LCC_deu_news_1M_bt
收藏Hugging Face2025-08-06 更新2025-08-07 收录
下载链接:
https://huggingface.co/datasets/MarcGrumpyOlejak/LCC_deu_news_1M_bt
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集是一个实验项目,它包括从2012年到2024年的德语新闻文本,这些文本是通过从德语翻译成英语,然后再回译成德语的方式生成的。数据集包括打分的子集和挖掘出来的难例负样本子集。打分的子集中包含了原始文本、翻译后的英语文本、回译后的德语文本以及它们之间的余弦相似度得分。挖掘出来的难例负样本子集包含了回译后的德语文本、原始德语文本以及五个与原始文本具有相似度得分的难例负样本。数据集的用途包括特征提取和句子相似度任务。
创建时间:
2025-08-05
原始信息汇总
数据集概述:Leipzig Corpora Collection - Backtranslated News German 1M*n
基本信息
- 名称:Leipzig Corpora Collection - Backtranslated News German 1M*n
- 许可证:CC-BY-4.0
- 语言:德语(de)
- 多语言性:单语
- 任务类别:特征提取、句子相似性
- 规模:10M < n < 100M
数据集配置
-
0_deu_news_1M_bt_scored
- 数据文件:
0_deu_news_1M_bt_scored/deu_news_*.parquet - 列:
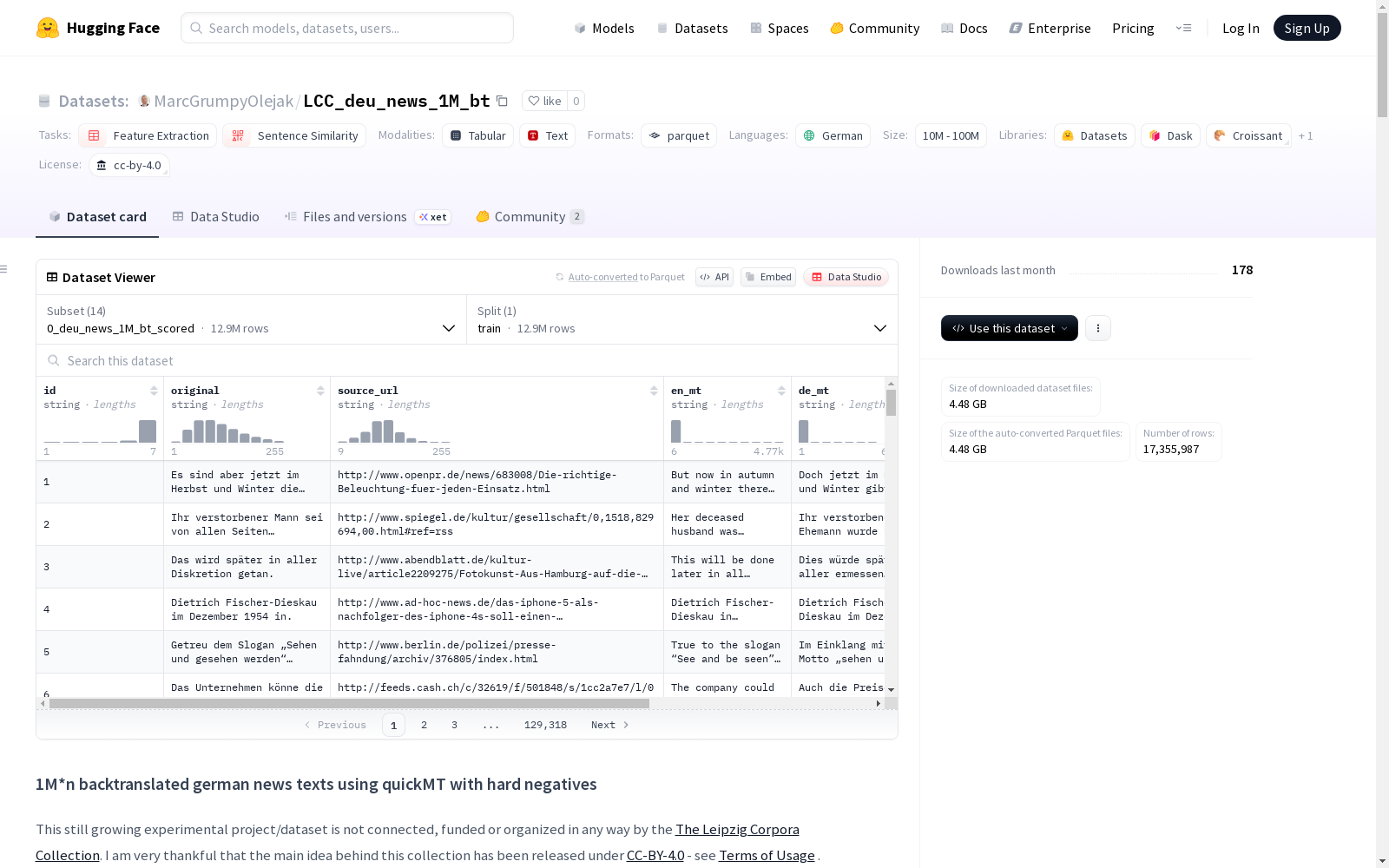
id:原始IDoriginal:原始句子source_url:原始URLen_mt:德语到英语的翻译de_mt:回译的德语版本cos_sim_sts_en:英语翻译与原文的余弦相似度cos_sim_sts_de:回译德语与原文的余弦相似度
- 数据文件:
-
年份-triplet-5(2012-2024)
- 数据文件:
年份-triplet-5/train-5hn-*.parquet - 列:
de_mt:回译的德语文本original:原始德语文本negative_1至negative_5:5个硬负样本
- 数据文件:
数据集内容
- 原始数据来源:Leipzig Corpora Collection的德语新闻部分(2012-2024)
- 处理方式:
- 使用quickMT进行德语到英语的翻译及回译
- 使用STS模型(sts-mrl-en-de-base-v1)评分
- 筛选相似度高于平均值10%的文本对
- 为每行挖掘5个硬负样本
统计信息
- 总文本对数量:12,931,800
- 各年份统计:
- 2012-2024年,每年约100万句子(部分年份略有减少)
- 平均余弦相似度:约0.75-0.76
- 筛选阈值:约0.83-0.83
使用示例
-
加载硬负样本: python dataset = load_dataset("MarcGrumpyOlejak/LCC_deu_news_1M_bt", "2024-triplet-5", split="train")
-
加载评分集: python dataset = load_dataset("MarcGrumpyOlejak/LCC_deu_news_1M_bt", "0_deu_news_1M_bt_scored", split="train")
引用
bibtex @inproceedings{goldhahn-etal-2012-building, title = "Building Large Monolingual Dictionaries at the {L}eipzig Corpora Collection: From 100 to 200 Languages", author = "Goldhahn, Dirk and Eckart, Thomas and Quasthoff, Uwe", booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}12)", year = "2012", publisher = "European Language Resources Association (ELRA)", pages = "759--765" }
