CVTG-2K
收藏github2025-04-01 更新2025-04-02 收录
下载链接:
https://github.com/NJU-PCALab/TextCrafter
下载链接
链接失效反馈官方服务:
资源简介:
CVTG-2K数据集包含了多样化的视觉文本提示,涵盖了位置、数量、长度和属性等方面的变化,为评估生成模型在复杂视觉文本生成任务中的性能提供了一个强大的基准。
The CVTG-2K dataset contains diverse visual-text prompts with variations across dimensions including location, quantity, length, and attributes, serving as a robust benchmark for evaluating the performance of generative models in complex visual-text generation tasks.
创建时间:
2025-03-29
原始信息汇总
TextCrafter数据集概述
数据集基本信息
- 名称: TextCrafter / CVTG-2K
- 发布机构: NJU-PCALab
- 发布日期: 2025年4月1日
- 数据集地址: https://huggingface.co/datasets/dnkdnk/CVTG-2K
- 相关论文: https://arxiv.org/abs/2503.23461
数据集简介
CVTG-2K是一个用于复杂视觉文本生成任务的基准数据集,包含2000个提示。数据集通过OpenAI的O1-mini API使用Chain-of-Thought技术生成,涵盖多样场景,包括街景、广告和书籍封面等。
数据集特点
- 文本特征:
- 平均每个视觉文本包含8.10个单词和39.47个字符
- 每个提示包含2-5个文本区域
- 风格多样性:
- 50%的数据包含样式属性(大小、颜色、字体)
- 结构特点:
- 通过解耦的提示和载体词表达文本-位置关系
数据集结构
- CVTG: 不含属性标注的数据
- CVTG-style: 包含属性标注的数据
文件命名规则:
X.json: 包含细粒度标注X_combined.json: 不含细粒度标注X代表视觉文本区域数量(2-5)
应用场景
- 视觉文本生成研究
- 文本样式化研究
- 生成模型性能评估
相关资源
- 代码仓库: https://github.com/NJU-PCALab/TextCrafter.git
- 项目主页: https://dnknju.github.io/textcrafter-vue/
搜集汇总
数据集介绍
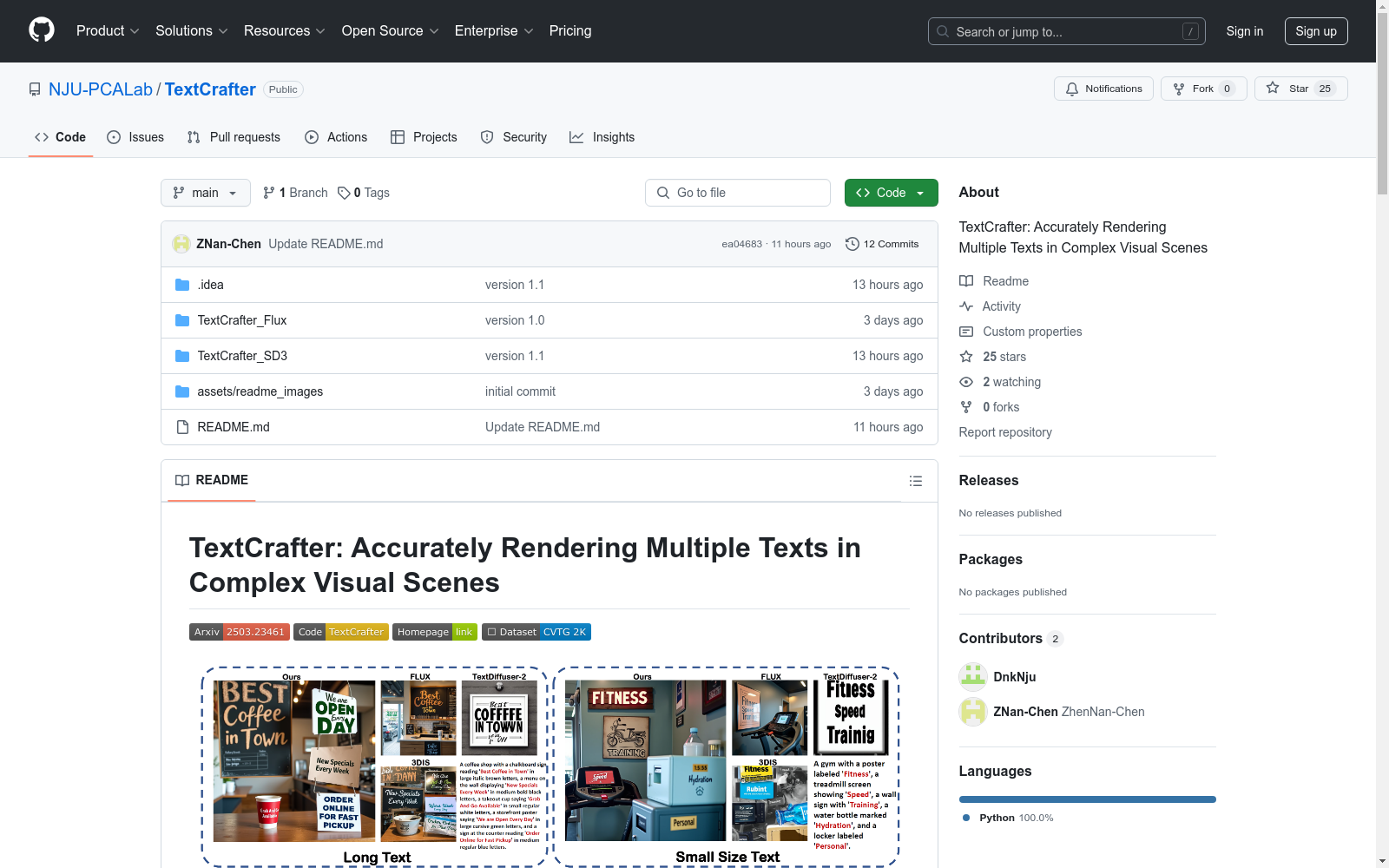
构建方式
在复杂视觉文本生成领域,CVTG-2K数据集的构建采用了严谨的自动化流程与人工校验相结合的方法。数据集通过OpenAI的O1-mini API生成初始提示文本,并运用思维链技术进行优化,确保文本内容的多样性和复杂性。构建过程中特别注重场景覆盖度,包含街景、广告和书籍封面等多种视觉场景。每个提示文本包含2-5个文本区域,平均每个视觉文本达8.10个单词和39.47个字符,其中半数样本还标注了尺寸、颜色和字体等样式属性。数据集采用分层结构组织,分为带样式标注和不带样式标注两个子集,每个子集又根据文本区域数量进一步细分。
