Reveal-Bangla
收藏arXiv2025-08-12 更新2025-08-14 收录
下载链接:
https://huggingface.co/datasets/khondoker/reveal-bangla
下载链接
链接失效反馈官方服务:
资源简介:
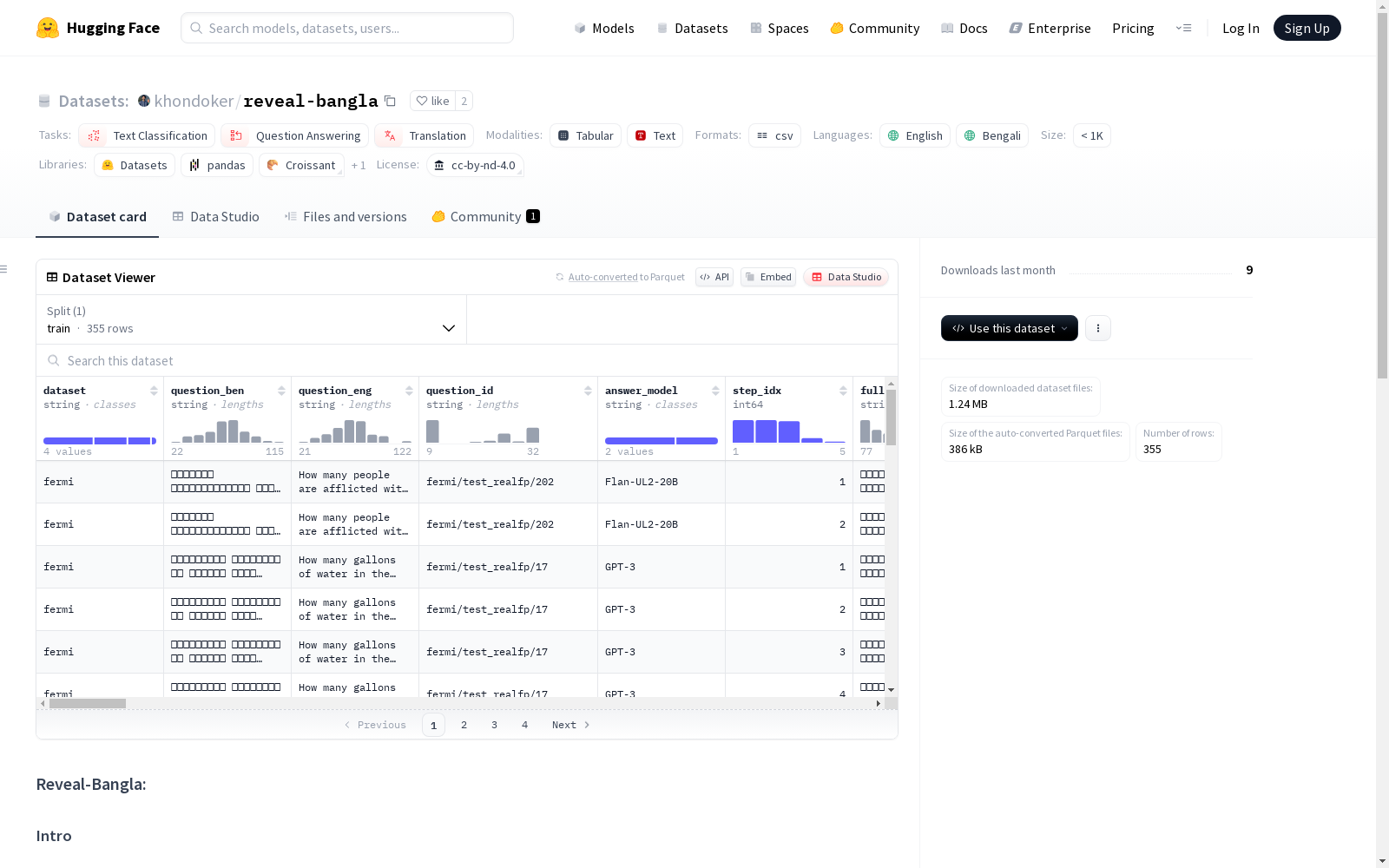
Reveal-Bangla是一个手动翻译的孟加拉语多步推理数据集,源自英语Reveal数据集。该数据集包含带有黄金答案的注释多步推理链,用于评估跨语言的小型语言模型在利用推理步骤生成正确答案方面的能力。数据集包含104个独特的问题,188个证据段落和355个推理步骤。该数据集旨在解决在孟加拉语等低资源语言中评估和改进语言模型推理能力的问题。
Reveal-Bangla is a manually translated Bengali multi-step reasoning dataset derived from the English Reveal dataset. It contains annotated multi-step reasoning chains paired with gold standard answers, which are used to evaluate the ability of small cross-lingual language models to generate correct answers by leveraging reasoning steps. The dataset comprises 104 unique questions, 188 evidence passages, and 355 reasoning steps. This dataset aims to address the gap in evaluating and improving the reasoning capabilities of language models in low-resource languages such as Bengali.
