ViDAS
收藏ViDAS Dataset
概述
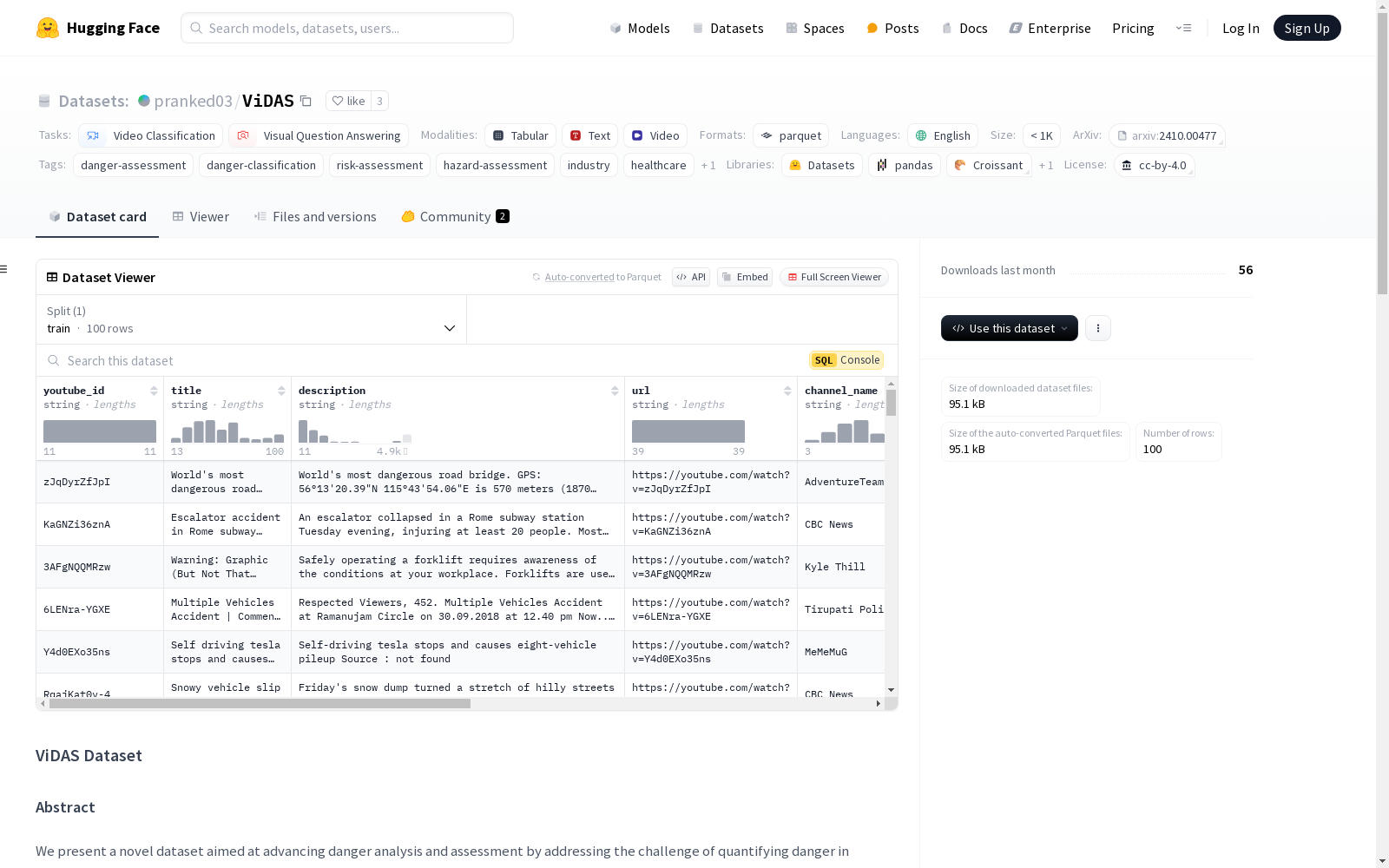
ViDAS数据集旨在通过量化视频内容中的危险程度并评估大型语言模型(LLM)在危险评估中的表现,推动危险分析和评估的发展。该数据集包含100个YouTube视频,每个视频由人类参与者标注,提供了从0(无危险)到10(危及生命)的危险评级,并附有精确的时间戳,指示危险程度高的时刻。此外,利用LLM对这些视频进行独立评估,使用视频摘要来评估危险水平,并引入均方误差(MSE)分数进行多模态元评估,以衡量人类和LLM危险评估之间的一致性。
数据集信息
- 特征:
youtube_id: 字符串title: 字符串description: 字符串url: 字符串channel_name: 字符串duration: 字符串video_id: 字符串video_summary: 字符串rating: 浮点数start_coord: 浮点数end_coord: 浮点数
- 分割:
train: 100个样本,150791字节
- 下载大小: 95057字节
- 数据集大小: 150791字节
- 配置:
default: 包含训练数据文件
- 任务类别:
- 视频分类
- 视觉问答
- 语言: 英语
- 标签:
- 危险评估
- 危险分类
- 风险评估
- 危害评估
- 行业
- 医疗保健
- 危险指标
- 规模类别: n<1K
使用方法
下载和使用数据集
python from datasets import load_dataset
dataset = load_dataset("pranked03/ViDAS")
下载视频并使用OpenCV加载
python i = 0 # 视频索引,范围为0到99
from huggingface_hub import hf_hub_download
file_path = hf_hub_download( repo_id="pranked03/ViDAS", filename=dataset["train"][i]["video_id"], repo_type="dataset" )
import cv2
cap = cv2.VideoCapture(file_path)
if not cap.isOpened(): print("Error: Could not open video.") exit()
while True: ret, frame = cap.read() if not ret: break
cv2.imshow(Video, frame)
if cv2.waitKey(25) & 0xFF == ord(q):
break
cap.release() cv2.destroyAllWindows()
引用
@misc{gupta2024vidasvisionbaseddangerassessment, title={ViDAS: Vision-based Danger Assessment and Scoring}, author={Pranav Gupta and Advith Krishnan and Naman Nanda and Ananth Eswar and Deeksha Agarwal and Pratham Gohil and Pratyush Goel}, year={2024}, eprint={2410.00477}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2410.00477}, }