embed-nemotron-dataset-v1
收藏Embed Nemotron Dataset V1 数据集概述
数据集基本信息
- 数据集名称: Embed Nemotron Dataset V1
- 所有者: NVIDIA Corporation
- 创建日期: 2025年10月21日
- 最新版本日期: 2026年01月05日
- 数据集地址: https://huggingface.co/datasets/nvidia/embed-nemotron-dataset-v1
- 关联模型: llama-embed-nemotron-8b (https://huggingface.co/nvidia/llama-embed-nemotron-8b)
- 技术报告: Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks
- 数据准备脚本: https://github.com/NVIDIA-NeMo/Automodel/blob/main/examples/biencoder/llama_embed_nemotron_8b/data_preparation.py
- 用途限制: 仅供研究和开发使用。
数据集描述
该数据集是用于支持 NVIDIA 发布的 llama-embed-nemotron-8b 模型的高质量微调数据集的汇编。它是训练该模型所用微调数据的一个精选子集,经过精心策划,旨在确保在各种任务上的鲁棒性和高性能。数据集包含来自已建立的公共数据集(如 MIRACL、HotpotQA、MS MARCO 等)的非合成数据,以及为增强任务类型多样性(例如分类)而专门生成的合成数据。每个数据集都经过了复杂的困难负样本挖掘过程处理,以最大化学习信号。
数据集组成与量化
- 子数据集总数: 14
- 总查询样本数: 3,662,695
- 总文档样本数: 9,118,599
- 总数据大小: 2.3 GB (2,314.4 MB)
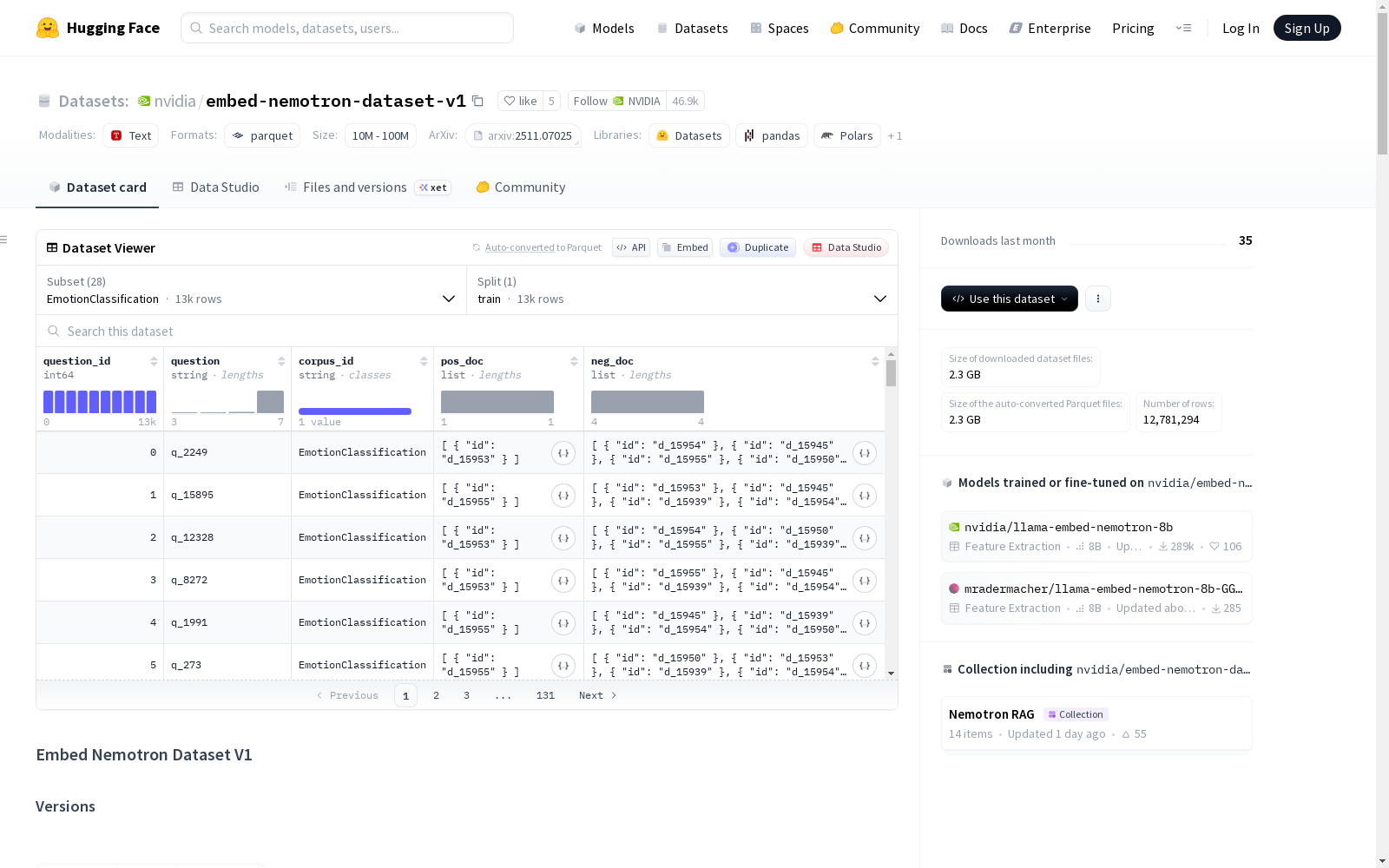
子数据集详情
| 数据集名称 | 任务类型 | 样本数 (查询/文档) | 大小 (MB) | 许可协议 | 数据来源 |
|---|---|---|---|---|---|
| EmotionClassification | 分类 | 13,039 / 6 | 0.2 | 未指定 | 公开数据 |
| FEVER | 检索 | 140,085 / 235,948 | 118.2 | CC BY-SA 4.0 | 公开数据 |
| GooAQ | 检索 | 100,000 / 86,393 | 5.5 | 未指定 | 公开数据 |
| HotpotQA | 检索 | 170,000 / 754,756 | 21.4 | 未指定 | 公开数据 |
| MAmmoTH2 | 检索 | 317,180 / 317,205 | 27.8 | 未指定 | 公开数据 |
| MIRACL | 检索 | 79,648 / 2,571,803 | 1,480.0 | CC BY-SA 4.0 | 公开数据 |
| MSMARCO | 检索 | 532,751 / 3,672,883 | 80.6 | 未指定 | 公开数据 |
| NFCorpus | 检索 | 3,685 / 3,573 | 0.2 | 未指定 | 公开数据 |
| NaturalQuestions | 检索 | 100,231 / 75,215 | 5.1 | 未指定 | 公开数据 |
| PAQ | 检索 | 1,000,000 / 932,307 | 108.0 | 未指定 | 公开数据 |
| SQuAD | 检索 | 87,599 / 18,891 | 3.4 | 未指定 | 公开数据 |
