PublicHearingBR
收藏Hugging Face2024-10-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/unicamp-dl/PublicHearingBR
下载链接
链接失效反馈官方服务:
资源简介:
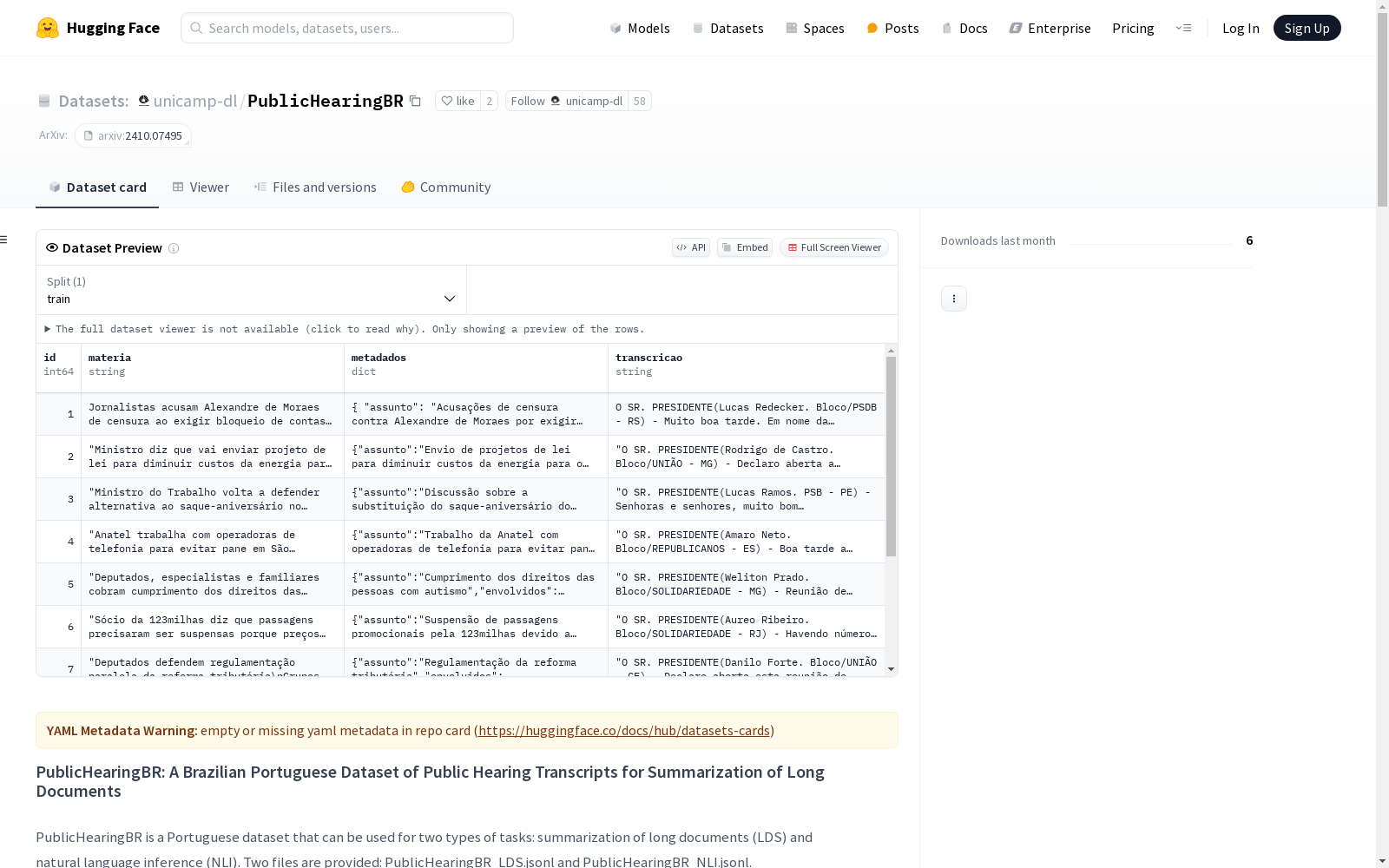
PublicHearingBR是一个葡萄牙语数据集,主要用于长文档摘要(LDS)和自然语言推理(NLI)任务。数据集包含两个文件:PublicHearingBR_LDS.jsonl和PublicHearingBR_NLI.jsonl。PublicHearingBR_LDS.jsonl包含206个样本,用于测试长文档摘要,每个样本包含一个公共听证会的转录文本、新闻文章的摘要文本以及结构化的摘要信息。PublicHearingBR_NLI.jsonl包含4,238个样本,用于测试自然语言推理,每个样本包含一个观点和一组文本,并有一个标志指示该观点是否可以从这组文本中推断出来。
提供机构:
unicamp-dl
创建时间:
2024-10-04
原始信息汇总
PublicHearingBR: A Brazilian Portuguese Dataset of Public Hearing Transcripts for Summarization of Long Documents
概述
PublicHearingBR是一个葡萄牙语数据集,适用于两种类型的任务:长文档摘要(LDS)和自然语言推理(NLI)。数据集包含两个文件:PublicHearingBR_LDS.jsonl和PublicHearingBR_NLI.jsonl。
数据集文件
1. PublicHearingBR_LDS - 长文档摘要
- 文件:
PublicHearingBR_LDS.jsonl - 样本数量: 206个
- 结构:
id: 样本编号(从1到206)transcricao: 公共听证会转录文本(长文档)materia: 新闻文章提取的文本(摘要)metadados: 结构化摘要,包含以下字段:assunto: 文章的主要主题envolvidos: 包含新闻文章中提到的人及其详细信息的列表,包括:cargo: 职位nome: 姓名opinioes: 表达的意见列表
2. PublicHearingBR_NLI - 自然语言推理
- 文件:
PublicHearingBR_NLI.jsonl - 样本数量: 4,238个
- 结构:
id: 引用phbr_lds中的样本编号(仅作为参考ID)metadados_extraidos: 结构类似于phbr_lds中的metadados,但有一些差异,包含以下字段:assunto: 转录文本的主要主题envolvidos: 包含实验提取的人及其详细信息的列表,包括:nome: 姓名cargo: 职位opinioes: 意见列表,每个元素是一个字典,包含以下字段:opiniao: 提取的意见chunks_proximos: 包含四个块的列表,任务是确定是否可以从这些块中推断出意见verificacao_alucinacao: 包含幻觉验证的字典,包括以下字段:verificacao_manual: 手动注释,布尔值,指示意见是否为幻觉prompt_1_gpt-4o-mini-2024-07-18: 自动验证结果prompt_2_gpt-4o-mini-2024-07-18: 自动验证结果prompt_3_gpt-4o-mini-2024-07-18: 自动验证结果
引用
@misc{fernandes2024publichearingbrbrazilianportuguesedataset, title={PublicHearingBR: A Brazilian Portuguese Dataset of Public Hearing Transcripts for Summarization of Long Documents}, author={Leandro Carísio Fernandes and Guilherme Zeferino Rodrigues Dobins and Roberto Lotufo and Jayr Alencar Pereira}, year={2024}, eprint={2410.07495}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2410.07495}, }
