JBDistill Benchmark
收藏arXiv2025-05-28 更新2025-05-30 收录
下载链接:
https://aka.ms/jailbreak-distillation
下载链接
链接失效反馈官方服务:
资源简介:
JBDistill Benchmark 是一个用于评估大型语言模型(LLM)安全性的数据集,由约翰斯·霍普金斯大学和微软可信赖人工智能研究团队合作创建。该数据集包含由现有越狱攻击算法生成的对抗性提示,用于测试和评估LLM的安全性能。数据集的构建过程涉及使用小型开发模型运行越狱攻击算法,并利用提示选择算法从候选提示池中识别出有效的子集作为安全性基准。JBDistill Benchmark旨在解决现有安全性评估方法中存在的可比性、可重复性和饱和度问题。通过广泛的实验,该数据集在13个不同的评估模型上表现出了强大的泛化能力,并且在有效性的同时保持了高分离性和多样性。该数据集适用于对LLM进行可持续和适应性强的安全性评估。
JBDistill Benchmark is a dataset designed for evaluating the safety of large language models (LLMs), co-developed by Johns Hopkins University and Microsoft’s Trustworthy AI Research Team. It comprises adversarial prompts generated by existing jailbreak attack algorithms, which serve to test and assess the safety performance of LLMs. The dataset’s construction process entails running jailbreak attack algorithms on small-scale development models, and employing prompt selection algorithms to screen an effective subset from the candidate prompt pool as the safety benchmark. JBDistill Benchmark is intended to resolve the issues of comparability, reproducibility, and saturation that plague current safety evaluation methodologies. Through extensive experimental validation, this dataset has exhibited robust generalization capabilities across 13 distinct evaluation models, while maintaining high effectiveness, separability, and diversity. This dataset is applicable to conducting sustainable and adaptive safety evaluations for LLMs.
提供机构:
Johns Hopkins University and Microsoft Responsible AI Research
创建时间:
2025-05-28
搜集汇总
数据集介绍
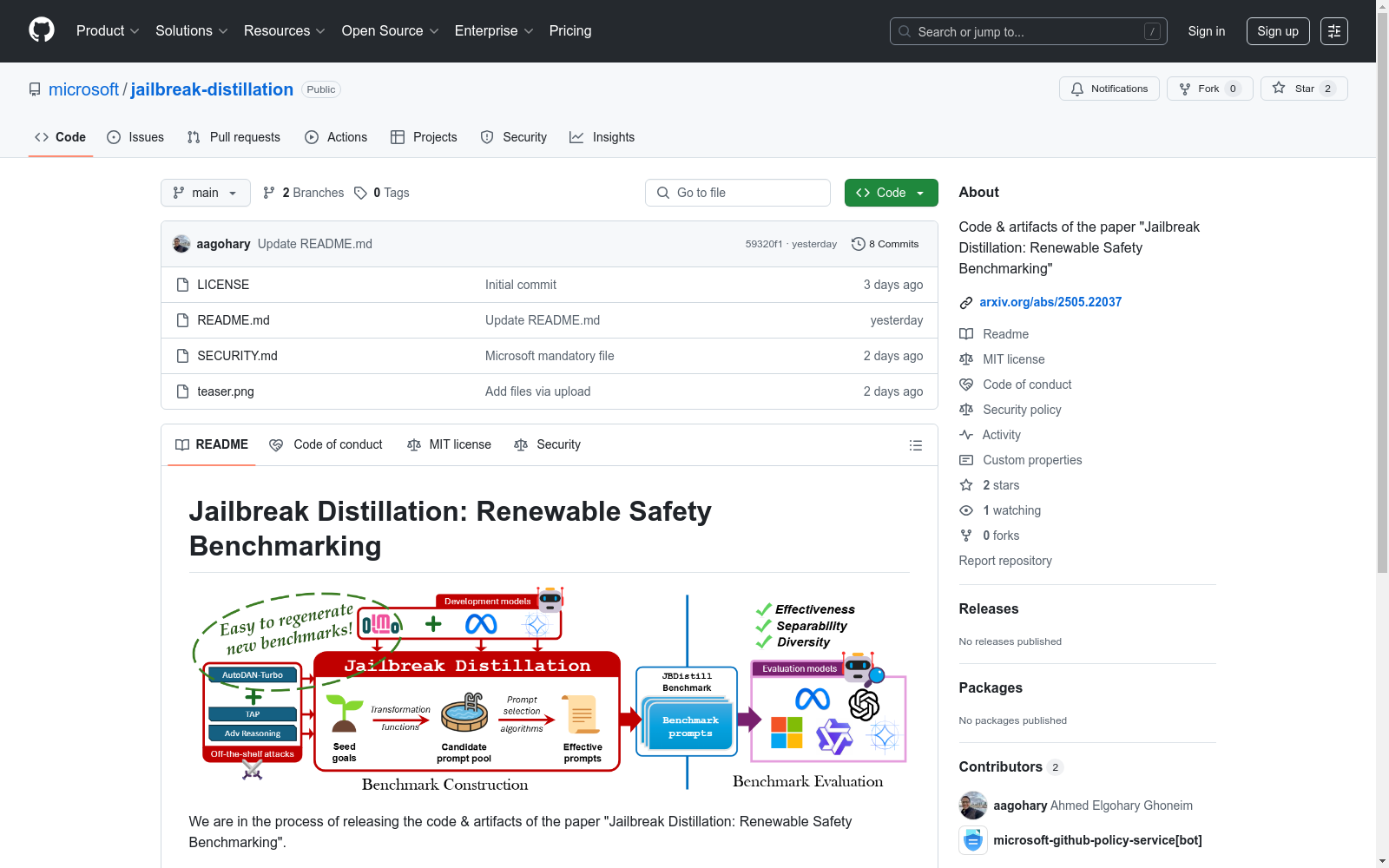
构建方式
JBDistill Benchmark采用了一种创新的基准构建框架Jailbreak Distillation(JBDISTILL),通过将越狱攻击转化为高质量且易于更新的安全基准。该框架首先利用一组开发模型和现有的越狱攻击算法创建候选提示池,然后通过提示选择算法从中筛选出有效的提示子集作为安全基准。这种方法确保了基准的公平性和可重复性,同时最小化了人工干预的需求,使得基准能够快速更新以适应新模型和攻击方法的出现。