| SciFact | 检索 | 919 / 3,255 | 0.1 | 未指定 | 公开数据 |
| SyntheticClassificationData | 分类 | 1,044,212 / 382,227 | 440.1 | CC BY 4.0 | 合成数据 |
| TriviaQA | 检索 | 73,346 / 64,137 | 3.8 | 未指定 | 公开数据 |
标签说明:
- 公开数据: 数据来源于其他公开数据集。
- 合成数据: 数据为合成生成。SyntheticClassificationData 数据集使用以下模型生成:
meta-llama/Llama-3.3-70B-Instruct、meta-llama/Llama-4-Scout-17B-16E-Instruct和meta-llama/Llama-4-Maverick-17B-128E-Instruct。
许可与使用条款
- 总体条款: 本数据集中每个数据集的使用受其附带许可协议约束。
- 特定许可:
FEVER和MIRACL数据集受 Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0) 约束。SyntheticClassificationData数据集受 Creative Commons Attribution 4.0 International License (CC BY 4.0) 约束。
- 合成数据附加信息: 若使用
SyntheticClassificationData数据集创建、训练、微调或以其他方式改进 AI 模型并分发或提供该模型,则该 AI 模型可能须遵守 Llama 3.3 Community License Agreement 和 Llama 4 Community License Agreement 中的再分发和使用要求。
数据特征
- 数据收集方法: 混合(合成、自动、人工)
- 标注方法: 混合(合成、自动、人工)
数据格式
每个给定的数据集包含两部分:
- 查询集 (Queries):
question_id: 查询IDquestion: 查询文本(如果未直接重新分发文本,则为查询ID)corpus_id: 数据集名称pos_doc: 给定查询的正文档列表neg_doc: 给定查询的负文档列表
- 语料库 (Corpus):
id: 与查询集中pos_doc和neg_doc列表对应的文档IDtext(可选): 如果文本被直接重新分发,则为文档文本
预期用途
该数据集旨在供社区用于持续改进开源模型。数据可自由用于训练和评估。
使用框架
数据已准备就绪,可与 NeMo AutoModel 框架一起使用。要准备数据并开始训练模型,请遵循 此处 提供的步骤。
引用
@misc{babakhin2025llamaembednemotron8buniversaltextembedding, title={Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks}, author={Yauhen Babakhin and Radek Osmulski and Ronay Ak and Gabriel Moreira and Mengyao Xu and Benedikt Schifferer and Bo Liu and Even Oldridge}, year={2025}, eprint={2511.07025}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2511.07025}, }
伦理考量
NVIDIA 认为 可信赖的 AI 是一项共同责任,并已制定政策和实践以支持广泛的 AI 应用开发。开发者在根据服务条款下载或使用本数据集时,应与其内部模型团队合作,确保该数据集满足相关行业和用例的要求,并解决不可预见的产品误用问题。