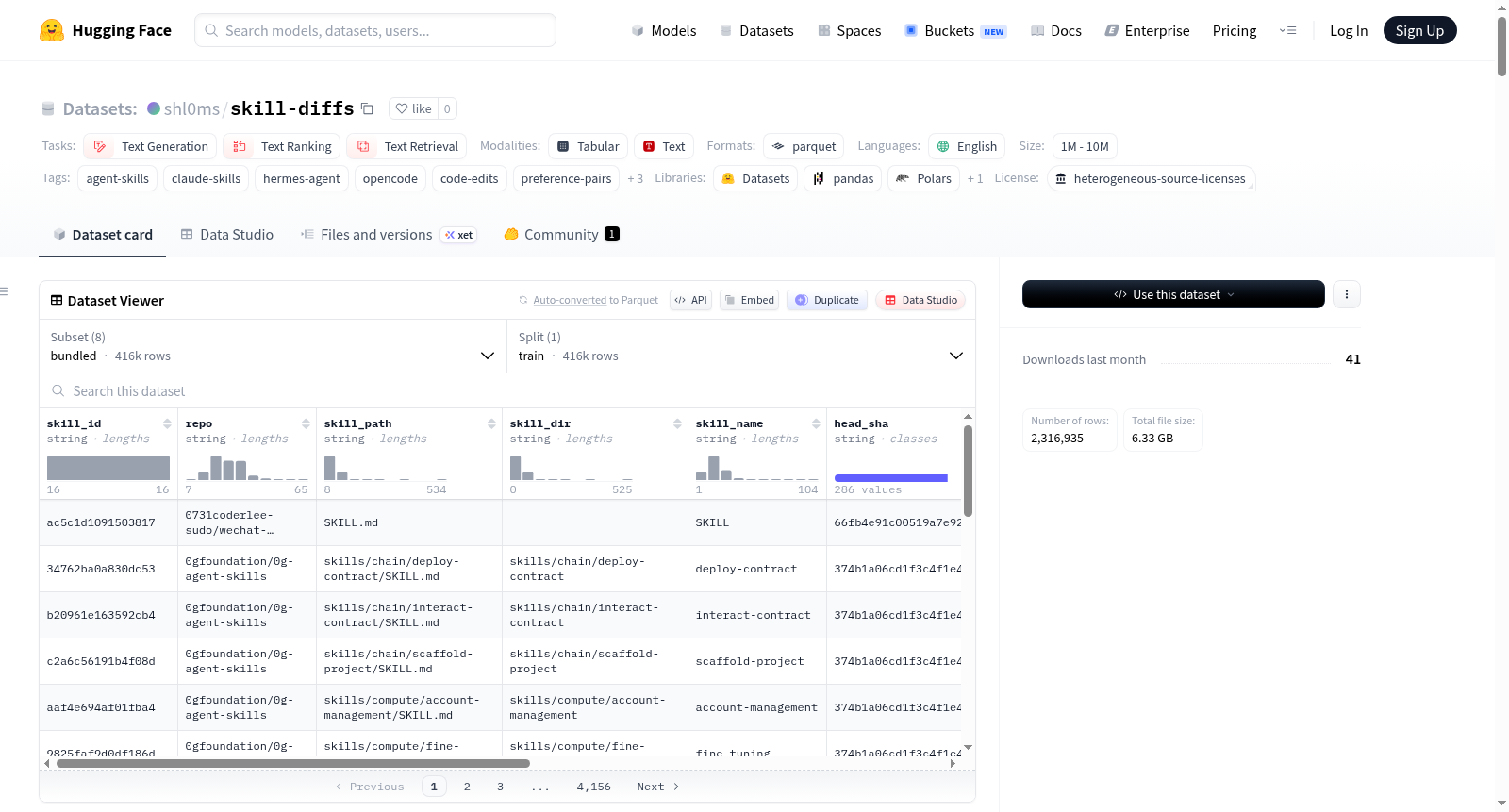
skill-diffs
收藏Hugging Face2026-05-03 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/shl0ms/skill-diffs
下载链接
链接失效反馈官方服务:
资源简介:
skill-diffs数据集是一个多平台的代理技能(SKILL.md文件)修订历史数据集,通过抓取公共GitHub仓库的提交历史记录构建。每个记录包含(before, after, intent)三元组,记录了人类反馈如何迭代优化代理技能。数据集包含七个parquet文件,涵盖原始差异记录、清洗后的差异对、初始技能创建、仓库元数据等。特别提供了一个专门用于微调技能编辑/策展模型的curator_training.parquet子集。数据集适用于多种任务,包括技能编辑器微调、DPO/偏好对训练、模式挖掘、初始状态生成和跨平台分析。数据集包含详细的字段说明和质量标签,并提供了评估基准和统计信息。数据集覆盖四个平台:Anthropic Claude、OpenClaw、OpenCode和Hermes Agent。
The skill-diffs dataset is a multi-platform proxy skill (SKILL.md file) revision history dataset constructed by scraping commit histories from public GitHub repositories. Each record contains a (before, after, intent) triple, documenting how human feedback iteratively optimizes proxy skills. The dataset includes seven parquet files covering raw diff records, cleaned diff pairs, initial skill creations, repository metadata, etc. A special curator_training.parquet subset is provided specifically for fine-tuning skill editing/curation models. The dataset is suitable for various tasks including skill editor fine-tuning, DPO/preference pair training, pattern mining, initial state generation, and cross-platform analysis. It contains detailed field descriptions and quality labels, and provides evaluation benchmarks and statistical information. The dataset covers four platforms: Anthropic Claude, OpenClaw, OpenCode, and Hermes Agent.
创建时间:
2026-05-01
原始信息汇总
数据集概述:skill-diffs
基本信息
- 数据集名称: skill-diffs
- 版本: v0.4.1
- 许可证: 数据集编译采用 CC-BY-4.0,底层 SKILL.md 内容保留源仓库许可证
- 语言: 英语
- 数据规模: 100K < n < 1M
数据集简介
该数据集收录了从公开 GitHub 仓库中抓取的 agent 技能文件(SKILL.md)的逐次提交修订历史。每条记录是一个 (before, after, intent) 三元组,捕捉技能如何通过人类反馈进行迭代优化。