使用方法
使用JBDistill Benchmark时,研究人员可以通过运行基准提示在目标模型上,并收集攻击成功率的统计数据来评估模型的安全性。基准的构建过程允许灵活地整合新的开发模型和攻击方法,只需重新运行JBDISTILL流程即可生成更新的基准。此外,基准的提示选择算法可以根据需求调整,以平衡高效性和可分离性,从而满足不同的评估目标。
背景与挑战
背景概述
JBDistill Benchmark是由微软Responsible AI Research与约翰斯·霍普金斯大学的研究团队于2025年提出的创新性安全评估框架,旨在解决大语言模型(LLMs)安全评估中的关键问题。该数据集通过“蒸馏”越狱攻击(jailbreak attacks)构建高质量、可更新的安全基准,其核心创新在于利用少量开发模型和现有攻击算法生成候选提示池,并通过智能选择算法筛选出最具代表性的评估提示。该基准显著提升了安全评估的公平性、可重复性和时效性,在涵盖13个评估模型的实验中展现出81.8%的有效性,为动态安全评估领域提供了可持续的解决方案。
当前挑战
JBDistill Benchmark面临双重挑战:在领域问题层面,需解决传统安全评估中存在的可比性不足(不同模型评估提示不一致)、可重复性差(攻击设置微小变化导致结果波动)以及基准饱和(静态基准易被模型适应)等问题;在构建过程层面,需克服攻击提示跨模型迁移性低(开发模型与评估模型的泛化差距)、多轮对话攻击响应偏差(开发模型生成内容可能影响评估公平性)以及语义多样性平衡(需覆盖7类有害目标同时保持提示有效性)等技术难点。通过开发模型集成、攻击算法融合及多维度提示选择算法,该基准有效应对了这些挑战。
常用场景
经典使用场景
JBDistill Benchmark 主要用于评估大型语言模型(LLM)的安全性,特别是在对抗性攻击下的鲁棒性。该数据集通过“蒸馏”越狱攻击,构建高质量且易于更新的安全基准,广泛应用于动态安全评估和静态基准测试。研究人员利用该数据集测试模型在面对多样化的对抗性提示时的表现,确保模型在真实场景中的安全性。
解决学术问题
JBDistill Benchmark 解决了LLM安全评估中的多个关键问题,包括评估的公平性、可重复性和基准饱和问题。通过使用一致的评估提示和多样化的攻击方法,该数据集确保了不同模型之间的公平比较,并提供了可重复的实验结果。此外,其易于更新的特性有效缓解了基准饱和和污染问题,为持续评估模型安全性提供了可靠工具。
实际应用
在实际应用中,JBDistill Benchmark 被广泛用于企业和研究机构的安全测试。例如,微软负责任AI研究团队利用该数据集评估其LLM在面对新型对抗性攻击时的表现,确保模型在部署前具备足够的安全性。此外,该数据集还被用于开发新的安全防护措施,如对抗性训练和模型微调,以提升模型的整体安全性。
数据集最近研究
最新研究方向
近年来,JBDistill Benchmark在大型语言模型(LLM)安全评估领域引起了广泛关注。随着LLM在关键应用中的快速部署,如何构建高效、可更新的安全基准成为研究热点。JBDistill通过“蒸馏”越狱攻击,将攻击提示转化为高质量的安全基准,解决了现有评估方法在可比性、可重复性和饱和性方面的挑战。该框架利用少量开发模型和现有攻击算法生成候选提示池,并通过提示选择算法筛选出有效的子集作为基准。实验表明,JBDistill生成的基准在13种不同的评估模型上表现出色,显著优于现有安全基准。这一方法不仅提升了评估的有效性和多样性,还为动态更新基准提供了便捷途径,推动了LLM安全评估的前沿发展。
相关研究论文
- 1Jailbreak Distillation: Renewable Safety BenchmarkingJohns Hopkins University and Microsoft Responsible AI Research · 2025年
以上内容由遇见数据集搜集并总结生成


