BUAADreamer/llava-en-zh-300k
收藏Hugging Face2024-05-21 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/BUAADreamer/llava-en-zh-300k
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由两部分组成:150k个来自LLaVA的英文视觉指令数据和150k个来自openbmb的英文视觉指令数据。数据集可以在LLaMA Factory中使用,通过指定--dataset llava_150k_en,llava_150k_zh来加载。
This dataset comprises two subsets: 150,000 English visual instruction instances sourced from LLaVA, and 150,000 English visual instruction instances sourced from openbmb. It can be utilized in LLaMA Factory, and loaded by specifying the command-line parameter --dataset llava_150k_en,llava_150k_zh.
提供机构:
BUAADreamer
原始信息汇总
数据集概述
基本信息
- 语言: 英语(en)、中文(zh)
- 许可证: Apache-2.0
- 大小分类: 100K<n<1M
- 任务分类: 文本生成(text-generation)、视觉问答(visual-question-answering)
数据集结构
配置名称: en
- 特征:
- messages:
- role: 数据类型为字符串
- content: 数据类型为字符串
- images: 序列类型为图像
- messages:
- 分割:
- train:
- 字节数: 25249626616.92
- 示例数: 157712
- 下载大小: 25989528670
- 数据集大小: 25249626616.92
- train:
配置名称: zh
- 特征:
- messages:
- role: 数据类型为字符串
- content: 数据类型为字符串
- images: 序列类型为图像
- messages:
- 分割:
- train:
- 字节数: 25215721345.92
- 示例数: 157712
- 下载大小: 25983577288
- 数据集大小: 25215721345.92
- train:
数据文件配置
- 配置名称: en
- 数据文件:
- 分割: train
- 路径: en/train-*
- 数据文件:
- 配置名称: zh
- 数据文件:
- 分割: train
- 路径: zh/train-*
- 数据文件:
标签
- llama-factory
搜集汇总
数据集介绍
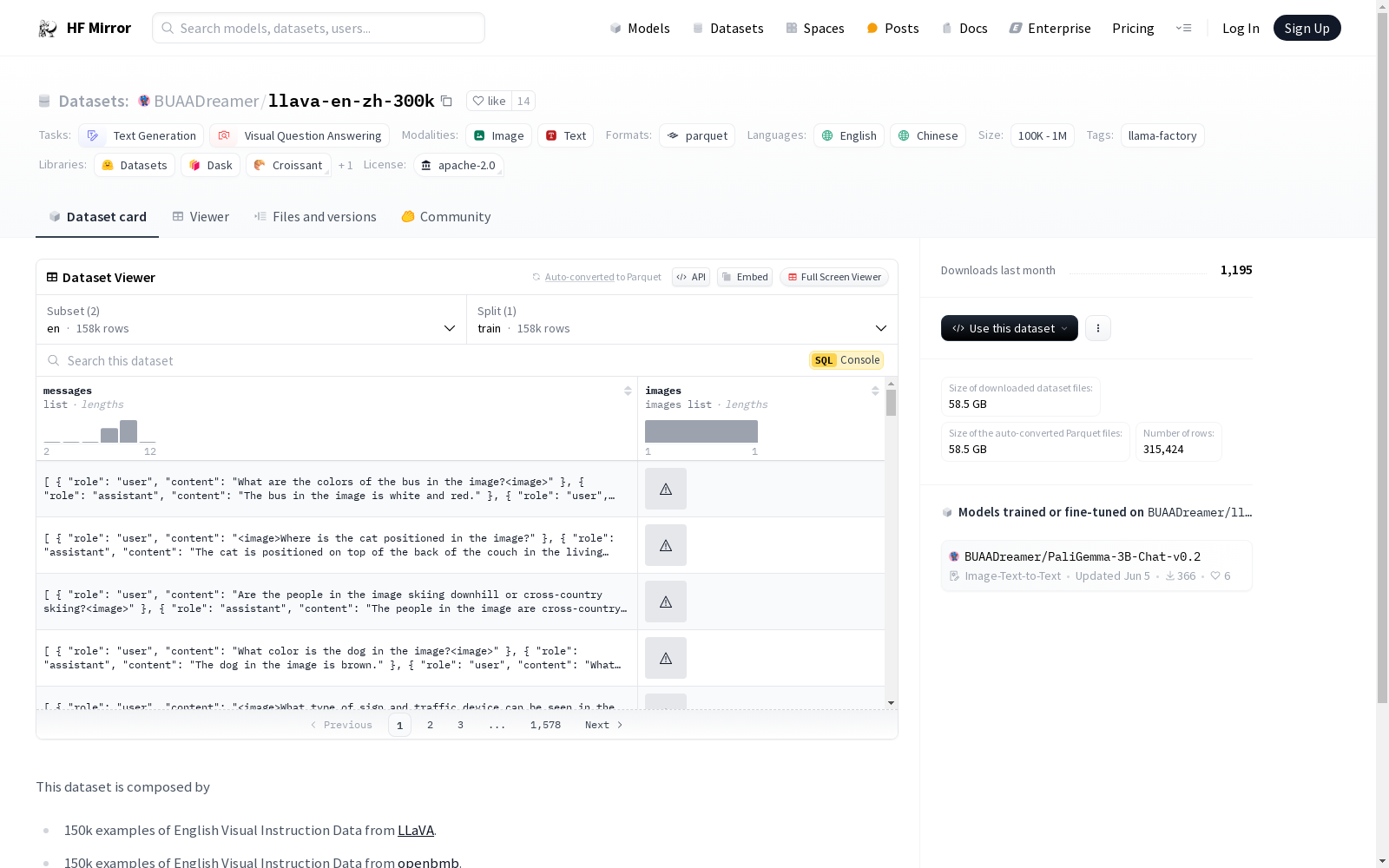
构建方式
BUAADreamer/llava-en-zh-300k数据集的构建基于LLaVA项目和openbmb数据集,分别从这两个来源收集了150,000条英文视觉指令数据和150,000条中文视觉指令数据。数据集的构建过程包括从原始数据源中提取视觉指令数据,并将其整理成统一的格式,以便于后续的文本生成和视觉问答任务。