数据覆盖 4 个平台:Anthropic Claude、OpenClaw、OpenCode、Hermes Agent,并新增 PR 标题/正文元数据作为更丰富的意图标签。
文件构成
| 文件名 | 行数 | 描述 |
|---|---|---|
diffs.parquet |
986,515 | 全量逐次提交记录,含初始版本和低质量编辑 |
diffs_clean.parquet |
130,631 | 干净差异对(排除初始版本和默认过滤项) |
skills_initial.parquet |
664,872 | 每个技能的初始提交(创建版本) |
repos.parquet |
5,891 | 按仓库的元数据(许可证、星级、平台等) |
curator_training.parquet |
75,310 | 推荐训练集,专为技能编辑/策展模型微调设计 |
curator_eval_set.parquet |
200 | 留出评估集,用于基准测试 |
bundled.parquet |
415,506 | 技能文件夹的伴随文件(仅限 Anthropic 平台) |
数据用途
- 技能编辑器/策展模型微调:
curator_training.parquet专门为此设计,训练模型根据 (before, intent_text) 生成修补后的技能 - DPO/偏好对训练:(before, after) 配对,after 为人工修正版本
- 模式挖掘:分析技能迭代中最常见的编辑类型
- 初始状态生成:使用
skills_initial.parquet进行“从零创建技能”训练 - 跨平台分析:通过
platform列比较不同平台的技能格式差异 - 完整技能上下文:
bundled.parquet提供技能文件夹的完整内容
数据模式
diffs / diffs_clean / skills_initial 关键列
pair_id: 稳定 SHA1 派生的唯一 IDskill_id: 每个 (repo, skill_path) 的稳定 IDrepo: GitHub 仓库 owner/nameplatform: 平台标识(claude_skill/hermes_skill/opencode_skill/openclaw_skill)before_content/after_content: 提交前后的完整 SKILL.md 内容commit_subject: 提交信息首行intent_class: 意图分类(feat / fix / docs 等 16 类)quality_tags: 质量标签列表,用于过滤低质量数据pr_title/pr_body: 新增的 PR 标题和正文(更丰富的意图标签)is_canonical: 是否为去重后的代表性技能
repos.parquet 关键列
license_spdx: SPDX 许可证标识符stars: GitHub 星标数n_skills/n_records: 各仓库的技能数和记录数
质量标签
| 标签 | 是否过滤 | 含义 |
|---|---|---|
bot_author |
是 | 机器人作者 |
whitespace_change |
是 | 纯空白格式变更 |
revert_subject |
是 | 回退提交 |
pre_revert |
是 | 被后续提交回退 |
merge_commit |
是 | 合并提交 |
duplicate_pair |
是 | 重复对 |
micro_edit |
是 | 微小编辑 |
short_skill |
是 | 技能内容过短 |
invalid_frontmatter |
否 | 缺少合法 YAML 前言 |
same_author_dup |
否 | 相同作者重复 |
duplicate_after |
否 | 相同 after 内容重复 |
large_blob |
否 | 内容超过 200KB |
non_utf8_clean |
否 | 非 UTF-8 编码 |
数据统计
