OGB/ogbg-ppa
收藏Hugging Face2023-02-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/OGB/ogbg-ppa
下载链接
链接失效反馈官方服务:
资源简介:
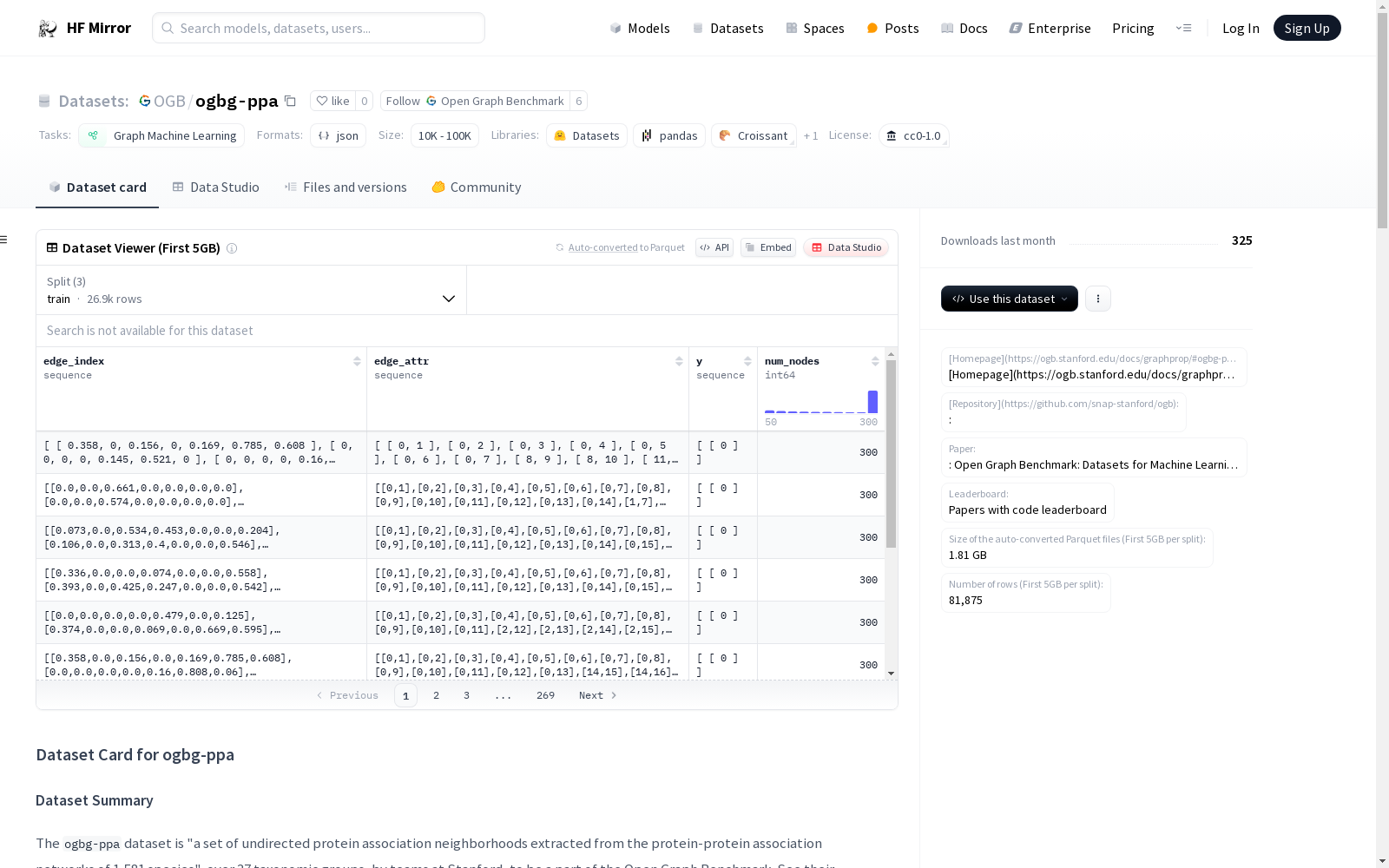
`ogbg-ppa`数据集是从1,581个物种的蛋白质-蛋白质关联网络中提取的一组无向蛋白质关联邻域,涵盖了37个分类群。该数据集是Open Graph Benchmark的一部分,旨在用于分类群预测任务,即37类多分类任务。数据集包含158,100个图,平均每个图有243.4个节点和2,266.1条边,平均节点度为18.3,平均聚类系数为0.513。每个图的数据包括边的索引、边的属性、标签和节点数量。数据集已按照PyGeometric版本提供的数据分割进行划分。
The `ogbg-ppa` dataset is a collection of undirected protein association neighborhoods extracted from protein-protein association networks of 1,581 species, covering 37 taxonomic groups. It is part of the Open Graph Benchmark, targeting taxon prediction tasks, a 37-class multi-classification problem. The dataset contains 158,100 graphs, with an average of 243.4 nodes and 2,266.1 edges per graph, an average node degree of 18.3, and an average clustering coefficient of 0.513. Each graph includes edge indices, edge attributes, ground-truth labels, and the number of nodes. The dataset has been split according to the data splits provided in the PyGeometric version.
