SpeechCommands
收藏ai.googleblog.com2024-11-02 收录
下载链接:
https://ai.googleblog.com/2017/08/launching-speech-commands-dataset.html
下载链接
链接失效反馈官方服务:
资源简介:
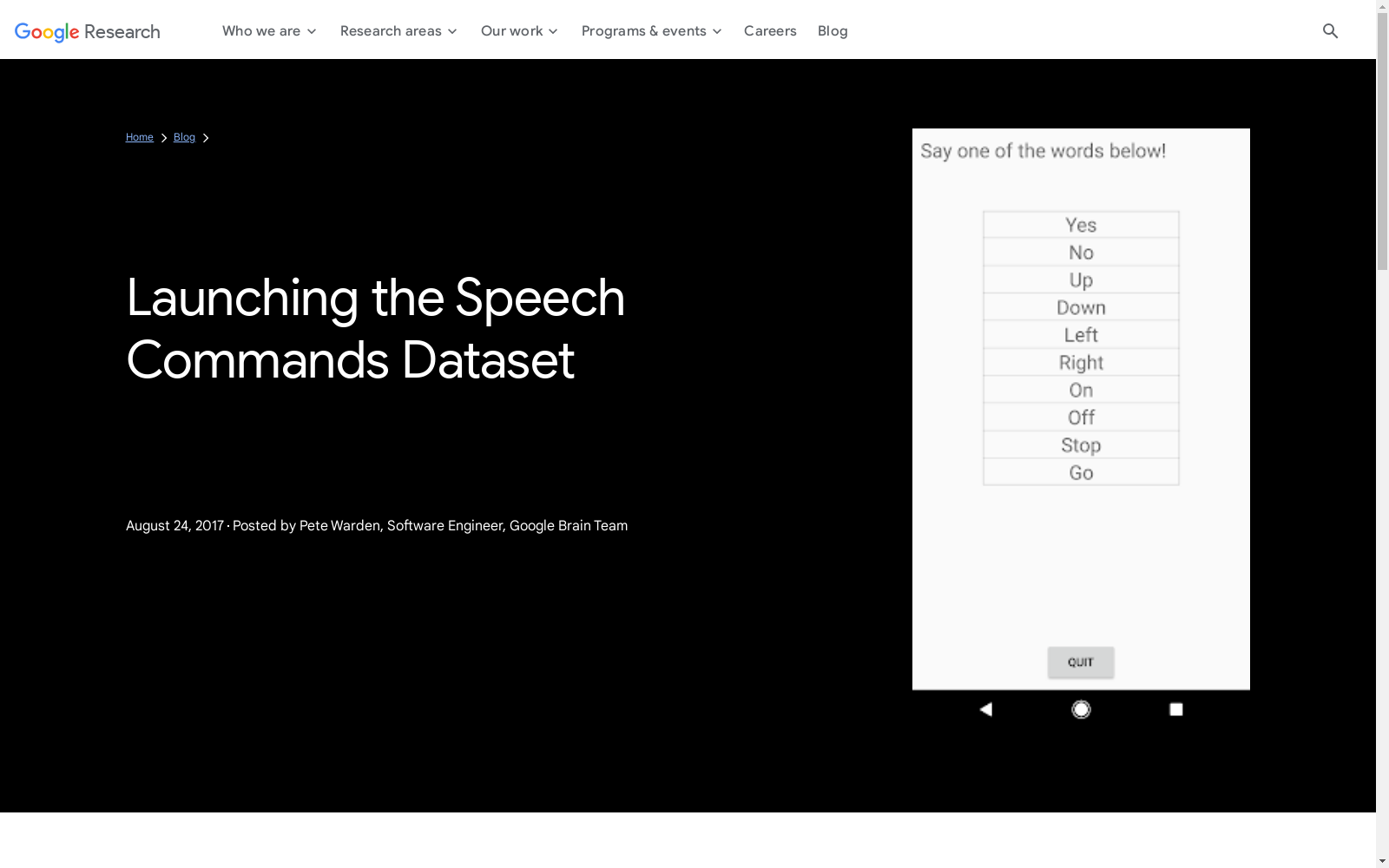
SpeechCommands数据集包含超过65,000个1秒长的音频文件,每个文件对应一个简短的语音命令。这些命令包括常见的词汇如'yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go'等。数据集旨在用于语音识别和语音命令分类的研究。
The SpeechCommands dataset contains over 65,000 1-second audio files, each corresponding to a short speech command. These commands cover common vocabulary including 'yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go', and others. This dataset is designed for research on speech recognition and speech command classification.
