AiresPucrs/breast-cancer-wisconsin
收藏Hugging Face2024-10-13 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/AiresPucrs/breast-cancer-wisconsin
下载链接
链接失效反馈官方服务:
资源简介:
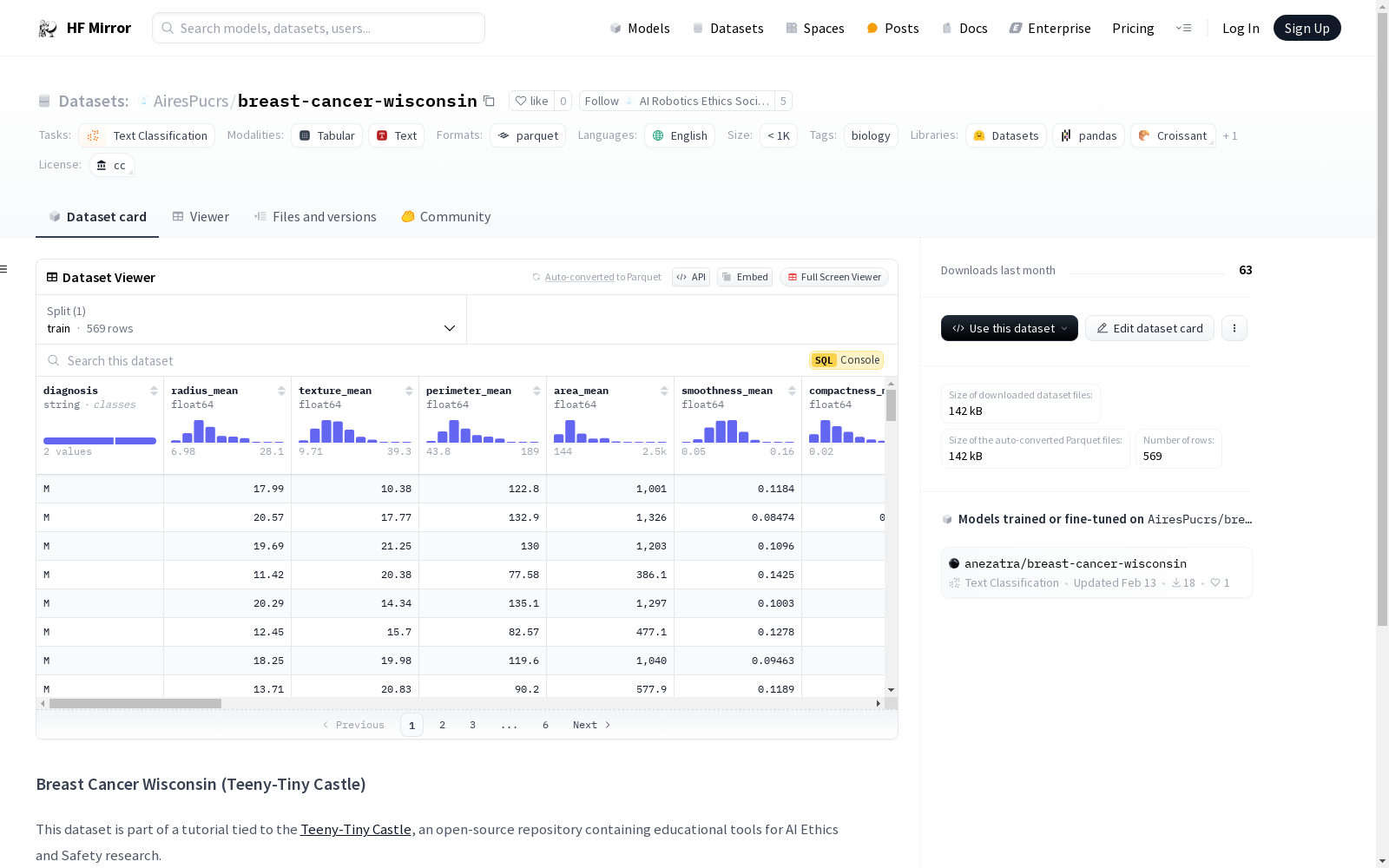
该数据集包含从乳腺癌活检的数字化图像中计算出的特征,用于预测乳腺肿块是良性(非癌性)还是恶性(癌性)。数据集基于从乳腺肿块组织样本的数字化图像中计算出的特征,这些特征是从乳腺肿块的细针穿刺(FNA)图像中提取的。基于这些特征,目标是预测肿块是良性还是恶性。数据集总共有569个样本,分为训练集。
This dataset comprises computed features extracted from digitized images of breast cancer biopsies, intended to predict whether breast masses are benign (non-cancerous) or malignant (cancerous). The features are derived from digitized images of breast mass tissue samples, which were extracted from fine-needle aspiration (FNA) images of breast masses. The goal of this task is to classify each mass as benign or malignant using these features. The dataset has a total of 569 samples, which are divided into the training set.
