Packet Vision Dataset
收藏arXiv2024-12-27 更新2024-12-31 收录
下载链接:
https://romoreira.github.io/packetvision/
下载链接
链接失效反馈官方服务:
资源简介:
Packet Vision数据集由巴西联邦大学的研究团队创建,旨在通过将网络数据包转换为图像来进行流量分类。该数据集包含5797条数据,涵盖四种流量类别:BitTorrent、DNS、VoIP和IoT。数据来源包括通过Wireshark工具捕获的网络数据包,经过处理后生成图像。数据集创建过程包括数据包捕获、十六进制矩阵转换、十进制转换、像素随机化以及RGB通道添加等步骤。该数据集主要用于训练和评估卷积神经网络(CNN)在网络流量分类中的应用,旨在提高网络管理的效率和安全性。
The Packet Vision dataset was developed by a research team from the Federal University of Brazil, with the objective of conducting network traffic classification by converting network packets into images. This dataset contains 5797 data samples, covering four traffic categories: BitTorrent, DNS, VoIP, and IoT. The data is sourced from network packets captured using the Wireshark tool, which are processed to generate corresponding images. The dataset creation workflow includes steps such as packet capture, hexadecimal matrix conversion, decimal conversion, pixel randomization, and RGB channel addition. This dataset is primarily utilized for training and evaluating the application of Convolutional Neural Networks (CNNs) in network traffic classification, aiming to enhance the efficiency and security of network management.
提供机构:
巴西联邦大学维索萨分校和巴西联邦大学乌贝兰迪亚分校
创建时间:
2024-12-27
搜集汇总
数据集介绍
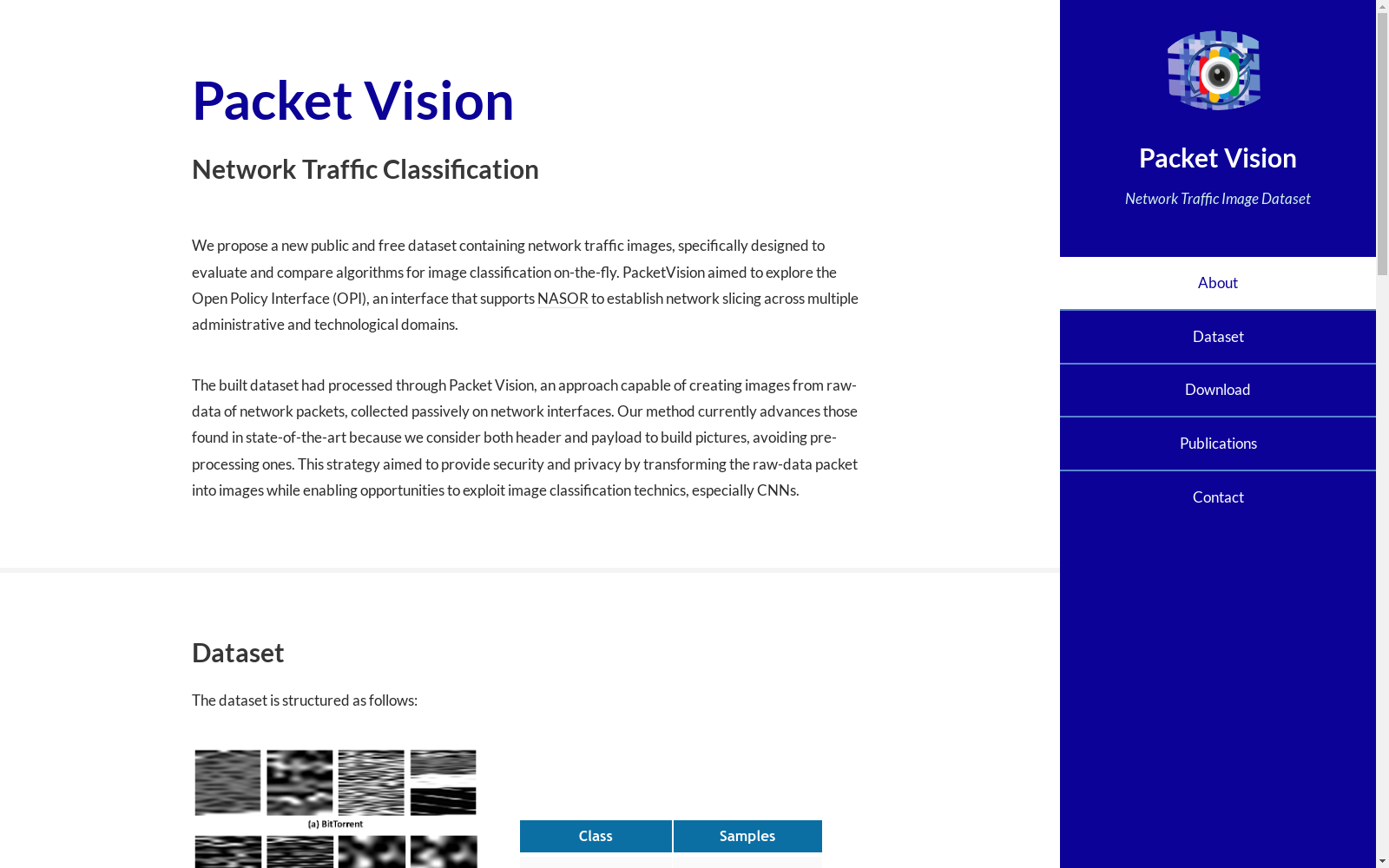
构建方式
Packet Vision数据集的构建基于一种创新的方法,即将网络数据包的原始数据(包括头部和负载)转换为图像。首先,通过开源工具Wireshark捕获网络接口上的数据包,并将其存储为pcap文件。随后,将数据包的原始信息处理为十六进制字节数组,并将其转换为固定列数为8的矩阵。为了适应不同大小的数据包,矩阵的行数可变,并在必要时进行字节填充。接着,将十六进制矩阵转换为十进制,并通过泊松概率分布对矩阵值进行随机化处理,以避免深度学习模型中的偏差和过拟合。最后,将十进制矩阵中的每个值映射为RGB通道,生成PNG格式的图像,这些图像代表了数据包的完整内容。
特点
Packet Vision数据集的特点在于其独特的图像生成机制,能够将网络数据包的原始数据(包括头部和负载)转换为图像,从而为卷积神经网络(CNN)提供适合的输入。该数据集包含四种网络流量类别:BitTorrent、DNS、VoIP和IoT,每种类别都有相应的图像样本。通过将数据包内容转换为图像,Packet Vision不仅提高了网络流量分类的准确性,还增强了数据的安全性和隐私性,因为数据包的原始信息无法直接从图像中推断出来。此外,数据集的构建过程考虑了数据增强和随机化处理,进一步提升了模型的泛化能力。