特点
该数据集的主要特点在于其双语特性,涵盖了英文和中文两种语言的视觉指令数据,为跨语言的视觉问答和文本生成任务提供了丰富的资源。此外,数据集的规模适中,包含300,000条数据,既保证了数据的多样性,又便于在实际应用中进行高效处理。
使用方法
使用BUAADreamer/llava-en-zh-300k数据集时,用户可以通过指定--dataset参数为llava_150k_en,llava_150k_zh,在LLaMA Factory框架中加载该数据集。数据集的结构设计便于直接用于训练和评估视觉问答和文本生成模型,支持多语言模型的开发和优化。
背景与挑战
背景概述
在多模态人工智能领域,视觉问答(Visual Question Answering, VQA)和文本生成任务的结合已成为前沿研究的热点。BUAADreamer/llava-en-zh-300k数据集由BUAA Dreamer团队创建,旨在提供一个大规模的双语(英语和中文)视觉指令数据集,以支持多语言环境下的VQA和文本生成研究。该数据集包含300,000个样本,分别来自LLaVA和openbmb项目,为研究人员提供了一个丰富的资源库,以探索和优化多语言视觉问答系统的性能。
当前挑战
尽管BUAADreamer/llava-en-zh-300k数据集为多语言VQA和文本生成提供了宝贵的资源,但其构建过程中仍面临诸多挑战。首先,跨语言数据的对齐和一致性是一个主要难题,确保不同语言版本的数据在语义和视觉信息上保持一致性至关重要。其次,数据集的规模和多样性要求高效的存储和处理技术,以确保数据的高效利用和模型训练的稳定性。此外,如何确保数据集在不同应用场景下的通用性和适应性,也是当前研究中亟待解决的问题。
常用场景
经典使用场景
在自然语言处理与计算机视觉交叉领域,BUAADreamer/llava-en-zh-300k数据集以其丰富的视觉指令数据和多语言支持,成为视觉问答(Visual Question Answering, VQA)和文本生成任务的经典资源。该数据集通过结合图像与文本信息,训练模型理解并生成与图像内容相关的自然语言描述,极大地推动了多模态学习的发展。
衍生相关工作
基于BUAADreamer/llava-en-zh-300k数据集,研究者们开发了多种多模态学习模型,如LLaVA和LLaMA Factory,这些模型在视觉问答和文本生成任务中表现优异。此外,该数据集还激发了跨语言多模态研究的兴趣,推动了相关领域技术的进一步创新与发展。
数据集最近研究
最新研究方向
在视觉问答与文本生成领域,BUAADreamer/llava-en-zh-300k数据集的最新研究方向主要集中在跨语言视觉指令数据的融合与应用。该数据集通过整合来自LLaVA和openbmb的15万条英文和中文视觉指令数据,为多语言环境下的视觉问答系统提供了丰富的训练资源。研究者们正探索如何利用这一数据集提升多语言视觉问答模型的性能,特别是在处理复杂视觉场景和多语言指令时的表现。此外,该数据集的应用还扩展到跨语言的文本生成任务,旨在通过视觉信息增强文本生成的准确性和多样性。这些研究不仅推动了视觉问答技术的发展,也为跨语言人工智能系统的构建提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


