Mikhailo/ukrainian-tts-audiobooks-24khz-clean
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Mikhailo/ukrainian-tts-audiobooks-24khz-clean
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
- name: lang
dtype: string
splits:
- name: train
num_bytes: 487567715
num_examples: 4751418
- name: dev
num_bytes: 4924913
num_examples: 47994
download_size: 250045805
dataset_size: 492492628
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: dev
path: data/dev-*
---
提供机构:
Mikhailo
搜集汇总
数据集介绍
构建方式
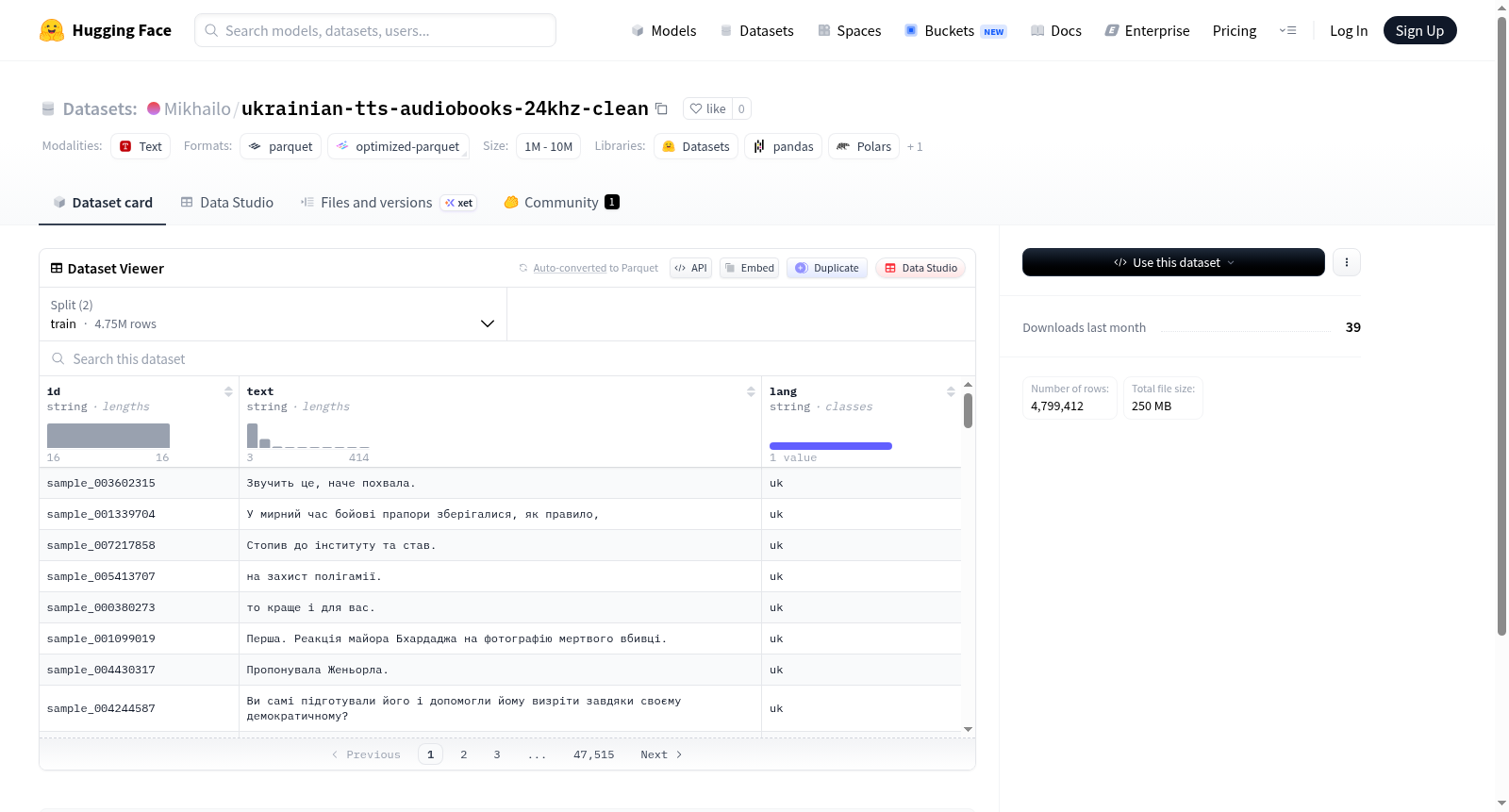
该数据集专为乌克兰语文本转语音(TTS)系统设计,构建过程聚焦于高质量有声读物录音的采集与清洗。原始音频源于乌克兰语有声读物,经过24kHz采样率重采样以确保音质一致性,并通过自动和人工结合的噪声过滤、静音去除及音量归一化处理,形成纯净的语音数据。文本与音频严格对齐,所有语句均标注对应乌克兰语文字,最终整理为统一的JSON格式,包含id、text和lang字段,便于模型直接调用。
特点
数据集包含超过475万条训练样本和约4.8万条验证样本,总数据量约492 MB,规模庞大且覆盖广泛的语言现象。音频统一为24kHz采样率,兼顾音质与计算效率,适合主流TTS框架。文本内容源自文学朗读,语言自然流畅,情感丰富,有助于合成高质量、贴近真人表达的语音。仅含乌克兰语标注,语言纯净,避免了多语种混杂带来的干扰。
使用方法
使用者可通过HuggingFace Datasets库直接加载,指定配置名为default并按需拆分train或dev子集。数据以id、text、lang字段存储,其中text为语音对应的乌克兰语文本,lang固定为'uk'。加载后可将音频与文本配对,用于训练或微调端到端TTS模型(如Tacotron、FastSpeech),也可作为语音识别(ASR)系统的评估基准。推荐将音频预处理为梅尔频谱图,以适配典型神经网络输入格式。
背景与挑战
背景概述