提供机构:
OGB
原始信息汇总
数据集概述
数据集名称
- ogbg-ppa
数据集摘要
ogbg-ppa数据集是由斯坦福团队从1,581种物种的蛋白质-蛋白质关联网络中提取的不定向蛋白质关联邻域集合,涵盖37个分类群组,作为开放图基准的一部分。
支持的任务和排行榜
- 任务类型:分类任务
- 具体任务:分类群组预测,37类多分类任务
- 评估指标:测试集上的平均精度
数据集结构
数据属性
- 规模:小
- 图数量:158,100
- 平均节点数:243.4
- 平均边数:2,266.1
- 平均节点度:18.3
- 平均聚类系数:0.513
- 最大强连通分量比率:1.000
- 图直径:4.8
数据字段
edge_index:边索引,2 x #edgesedge_attr:边属性,#edges x #edge-featuresy:标签,1 x #labelsnum_nodes:节点数
许可证信息
- 许可证:CC0-1.0
引用信息
@inproceedings{hu-etal-2020-open, author = {Weihua Hu and Matthias Fey and Marinka Zitnik and Yuxiao Dong and Hongyu Ren and Bowen Liu and Michele Catasta and Jure Leskovec}, editor = {Hugo Larochelle and Marc Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin}, title = {Open Graph Benchmark: Datasets for Machine Learning on Graphs}, booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual}, year = {2020}, url = {https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html}, }
贡献者
- 感谢 @clefourrier 添加此数据集。
搜集汇总
数据集介绍
构建方式
OGB/ogbg-ppa数据集的构建,是基于蛋白质-蛋白质关联网络,从中提取了1581个物种的蛋白质关联邻域。该数据集的构建涉及了多个物种的蛋白质交互信息,并在斯坦福大学团队的努力下,成为开放图基准(Open Graph Benchmark)的一部分。数据集经过特定的后处理,以确保其适用于机器学习任务。
特点
该数据集的特点在于其包含了来自37个分类群的蛋白质关联网络,具有多样性和广泛性。数据集规模适中,包含158,100个图,平均节点数为243.4,平均边数为2,266.1,平均节点度为18.3,平均聚类系数为0.513,显示出较高的网络连通性。此外,数据集遵循CC-0协议开源,便于研究者自由使用和分享。
使用方法
使用OGB/ogbg-ppa数据集时,可以利用PyGeometric库进行加载。首先,通过load_dataset函数加载数据集,然后使用PyGeometric的Data和DataLoader类来处理图数据。数据集提供了训练、验证和测试集的索引,可以通过get_idx_split函数获取,进而按照需求加载不同的数据集部分。
背景与挑战
背景概述
在蛋白质-蛋白质相互作用网络的研究领域,准确地预测蛋白质的功能与相互作用对于理解生物系统的基本机制至关重要。`ogbg-ppa`数据集,由斯坦福大学的团队创建于2020年,作为Open Graph Benchmark的一部分,包含了来自1,581种生物体的无向蛋白质关联邻域,跨越了37个分类群。该数据集旨在为分类学群预测任务提供基准,即一个37类的多分类任务,其核心研究问题是如何准确地从蛋白质网络的图结构中预测分类学群。该数据集的发布对机器学习在图结构数据处理领域的研究产生了重要影响,促进了相关算法和模型的发展。
当前挑战
在构建`ogbg-ppa`数据集的过程中,研究人员面临了诸多挑战。首先,蛋白质-蛋白质相互作用网络的复杂性导致数据预处理和特征提取的难度增加。其次,数据集的构建需要解决如何平衡不同分类群中蛋白质数量的不平衡问题,以及如何在保持数据真实性的同时确保数据的质量和一致性。在研究领域问题方面,该数据集的挑战在于如何设计出能够有效捕捉图结构特征并准确预测分类学群的机器学习模型,同时,评估模型的性能也是一个持续的挑战,特别是在面对大规模和高复杂度的生物网络数据时。
常用场景
经典使用场景
在生物信息学的领域中,ogbg-ppa数据集被广泛应用于蛋白质关联网络的研究。该数据集的核心使用场景在于预测蛋白质之间的关联性,进而对生物分子之间的交互进行深入分析。通过机器学习模型在ogbg-ppa数据集上进行训练,研究者能够预测蛋白质是否属于同一复合体,这对于理解蛋白质的功能和生物分子路径至关重要。
衍生相关工作
ogbg-ppa数据集的发布促进了众多相关工作的开展。研究者基于该数据集开发了多种机器学习模型和方法,如图神经网络,以更准确地预测蛋白质关联性。此外,该数据集还激发了关于图机器学习在生物信息学中应用的研究,推动了生物信息学领域的跨学科发展。
数据集最近研究
最新研究方向
在生物信息学领域,ogbg-ppa数据集作为蛋白质关联网络的一种重要资源,其研究方向的最新进展主要集中于利用图机器学习技术进行物种分类预测。该数据集的微观结构特性,如平均节点度、聚类系数等,为算法设计提供了独特的挑战。目前,前沿研究正聚焦于提升分类精度,特别是在多分类任务中实现高效的taxonomic group预测。这些研究不仅推动了生物信息学领域的知识发现,也为机器学习在生物网络分析中的应用开辟了新路径,具有显著的科学价值和实际意义。
以上内容由遇见数据集搜集并总结生成