特点
CVTG-2K数据集以其独特的复杂性在视觉文本生成领域脱颖而出。该数据集包含2000个精心设计的提示文本,特别强调多区域、长文本和小尺寸文本的生成挑战。数据样本中的文本区域数量从2到5不等,平均文本长度显著超过同类数据集。值得注意的是,半数样本包含详细的样式属性标注,为文本风格化研究提供了丰富素材。数据集采用解耦式提示设计,通过载体词明确表达文本与位置的关系,这种细粒度的标注方式大大提升了数据集的研究价值。
使用方法
使用CVTG-2K数据集时,研究者可从Hugging Face平台下载完整的压缩包。解压后可见CVTG和CVTG-style两个目录,分别对应无属性标注和带属性标注的数据。每个目录下包含按文本区域数量分类的JSON文件,文件名中的数字表示文本区域数量。研究时可根据需要选择精细标注版本或组合版本的数据文件。数据集特别适合用于评估模型在复杂场景下的多文本生成能力,通过分析不同区域数量的子集,可以全面考察模型在文本布局、样式保持和长文本生成等方面的表现。
背景与挑战
背景概述
CVTG-2K数据集由南京大学PCALab团队于2025年4月发布,旨在解决复杂视觉文本生成(CVTG)任务中的关键挑战。该数据集包含2000个经过精心设计的提示词,涵盖街景、广告和书籍封面等多种场景,每个场景包含2至5个文本区域,平均每个视觉文本包含8.10个单词和39.47个字符。数据集通过OpenAI的O1-mini API采用思维链技术生成,并特别注重文本位置、数量和属性的多样性。CVTG-2K不仅提供了细粒度的注释信息,还通过解耦的提示词和载体词表达了文本与位置的关系,为视觉文本生成和风格化研究提供了重要基准。
当前挑战
CVTG-2K数据集面临的挑战主要体现在两个方面:在领域问题方面,该数据集致力于解决复杂场景下多区域视觉文本生成的难题,包括长文本、小尺寸文本、多样符号和风格的精确渲染问题;在构建过程方面,数据集需要处理文本位置、数量和属性的高度多样性,确保每个提示词既能准确描述场景,又能清晰表达文本与载体的关系。此外,数据集的标注工作需要精细处理大量视觉文本的布局和样式信息,这对标注的一致性和准确性提出了较高要求。
常用场景
经典使用场景
在计算机视觉与图形学交叉领域,CVTG-2K数据集为复杂场景下的多文本生成任务提供了标准化评估基准。该数据集特别适用于验证文本渲染模型在街景标识、广告设计等需要同时处理多个文本区域的场景中的性能表现,其包含的2-5个文本区域配置能有效模拟真实世界复杂排版需求。通过控制变量法,研究者可系统评估模型在文本长度、位置分布及样式属性等维度的生成质量。
解决学术问题
CVTG-2K数据集主要解决了视觉文本生成领域三个关键学术问题:多文本区域协同生成的布局优化难题、长文本在小尺寸区域的清晰渲染问题,以及样式属性与语义内容的解耦控制。数据集通过提供细粒度的载体关联标注和样式属性标注,为建立文本-载体-位置的三元关系建模奠定了数据基础,显著推进了复杂场景文本生成的可控性研究。
衍生相关工作
CVTG-2K的发布催生了多个视觉文本生成领域的创新研究。基于该数据集基准测试的TextCrafter框架提出了训练自由的文本渲染方案,其区域隔离与令牌聚焦机制被后续工作广泛借鉴。FLUX-Text和StyleDiffuser等模型通过引入该数据集的样式标注分支,实现了文本视觉属性的细粒度控制,推动了生成式设计工具的发展。
以上内容由遇见数据集搜集并总结生成