相关资源
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量双语语料是机器翻译与语义相似度研究的基础。本数据集基于莱比锡语料库的德语新闻文本,采用回译技术构建:首先将原始德语句子通过quickMT神经网络翻译模型转换为英语,再回译为德语,形成双语对齐语料。整个过程使用ctranslate框架优化参数以增强语义多样性,最后通过预训练的德英语义相似度模型sts-mrl-en-de-base-v1对回译结果进行余弦相似度评分,筛选相似度高于平均值10%的优质样本。
使用方法
针对语义表示学习任务,研究者可直接加载年度子集(如2024-triplet-5)获得包含正负例的三元组结构,适配Sentence Transformers的MultipleNegativesRankingLoss训练框架。对于机器翻译研究,0_deu_news_1M_bt_scored配置提供完整的回译过程数据,支持通过余弦相似度阈值过滤不同质量等级的句对。数据集兼容HuggingFace标准加载接口,用户可通过指定配置名称与列筛选操作,快速构建德德或英德平行语料,为跨语言语义理解任务提供支撑。
背景与挑战
背景概述
莱比锡语料库集合(Leipzig Corpora Collection)作为多语言文本资源的重要基础设施,由莱比锡大学与萨克森科学院等机构联合构建,自1995年起持续扩展。其德语新闻子集LCC_deu_news_1M_bt专注于机器翻译与语义相似性研究,通过回译技术生成大规模德英双语对照文本,为自然语言处理领域提供了高质量的跨语言表示学习资源。该数据集采用CC-BY-4.0许可协议,显著推动了低资源语言处理技术的发展,并为语义相似性计算、跨语言检索等任务提供了重要基准。
当前挑战
该数据集致力于解决跨语言语义表示中的对齐难题,特别是在低资源语言环境下构建高质量平行语料的挑战。构建过程中需克服多重技术障碍:一是回译过程中的语义漂移问题,需通过参数优化控制生成文本的忠实度;二是大规模语料的质量评估,需设计有效的自动评分机制过滤低质量样本;三是硬负例挖掘的复杂性,要求精确计算语义相似度阈值以确保负例的区分度。此外,原始语料的时序跨度与领域多样性也为数据一致性维护带来挑战。
常用场景
经典使用场景
在自然语言处理领域,LCC_deu_news_1M_bt数据集通过回译技术生成了高质量的德语句对,为语义相似度计算和句子嵌入训练提供了重要资源。该数据集特别适用于训练和评估跨语言表示学习模型,其包含的硬负例样本能够有效提升对比学习框架中模型的判别能力。研究者可利用其时间跨度特性分析语言演变的动态特征,为历时语言学研究提供数据支撑。
解决学术问题
该数据集有效解决了低资源语言表示学习中高质量训练数据稀缺的学术难题。通过回译技术生成的语义等价句对,为德语句子嵌入模型提供了可靠的监督信号。其创新的硬负例挖掘机制显著提升了模型对语义细微差异的敏感度,推动了跨语言语义相似度计算方法的进步。该资源对促进德语自然语言处理技术的均衡发展具有重要学术价值。
实际应用
在实际应用层面,该数据集为构建德语智能问答系统和机器翻译质量评估提供了关键训练数据。其高质量的句对可用于优化搜索引擎的相关性排序算法,提升德语信息检索系统的精度。新闻机构可利用该资源开发自动摘要生成工具,而教育科技公司则能基于其构建更精准的语言学习应用。这些应用显著提升了德语自然语言处理技术在真实场景中的性能表现。
数据集最近研究
最新研究方向
在德语自然语言处理领域,LCC_deu_news_1M_bt数据集通过回译技术构建的大规模新闻语料库,正推动语义相似性计算与对比学习的前沿研究。该数据集采用跨语言回译策略生成德语句子的语义变体,并结合静态STS模型进行相似度评分,为多语言表示学习提供了高质量的训练样本。其硬负样本挖掘机制特别适用于改进Sentence Transformers中的MultipleNegativesRankingLoss训练效果,显著提升了德语句子嵌入模型在语义匹配任务上的表现。随着神经机器翻译技术的持续进步,此类基于回译增强的语言资源正在成为跨语言迁移学习和低资源语言建模的重要基础,对推动德语NLP技术在新闻分析、知识提取等应用场景的发展具有关键意义。
以上内容由遇见数据集搜集并总结生成