使用方法
Packet Vision数据集的使用方法主要围绕卷积神经网络(CNN)的训练和评估展开。首先,将生成的图像数据集划分为训练集和测试集,并使用三种经典的CNN架构(AlexNet、ResNet-18和SqueezeNet)进行训练。训练策略包括从头开始训练和基于预训练模型的微调。通过分层k折交叉验证方法,评估每种CNN架构在不同训练策略下的性能,包括准确率、精确率、召回率和F1分数。实验结果表明,Packet Vision方法结合CNN在网络流量分类任务中表现出色,尤其是在从头开始训练的情况下,AlexNet架构取得了最佳性能。此外,SqueezeNet架构在微调策略下表现出较低的计算成本,适合在实际网络环境中应用。
背景与挑战
背景概述
Packet Vision数据集由巴西联邦大学的研究团队于2020年创建,旨在通过卷积神经网络(CNN)技术提升网络流量分类的准确性与效率。该数据集的核心研究问题是如何将网络数据包的原始数据转化为适合CNN处理的图像格式,从而实现对网络流量的智能化分类。研究团队提出的Packet Vision方法,通过将数据包的头部和有效载荷转化为图像,解决了传统方法在安全性和隐私保护方面的不足。该数据集的构建为网络流量分类领域提供了新的思路,尤其是在未来网络架构如5G中,具有重要的应用潜力。
当前挑战
Packet Vision数据集在构建和应用过程中面临多重挑战。首先,网络流量分类本身具有复杂性,尤其是在加密流量日益普及的背景下,传统的基于端口或有效载荷的分类方法已难以应对。其次,将数据包转化为图像的过程中,如何在不泄露敏感信息的前提下保留足够的分类特征,是一个技术难点。此外,数据集的构建需要处理大量异构数据,包括IoT设备、传统互联网应用等,如何确保数据的多样性和代表性也是一个挑战。最后,尽管CNN在图像分类中表现出色,但其在网络流量分类中的应用仍需进一步优化,尤其是在实时性和计算资源消耗方面。
常用场景
经典使用场景
Packet Vision Dataset 最经典的使用场景是网络流量分类,特别是在移动网络和未来网络架构中。通过将网络数据包的原始数据转换为图像,结合卷积神经网络(CNN)技术,该数据集能够高效地识别和分类不同类型的网络应用流量。这种方法不仅提升了网络管理的效率,还为网络服务提供了更加智能化的支持。
衍生相关工作
Packet Vision Dataset 衍生了许多相关的研究工作,特别是在网络流量分类和深度学习领域。例如,基于该数据集的研究提出了多种改进的卷积神经网络架构,如AlexNet、ResNet-18和SqueezeNet,这些架构在流量分类任务中表现出色。此外,该数据集还推动了网络流量图像化处理技术的发展,为未来的网络智能化提供了新的研究方向。
数据集最近研究
最新研究方向
在网络安全与流量分类领域,Packet Vision数据集的最新研究方向聚焦于利用卷积神经网络(CNN)技术对网络流量进行高效分类。通过将网络数据包的原始数据转化为图像,并结合AlexNet、ResNet-18和SqueezeNet等先进的CNN架构,研究者能够在不牺牲安全性和隐私的前提下,实现高精度的流量分类。这一方法不仅突破了传统流量分类技术的局限性,还为未来网络架构(如5G及更高版本)中的智能资源管理提供了新的解决方案。Packet Vision的创新之处在于其能够同时处理数据包的头部和有效载荷,并通过图像生成机制增强数据隐私保护,避免了恶意第三方对原始数据的直接推断。这一研究方向在提升网络服务质量、优化资源分配以及增强网络安全方面具有重要的应用前景。
相关研究论文
- 1Improving the network traffic classification using the Packet Vision approach巴西联邦大学维索萨分校和巴西联邦大学乌贝兰迪亚分校 · 2024年
以上内容由遇见数据集搜集并总结生成


