transcritor-ia-eclesiastico-1890-htr
收藏Hugging Face2025-02-12 更新2025-02-13 收录
下载链接:
https://huggingface.co/datasets/rodrig-crzz/transcritor-ia-eclesiastico-1890-htr
下载链接
链接失效反馈官方服务:
资源简介:
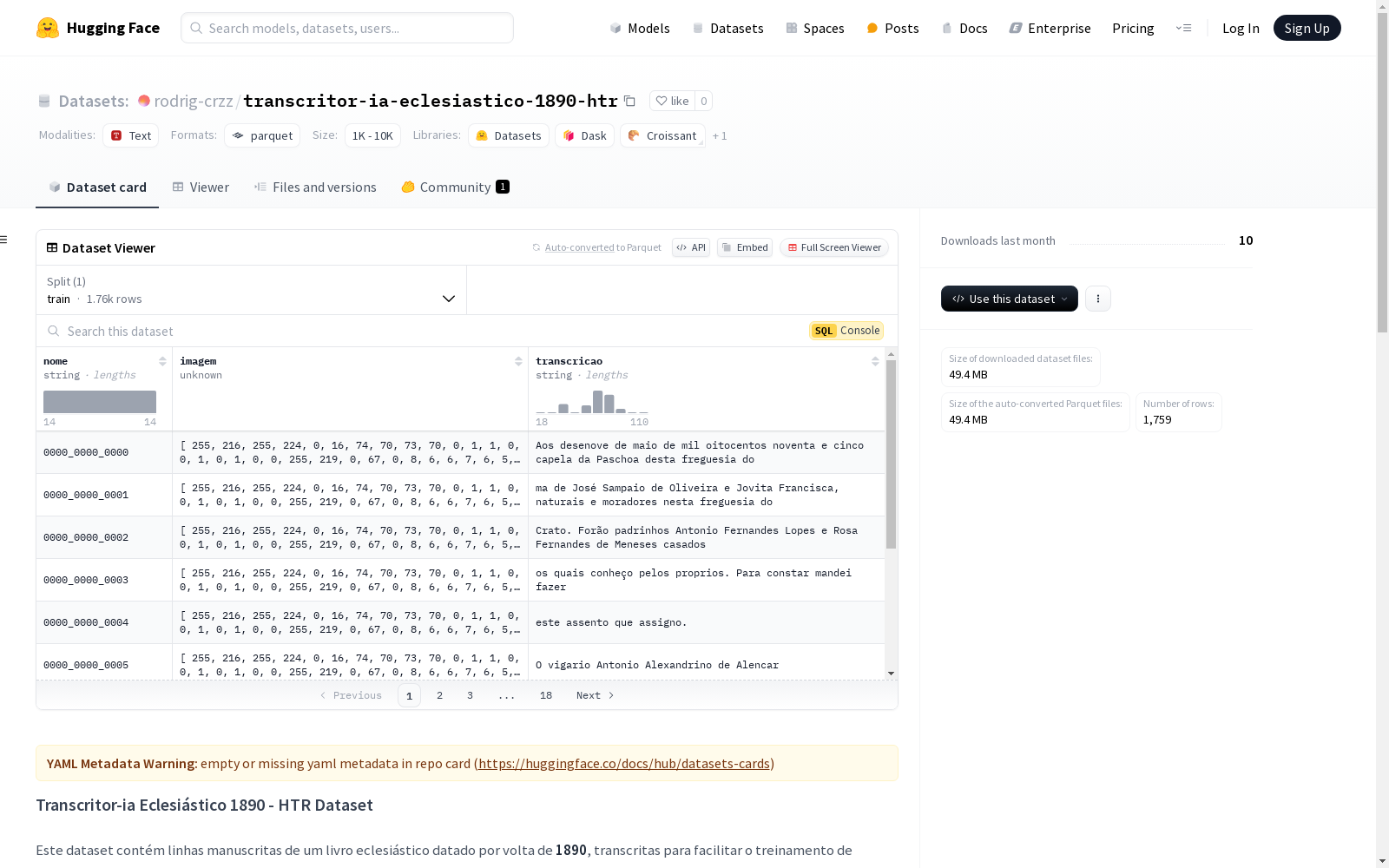
Transcritor-ia Eclesiástico 1890手写文本识别数据集包含大约1890年的手写教会书籍的文本行,用于训练手写文本识别模型。数据集分为训练集和验证集,以Parquet格式存储,包含图像标识符、图像数据和对应的文本转录。共有1759张图像,图像高度为128像素,转录语言为巴西葡萄牙语,来源于大约1890年的手写教会书籍。
创建时间:
2025-01-31
搜集汇总
数据集介绍
构建方式
transcritor-ia-eclesiastico-1890-htr数据集,旨在为手写文本识别技术(HTR)提供训练资源,搜集了约1890年的葡萄牙语(巴西)手写教会书籍文本。数据集构建过程中,首先将手写文本转录为电子文本,随后将文本与对应的图像字样配对,并按照80%训练集与20%验证集的比例划分为两个子集,采用Parquet格式存储,以确保数据的高效读取与处理。
特点
该数据集具备以下显著特点:包含1759张图像,每张图像高度均为128像素,均为历史悠久的教会手写文献,文本内容为葡萄牙语(巴西)。数据集不仅提供了丰富的手写样本,而且通过严谨的构建方式,保证了数据的质量与训练的有效性。
使用方法
用户可利用Python的pandas库配合pyarrow工具读取数据集,通过简单的代码即可加载训练与验证数据。此外,数据集中的图像以字节数据形式存储,用户可使用PIL库将字节数据转换为可视化的图像进行观察,便利了研究人员对数据集的深入分析与模型训练。
背景与挑战
背景概述
在历史文献研究领域,手写文本识别技术(HTR)的应用日益受到重视。transcritor-ia-eclesiastico-1890-htr数据集应运而生,该数据集由Transcritor-ia项目团队创建于近代,旨在为HTR模型的训练提供助力,特别是针对19世纪末期的巴西葡萄牙语手写文本。该数据集的构建,不仅丰富了历史文献数字化处理的资源库,也为相关领域的研究人员提供了宝贵的实验材料,对推动手写文本识别技术的发展具有重要意义。
当前挑战
尽管transcritor-ia-eclesiastico-1890-htr数据集为手写文本识别领域提供了有力的支持,但研究者和开发者仍面临着诸多挑战。首先,该数据集的构建过程中,如何准确地将19世纪的手写文本转换为数字格式,保证转录的准确性是一大难题。其次,由于手写文本的多样性和复杂性,模型在处理不同书写风格和笔迹时,如何保持高识别率也是当前面临的关键挑战。此外,数据集规模相对有限,可能导致模型在泛化能力上的不足,这在实际应用中需要特别关注。
常用场景
经典使用场景
在深度学习与自然语言处理领域,transcritor-ia-eclesiastico-1890-htr数据集的典型应用场景在于训练手写文本识别(HTR)模型。该数据集提供了约1890年间的宗教手稿文本,其丰富的手写文本资源对于提升模型对手写文字的识别准确性至关重要。
实际应用
在实际应用中,transcritor-ia-eclesiastico-1890-htr数据集可用于开发自动化的手写文本转录系统,服务于图书馆、档案馆以及历史研究机构的文献数字化工作,加快信息提取与检索效率。
衍生相关工作
基于此数据集,研究者们开展了多项相关工作,如构建更为精准的HTR系统、对手写文本进行风格分类、以及开展跨领域的历史文献语义分析等,推动了手写文本识别技术在多领域的应用与发展。
以上内容由遇见数据集搜集并总结生成