平台分布(干净差异对)
| 平台 | 仓库数 | 干净差异数 | 占比 |
|---|---|---|---|
claude_skill (Anthropic) |
2,774 | 91,355 | 69.9% |
openclaw_skill |
1,368 | 18,149 | 13.9% |
opencode_skill |
1,239 | 15,329 | 11.7% |
hermes_skill |
510 | 5,798 | 4.4% |
PR 元数据覆盖
diffs.parquet: 7.7% 的记录包含 PR 标题diffs_clean.parquet: 18.8% 的记录包含 PR 标题
已知限制
- 大型单仓(17 个 OpenCode 仓库和 91 个 OpenClaw 仓库)因超时被排除
- Cursor 格式暂未提取,推迟至 v0.5
- OpenClaw 仅包含发布到 git 的子集,注册表上的技能未收录
- PR 匹配仅支持 head_sha 和 merge_commit_sha,多提交 PR 的中间提交未匹配
- 仅包含 HEAD 中存在的技能,删除的技能被遗漏
bundled.parquet仅覆盖 Anthropic 平台- 未区分人类编写和 AI 编写的技能
引用
@dataset{skill_diffs_v041_2026, title = {skill-diffs v0.4.1: Multi-platform commit-history dataset of agent skill (SKILL.md) revisions}, year = {2026}, url = {https://huggingface.co/datasets/shl0ms/skill-diffs} }
搜集汇总
数据集介绍
构建方式
该数据集通过系统性地爬取4个平台上5,891个公开GitHub仓库中所有SKILL.md文件的逐次提交历史构建而成。具体流程包括:基于种子仓库列表进行平台扩展,利用部分克隆技术高效提取每个文件的完整修订轨迹,记录每次提交前后内容及元数据;随后通过GitHub API为每个提交匹配对应的拉取请求(PR),以获取更丰富的意图标签。最后,对所有记录进行质量标签标注、MinHash近重复聚类以及SPDX许可证元数据关联,形成结构化的Parquet文件集合。
特点
skill-diffs v0.4.1包含986,515条逐提交记录,覆盖Anthropic Claude、OpenClaw、OpenCode和Hermes Agent四大平台。数据集以(before_content, after_content, intent_text)三元组形式捕获技能文件的迭代演化过程,其中intent_text融合了PR标题与提交信息以提供更精准的编辑意图描述。特别地,该数据集通过质量标签系统区分有效编辑与噪声记录,并提供了严格过滤后的干净子集与专为微调技能编辑/策展模型设计的curator_training.parquet(75,310条),后者已排除初始提交、近重复记录及低质量编辑。
使用方法
数据集提供七大Parquet文件以支持多种训练场景:对于技能编辑模型微调,推荐直接使用curator_training.parquet,配合其contained的intent_text字段输入和before→after映射进行监督学习;对于偏好学习(DPO),可使用diffs_clean.parquet中的(before, after)对作为正例样本;初始技能生成任务则使用skills_initial.parquet中的首次提交内容。配套工具eval_curator.py提供了在curator_eval_set.parquet(200条留出集)上评估模型精确匹配度、编辑距离和语义余弦相似度的基准框架。
背景与挑战
背景概述