搜集汇总
数据集介绍
构建方式
PublicHearingBR数据集的构建基于巴西葡萄牙语的公开听证会转录文本,旨在支持长文档摘要和自然语言推理任务。数据集包含两个主要文件:PublicHearingBR_LDS.jsonl和PublicHearingBR_NLI.jsonl。前者包含206个用于测试长文档摘要的样本,后者则包含4,238个用于自然语言推理的样本。数据集的构建过程涉及从公开听证会转录文本中提取关键信息,并通过结构化摘要和自然语言推理任务进行标注。
特点
PublicHearingBR数据集的特点在于其专注于巴西葡萄牙语的公开听证会转录文本,提供了丰富的结构化信息。长文档摘要部分包含转录文本、新闻摘要以及元数据,元数据中详细记录了主题、涉及人员及其观点。自然语言推理部分则通过实验生成的结构化数据,提供了观点、邻近文本块以及幻觉验证信息,能够有效支持复杂的推理任务。
使用方法
使用PublicHearingBR数据集时,可通过`load_dataset.py`脚本加载数据并查看其结构。对于长文档摘要任务,用户可以访问每个样本的转录文本、摘要及元数据,元数据中包含主题和涉及人员的详细信息。对于自然语言推理任务,用户可以分析观点、邻近文本块以及幻觉验证结果,验证观点是否可从文本中推断。数据集的使用方法灵活,适用于多种自然语言处理任务的研究与开发。
背景与挑战
背景概述
PublicHearingBR数据集由Leandro Carísio Fernandes等人于2024年创建,旨在为巴西葡萄牙语的长文档摘要和自然语言推理任务提供支持。该数据集包含公共听证会转录文本,涵盖了206个长文档摘要样本和4,238个自然语言推理样本。通过提供详细的元数据,如主题、涉及人员及其观点,该数据集为研究者在处理复杂文本时提供了丰富的上下文信息。PublicHearingBR的发布不仅填补了葡萄牙语领域在长文档摘要和自然语言推理任务上的数据空白,还为相关领域的模型训练和评估提供了重要资源。
当前挑战
PublicHearingBR数据集在构建和应用过程中面临多重挑战。首先,长文档摘要任务要求模型能够从冗长的听证会转录文本中提取关键信息,这对模型的上下文理解和信息压缩能力提出了极高要求。其次,自然语言推理任务需要模型能够准确判断观点是否可以从给定文本中推断出来,这对模型的逻辑推理和语义理解能力构成了挑战。此外,数据集的构建过程中,如何确保转录文本的准确性和元数据的完整性也是一大难题,尤其是在涉及多人物和复杂观点的场景下。最后,数据集的多样性和代表性也需要在未来的扩展中进一步优化,以提升其在实际应用中的泛化能力。
常用场景
经典使用场景
PublicHearingBR数据集在巴西葡萄牙语的长文档摘要生成和自然语言推理任务中展现了其独特价值。该数据集通过提供公共听证会转录文本及其摘要,为研究人员提供了一个标准化的测试平台,特别适用于评估和优化长文档摘要生成模型。其结构化的元数据进一步支持了自然语言推理任务,使得模型能够从复杂文本中提取关键信息并进行推理。
解决学术问题
PublicHearingBR数据集有效解决了长文档摘要生成和自然语言推理中的关键学术问题。在长文档摘要生成方面,数据集提供了丰富的公共听证会转录文本及其对应的摘要,帮助研究人员开发更精确的摘要生成算法。在自然语言推理方面,数据集通过提供详细的元数据和推理验证,支持模型从复杂文本中提取和验证信息,推动了自然语言处理领域的技术进步。
衍生相关工作
PublicHearingBR数据集催生了一系列相关研究,特别是在长文档摘要生成和自然语言推理领域。基于该数据集的研究工作不仅优化了现有的摘要生成模型,还推动了自然语言推理技术的发展。例如,研究人员利用该数据集开发了新的推理验证方法,提高了模型从复杂文本中提取信息的准确性。这些工作进一步扩展了数据集的应用范围,为相关领域的研究提供了新的思路。
以上内容由遇见数据集搜集并总结生成