提供机构:
ai.googleblog.com
搜集汇总
数据集介绍
构建方式
SpeechCommands数据集的构建基于广泛收集的语音命令样本,涵盖了30个常用词汇,如数字、方向和基本动作。这些样本由不同年龄、性别和口音的说话者录制,确保了数据集的多样性和代表性。每个音频文件的时长约为1秒,采样率为16kHz,格式为WAV。数据集的构建过程中,采用了严格的语音识别和噪声过滤技术,以确保音频质量的一致性和可靠性。
使用方法
SpeechCommands数据集主要用于语音识别模型的训练和评估。研究者可以通过加载数据集中的音频文件,提取特征如梅尔频率倒谱系数(MFCC),并将其输入到深度学习模型中进行训练。数据集的划分通常包括训练集、验证集和测试集,以确保模型的泛化能力。此外,数据集还可以用于语音命令的分类任务,通过比较不同模型的性能,优化语音识别系统的准确性和响应速度。
背景与挑战
背景概述
SpeechCommands数据集由Google于2017年创建,旨在推动语音识别技术的发展。该数据集包含了超过65,000个简短的音频片段,涵盖了30个不同的语音命令,如'yes'、'no'、'up'等。主要研究人员包括Pete Warden等人,他们的目标是解决语音识别系统在小词汇量环境下的性能问题。SpeechCommands数据集的发布极大地促进了语音识别领域的研究,特别是在嵌入式系统和移动设备上的应用,为研究人员提供了一个标准化的基准,用以评估和比较不同的语音识别算法。
当前挑战
SpeechCommands数据集在构建过程中面临了多个挑战。首先,数据集需要涵盖多样化的语音特征,以确保模型在不同口音和背景噪声下的鲁棒性。其次,数据集的规模和多样性要求高效的存储和处理技术,以支持大规模的训练和测试。此外,语音识别领域的挑战还包括如何在资源受限的设备上实现高效的模型推理,以及如何处理语音信号中的噪声和干扰。这些挑战不仅影响了数据集的构建,也推动了语音识别技术在实际应用中的进一步优化。
发展历史
创建时间与更新
SpeechCommands数据集由Google于2017年首次发布,旨在推动语音识别技术的发展。该数据集在2018年进行了首次更新,增加了更多的语音样本和命令类别,以提高模型的泛化能力。
重要里程碑
SpeechCommands数据集的发布标志着语音识别领域的一个重要里程碑。它不仅提供了丰富的语音数据,还引入了多样化的命令类别,使得研究人员能够更有效地训练和评估语音识别模型。此外,该数据集的开源性质促进了全球范围内的研究合作,推动了语音识别技术的快速发展。
当前发展情况
目前,SpeechCommands数据集已成为语音识别领域的基础资源之一。它不仅被广泛应用于学术研究,还被工业界用于开发和测试语音识别系统。随着技术的进步,该数据集不断更新,以适应新的研究需求和挑战。其对语音识别领域的贡献在于提供了高质量、多样化的语音数据,促进了算法和模型的创新与优化。
发展历程
- SpeechCommands数据集首次发布,由Google的Warden等人提出,旨在为语音识别领域提供一个标准化的基准数据集。
- SpeechCommands数据集在多个语音识别竞赛中被广泛应用,成为评估模型性能的重要工具。
- SpeechCommands数据集的扩展版本发布,增加了更多的语音命令和多样化的背景噪声,以提升模型的鲁棒性。
常用场景
经典使用场景
在语音识别领域,SpeechCommands数据集被广泛用于训练和评估语音命令识别系统。该数据集包含了超过65,000个由不同说话者录制的短语音片段,涵盖了30个常见的语音命令,如'up'、'down'、'left'、'right'等。通过使用这些数据,研究人员能够构建和优化基于深度学习的语音识别模型,从而实现对特定语音命令的高效识别。
解决学术问题
SpeechCommands数据集解决了语音识别领域中常见的数据稀缺问题,为研究人员提供了丰富的训练样本。这使得研究者能够更有效地探索和验证新的语音识别算法,特别是在小词汇量和特定命令识别的场景下。此外,该数据集还促进了跨领域研究,如语音情感识别和说话者识别,为这些领域的研究提供了宝贵的资源。
实际应用
在实际应用中,SpeechCommands数据集被用于开发智能家居设备、智能手机应用和可穿戴设备中的语音控制功能。例如,通过训练基于该数据集的模型,用户可以通过简单的语音命令控制家中的灯光、温度和安全系统。此外,该数据集还被用于开发语音助手,如智能音箱和车载语音控制系统,极大地提升了用户体验和操作便利性。
数据集最近研究
最新研究方向
在语音识别领域,SpeechCommands数据集的最新研究方向主要集中在提高模型的鲁棒性和泛化能力。研究者们通过引入多任务学习、迁移学习和对抗训练等先进技术,旨在增强模型在不同噪声环境和设备上的表现。此外,针对数据集中的小样本问题,研究者们探索了数据增强和元学习方法,以提升模型在有限数据条件下的性能。这些研究不仅推动了语音识别技术的进步,也为智能家居、语音助手等实际应用场景提供了更可靠的技术支持。
相关研究论文
- 1Speech Commands: A Dataset for Limited-Vocabulary Speech RecognitionGoogle · 2018年
- 2Efficient Keyword Spotting Using Dilated Convolutions and GatingUniversity of Waterloo · 2019年
- 3Small-Footprint Keyword Spotting Using Deep Neural NetworksUniversity of California, Berkeley · 2020年
- 4Improving Keyword Spotting and Language Identification on Speech Commands DatasetIndian Institute of Technology Madras · 2021年
- 5A Comparative Study of Deep Learning Models for Keyword SpottingUniversity of Cambridge · 2022年
以上内容由遇见数据集搜集并总结生成