在智能体(Agent)系统的演进浪潮中,技能(Skill)作为驱动智能体行为与决策的核心组件,其迭代优化过程蕴含着宝贵的人类反馈信号。然而,现有公开数据集多聚焦于代码差异或通用文本编辑,鲜有系统性地捕捉智能体技能在其生命周期中的版本变迁。skill-diffs数据集应运而生,由研究团队于2026年发布,旨在填补这一空白。该数据集跨越Anthropic Claude、OpenClaw、OpenCode及Hermes Agent四大平台,从5,891个公开GitHub仓库中提取了超过98万条逐提交(commit)的SKILL.md文件修订记录,每条记录以(修改前、修改后、意图)三元组形式呈现,揭示了人类如何通过迭代反馈精炼智能体技能。这一资源为偏好对训练(DPO)、技能编辑模型微调及跨平台编辑模式挖掘提供了前所未有的数据基础,在智能体技能工程领域具有奠基性意义。
当前挑战
智能体技能编辑领域面临的核心挑战在于,现有模型(如Claude Haiku 4.5)在技能补丁任务上表现孱弱,其编辑距离比率甚至逊于恒等映射基线(0.7701对0.8431),且精确匹配率仅为1%,表明通用语言模型难以捕捉人类对技能结构的精细修正。此外,数据集构建本身亦障碍重重:跨平台技能格式虽统一但惯例各异,需从海量Git仓库中逐文件提取历史版本;近6000个仓库中17个OpenCode与91个OpenClaw仓库因单仓库提交量过大(超过5000次提交)导致提取超时;OpenClaw技能大量托管于非Git注册表(clawskills.sh),无法被覆盖;拉取请求(PR)匹配限于合并提交SHA与head SHA,未能关联多提交PR中的中间提交;同时,数据集中日益涌现的AI生成与人类编辑的混杂,使编辑意图的区分变得模糊。
常用场景
经典使用场景
在自主智能体技能开发的学术前沿,skill-diffs数据集为研究者提供了一扇洞察技能文件迭代演进的珍贵窗口。该数据集最经典的使用场景是训练技能编辑模型(skill-editor/curator),即利用其精心筛选的curator_training.parquet子集(包含75,310条高质量差分记录),训练一个小型语言模型,令其能够根据给定的技能原始文本(before)和编辑意图文本(intent_text),自动生成修正后的技能文件(after)。这一范式直接对标Hermes Agent框架中的Curator组件,让模型在无需调用大型语言模型进行推理的情况下,自主完成技能修复与优化工作,从而显著降低智能体系统的维护成本与推理延迟。
解决学术问题
在过往的研究中,智能体技能文件的迭代维护长期依赖人工审核或昂贵的大模型API调用,缺乏规模化、结构化的训练数据来驱动自动化。skill-diffs数据集系统性地解决了这一学术困境,它捕获了来自4个主流平台(Anthropic Claude、OpenClaw、OpenCode、Hermes Agent)、横跨5,891个代码仓库的986,515条技能文件逐提交演进记录,将同类数据集的规模提升了约85倍。该数据集利用minhash去重算法剔除近重复样本,基于常规提交规范和语言模型对编辑意图进行分类,并通过质量标签体系筛选出高保真的差分对,为偏好对齐训练(DPO)、编辑模式挖掘、跨平台技能格式对比等研究方向提供了坚实的数据基础,推动了智能体技能自主进化这一领域的实证研究。
衍生相关工作
围绕skill-diffs数据集已衍生出一系列具有学术影响力的相关工作。研究者基于其diffs_clean.parquet(包含130,631条干净差分记录)构建了技能编辑模式的分析体系,通过聚类和统计方法揭示了13种最常见的错误模式(如缺失代码块语言标签、过时模型引用等),并开发出无需模型推理的规则化linter工具skill_linter.py,实现了对66.5万条技能文件的高效扫描。配套的评测框架eval_curator.py则建立了技能补全任务的标准化评估基准,包含身份映射(identity)与纯意图(intent_only)等基线方法,以及适配主流API端点的评估接口。这些工具和方法论共同构建了一个完整的技能质量保障技术栈,为后续探索技能文件的可解释性、编辑模式的普适性以及跨平台技能迁移策略提供参考。
以上内容由遇见数据集搜集并总结生成


