码
数据集简介
VisCode-Multi-679K 是一个大规模监督指令调优数据集,用于训练大语言模型生成和调试可执行的可视化代码,涵盖12种编程语言。
数据规模与覆盖范围
- 样本数量: 超过679,000个样本
- 编程语言: 12种编程语言,包括Python、LaTeX、HTML、SVG、Vega-Lite、LilyPond、Asymptote、Mermaid、JavaScript、TypeScript、R和C++
数据格式
每个样本为JSON对象,包含以下三个键:
uuid: 样本的唯一标识符messages: 对话轮次列表- 用户角色:提供描述可视化任务的自然语言指令
- 助手角色:使用支持的编程语言之一回复可执行代码
language: 可视化代码使用的编程语言
应用场景
- 多语言可视化代码生成的指令调优
- 利用执行反馈进行多轮自我校正
- 训练模型对齐自然语言、代码语义和渲染输出
关联资源
- 项目页面: https://tiger-ai-lab.github.io/VisCoder2
- GitHub仓库: https://github.com/TIGER-AI-Lab/VisCoder2
- 论文: https://arxiv.org/abs/2510.23642
- 评估基准: https://huggingface.co/datasets/TIGER-Lab/VisPlotBench
- 相关模型: https://huggingface.co/collections/TIGER-Lab/viscoder2
引用信息
bibtex @misc{ni2025viscoder2buildingmultilanguagevisualization, title={VisCoder2: Building Multi-Language Visualization Coding Agents}, author={Yuansheng Ni and Songcheng Cai and Xiangchao Chen and Jiarong Liang and Zhiheng Lyu and Jiaqi Deng and Kai Zou and Ping Nie and Fei Yuan and Xiang Yue and Wenhu Chen}, year={2025}, eprint={2510.23642}, archivePrefix={arXiv}, primaryClass={cs.SE}, url={https://arxiv.org/abs/2510.23642}, }
@article{ni2025viscoder, title={VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation}, author={Ni, Yuansheng and Nie, Ping and Zou, Kai and Yue, Xiang and Chen, Wenhu}, journal={arXiv preprint arXiv:2506.03930}, year={2025} }