提供机构:
AiresPucrs
原始信息汇总
数据集概述
数据集名称
- 名称:breast-cancer-wisconsin
语言
- 语言:英语
数据集大小
- 示例数量:569
- 数据集大小:139405字节
- 下载大小:141996字节
数据集内容
- 特征数量:30个特征 + 1个诊断标签
- 诊断标签分布:Malignant (37.3%), Benign (62.7%)
数据集特征
- 特征包括:
- 诊断(字符串类型)
- 多个与肿瘤相关的统计特征(均为浮点数类型,如平均半径、纹理、周长、面积等)
数据集划分
- 训练集:569个示例,139405字节
许可证
- 许可证:Creative Commons Attribution 4.0 International (CC BY 4.0)
搜集汇总
数据集介绍
构建方式
在构建AiresPucrs/breast-cancer-wisconsin数据集时,研究者们精心收集了来自威斯康星大学麦迪逊分校的乳腺癌诊断数据。该数据集包含了569个样本,每个样本均详细记录了30个与乳腺癌相关的特征,如半径、纹理、周长、面积等。这些特征通过均值、标准误差和最差值三个维度进行量化,确保了数据的全面性和细致性。数据集的构建过程严格遵循科学方法,旨在为乳腺癌的早期诊断和治疗提供可靠的数据支持。
特点
AiresPucrs/breast-cancer-wisconsin数据集的显著特点在于其高度的专业性和细致性。数据集不仅涵盖了多种与乳腺癌相关的生物学特征,还通过多维度的量化方式,如均值、标准误差和最差值,全面反映了肿瘤的特性。此外,数据集的标签明确,诊断结果以字符串形式记录,便于机器学习模型的训练和验证。这些特点使得该数据集在乳腺癌研究和临床应用中具有重要的价值。
使用方法
使用AiresPucrs/breast-cancer-wisconsin数据集时,用户可以通过HuggingFace的datasets库轻松加载数据。具体操作如下:首先,导入datasets库并调用load_dataset函数,指定数据集名称和分割方式(如'train')。加载后的数据集可直接用于机器学习模型的训练和评估。该数据集的结构清晰,特征丰富,适用于多种乳腺癌相关的研究任务,如分类、回归和特征选择等。
背景与挑战
背景概述
乳腺癌作为全球女性最常见的恶性肿瘤之一,其早期诊断和治疗对于提高患者生存率至关重要。AiresPucrs/breast-cancer-wisconsin数据集由AiresPucrs机构创建,旨在通过提供详细的乳腺肿瘤特征数据,推动乳腺癌的早期诊断研究。该数据集包含了569个样本,每个样本具有30个特征,涵盖了肿瘤的平均、标准误差和最差值等多个维度。这些数据不仅为医学研究提供了宝贵的资源,也为机器学习算法在乳腺癌诊断中的应用奠定了基础。
当前挑战
尽管AiresPucrs/breast-cancer-wisconsin数据集在乳腺癌研究中具有重要价值,但其构建和应用过程中仍面临诸多挑战。首先,数据集的样本量相对较小,可能限制了模型的泛化能力。其次,数据集中的特征维度较高,如何有效地进行特征选择和降维,以提高模型的预测精度,是一个亟待解决的问题。此外,数据集的标签分布可能存在不平衡现象,这要求研究者在模型训练过程中采取适当的策略,以避免模型对多数类别的过度拟合。
常用场景
经典使用场景
在生物医学领域,AiresPucrs/breast-cancer-wisconsin数据集的经典使用场景主要集中在乳腺癌的诊断与预测。通过分析数据集中包含的多种生物特征,如肿瘤的平均半径、质地、周长等,研究者能够构建高效的机器学习模型,从而实现对乳腺癌的早期检测和分类。这种基于数据驱动的诊断方法,不仅提高了诊断的准确性,还为临床医生提供了有力的辅助工具。
实际应用
在实际应用中,AiresPucrs/breast-cancer-wisconsin数据集被广泛应用于医疗诊断系统。例如,通过集成该数据集的特征,医疗机构可以开发出自动化的乳腺癌筛查工具,帮助医生快速识别高风险病例。此外,该数据集还被用于开发移动应用程序,使患者能够在家中进行初步的自我筛查,从而提高公众对乳腺癌的认知和早期检测率。
衍生相关工作
基于AiresPucrs/breast-cancer-wisconsin数据集,研究者们开展了一系列相关工作。例如,有研究通过深度学习技术对该数据集进行分析,提出了更为复杂的特征提取方法,显著提升了模型的诊断性能。此外,还有研究将该数据集与其他生物医学数据集结合,探索多模态数据融合在乳腺癌诊断中的应用。这些衍生工作不仅丰富了乳腺癌诊断的研究领域,还为未来的临床应用提供了新的思路。
以上内容由遇见数据集搜集并总结生成