乌克兰语作为东斯拉夫语支的重要语言,其语音技术研究长期受限于高质量标注语料的匮乏。ukrainian-tts-audiobooks-24khz-clean数据集应运而生,由乌克兰研究机构于近年创建,旨在推动乌克兰语文本到语音合成系统的开发。该数据集核心研究问题为提供大规模、高质量、低噪声的乌克兰语音频-文本对,以支撑端到端语音合成模型的训练。通过对有声读物音频进行24kHz采样率标准化处理和精细清洗,该数据集显著降低了背景噪声与口音变异,为乌克兰语语音合成研究奠定了坚实基础。其影响力体现在填补了乌克兰语在TTS领域的资源空白,促进了低资源语言的语音技术发展。
当前挑战
该数据集面临的核心领域挑战是乌克兰语语音合成中多音字、重音模式和韵律建模的复杂性,尤其是合成语音的自然度和情感表达欠缺。在构建过程中,挑战主要源于有声读物语料的多样性:不同录音环境导致噪声分布不均,需设计自适应降噪算法;文本与音频的对齐需处理长句切分和跨段落时间戳校正;此外,数据清洗要平衡去除噪声与保留原始语调细节,避免过度平滑影响模型泛化能力。这些挑战共同决定了数据集的实用性和模型性能上限。
常用场景
经典使用场景
乌克兰语有声书数据集(ukrainian-tts-audiobooks-24khz-clean)为文本到语音(TTS)合成领域提供了珍贵的语料资源。该数据集包含约475万条训练样本和4.8万条验证样本,所有音频均以24kHz采样率进行清晰录制,并配有精准对齐的文本标注。研究者常利用此数据集训练端到端语音合成模型,如Tacotron 2、FastSpeech或VITS等架构,以生成高自然度的乌克兰语语音。其丰富的文本-语音配对内容使得模型能够学习到乌克兰语独特的音系特征、韵律模式及语调变化,从而显著提升合成语音的可懂度与表现力。
实际应用
在实际应用层面,该数据集为构建乌克兰语智能语音助手、无障碍阅读工具以及有声内容生产系统提供了关键支撑。借助该数据集训练的TTS模型,可以广泛应用于有声书自动录制、新闻播报生成、导航语音提示以及教育领域的口语学习软件中。此外,在乌克兰语地区,该数据集助力开发了为视障人士服务的文字转语音应用,提升了信息获取的便捷性。流媒体平台与内容创作者也可利用合成语音技术,低成本、高效率地制作乌克兰语音频内容,促进了乌克兰语数字生态的繁荣与语言文化的传播。
衍生相关工作
该数据集的发布催生了一系列标志性研究工作。其中,基于ukrainian-tts-audiobooks-24khz-clean训练的端到端TTS模型,被作为乌克兰语语音合成的基准系统,用于对比新方法的效果。研究者还以此为基础,构建了多说话人TTS系统,通过数据重采样与说话人嵌入技术,实现了对不同朗读风格的精准控制。此外,该数据集被用于探索跨语言TTS中的零样本语音克隆,即在仅有乌克兰语音频的情况下,合成目标说话人的英语或其他语言语音。这些衍生工作不仅扩展了TTS技术在低资源语言上的边界,也为多语言语音交互系统的开发奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