提供机构:
格罗宁根大学语言与认知中心(CLCG)
创建时间:
2025-08-12
原始信息汇总
Reveal-Bangla 数据集概述
基本信息
- 许可证: cc-by-nd-4.0
- 语言: 英语 (en), 孟加拉语 (bn)
- 数据集名称: Reveal-Bangla
- 任务类别: 文本分类, 问答系统, 翻译
- 规模类别: 小于1K样本 (n<1K)
数据集简介
-
该数据集是 reveal 数据集的子集的孟加拉语翻译版本。
-
使用以下条件筛选子集: sql SELECT * FROM eval Where ( answer_model = Flan-UL2-20B or answer_model = GPT-3 AND answer_is_fully_attributable_and_correct = TRUE );
-
仅翻译了以下列:
- question
- full_answer
- step
- evidence
使用方式
-
安装依赖: python ! pip install datasets
-
加载数据集: python from datasets import load_dataset reveal_bn = load_dataset("khondoker/reveal-bangla")
字段描述
- evidence_ben: 证据的孟加拉语翻译
- evidence_eng: 证据的原始英文文本
- question_ben: 问题的孟加拉语翻译
- question_eng: 问题的原始英文文本
- full_answer_ben: 完整CoT答案的孟加拉语翻译
- full_answer_eng: 完整CoT答案的原始英文文本
- step_ben: 匹配 "step_idx" 的步骤的孟加拉语翻译
- step_eng: 匹配 "step_idx" 的步骤的原始英文文本
注意事项
- 仅描述了修改过的列,详细描述请参考 google/reveal 数据集。
搜集汇总
数据集介绍
构建方式
Reveal-Bangla数据集的构建基于对英文Reveal数据集的手动翻译与本地化处理。研究团队从原始数据集中筛选了104个具有完整逻辑链和上下文关联性的问题,涵盖二元与非二元问题类型。翻译工作由孟加拉语母语研究者执行,在保留专业术语(如体育团队名称、计量单位)原貌的同时,确保文化适配性。每个样本包含问题、证据段落、多步推理链和最终答案的完整结构,形成英孟双语平行语料。
使用方法
研究者可通过HuggingFace平台获取该CC-BY-ND许可的数据集,支持两种典型应用场景:在gen_ans模式下直接测试模型答案生成能力,或在w_cot_gen_ans模式下评估模型对预设推理链的利用效率。评估时建议采用跨语言NLI模型进行答案验证,并注意处理孟加拉语特有的中立判定情况。数据集特别适用于探究小参数语言模型在低资源语言中的推理机制差异,配套提供的ContextCite分析方法可量化推理步骤对最终预测的贡献度。
背景与挑战
背景概述
Reveal-Bangla数据集由格罗宁根大学语言与认知中心(CLCG)的Khondoker Ittehadul Islam和Gabriele Sarti于2025年提出,旨在填补低资源语言——孟加拉语(Bangla)在多步推理任务评估中的空白。该数据集基于英文Reveal数据集手工翻译构建,包含二元与非二元问题类型,并标注了人工验证的推理链。作为全球第六大语言(2.68亿使用者),孟加拉语在快速数字化的南亚地区具有重要社会价值,但此前缺乏带推理步骤标注的评估资源,制约了相关大语言模型能力的发展。该研究首次系统评估了英语中心与孟加拉语中心的小型语言模型在跨语言推理中的表现,揭示了模型利用不同语言推理步骤的差异性。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题层面,现有大语言模型在多步推理评估中严重偏向英语等高资源语言,导致低资源语言场景下的推理能力评估缺乏可靠基准,而孟加拉语复杂的形态结构和有限训练资源进一步加剧了模型对推理步骤的利用困难;构建过程层面,专业术语(如体育、医学领域)的精准翻译需要平衡文化适应性与术语一致性,部分英文专有名词需保留原形式,且人工翻译中单一标注者可能引入偏差。此外,自动翻译工具在体育类内容上表现欠佳,而数据集70%的二元问题占比可能无法全面反映复杂推理场景的挑战。
常用场景
经典使用场景
Reveal-Bangla数据集在跨语言多步推理评估中展现了其经典应用场景。该数据集通过手动翻译英文Reveal数据集中的多步推理问题,构建了包含二元和非二元问题的孟加拉语版本,为研究者提供了一个评估语言模型在低资源语言环境下推理能力的标准化工具。在自然语言处理领域,特别是在多语言链式思维(CoT)提示的研究中,该数据集被广泛用于测试模型如何利用中间推理步骤生成最终答案,尤其是在处理复杂非二元问题时表现出的跨语言迁移能力。
解决学术问题
该数据集有效解决了当前大语言模型评估中高资源语言主导的学术研究问题。通过构建孟加拉语多步推理数据集,填补了低资源语言在复杂推理任务评估上的空白,为研究者提供了分析语言模型跨语言推理能力差异的实证基础。其标注的推理步骤和黄金答案允许研究者深入探究模型内部处理过程,揭示了英语与孟加拉语在推理步骤利用上的显著差异,特别是在小参数语言模型中观察到的有限性能提升现象,这对理解语言资源差异对模型推理能力的影响具有重要理论意义。
实际应用
在实际应用层面,Reveal-Bangla为孟加拉语地区的智能化服务开发提供了关键支持。作为全球第六大语言,孟加拉语在快速数字化转型的地区具有广泛应用需求。该数据集可直接用于优化本地化问答系统、教育辅助工具等需要复杂推理能力的应用场景。其标注的推理链条还能辅助开发更透明的AI系统,帮助开发者诊断模型在医疗、历史等专业领域的推理缺陷,对于提升低资源语言地区的AI技术包容性具有现实价值。
数据集最近研究
最新研究方向
随着多语言自然语言处理技术的快速发展,Reveal-Bangla数据集的推出填补了孟加拉语多步推理评估资源的空白。该数据集作为首个包含人工验证推理链的孟加拉语评估基准,为研究语言模型在低资源语言环境下的推理能力提供了重要工具。当前研究聚焦于跨语言推理能力的差异性分析,特别是英语与孟加拉语在链式思维(CoT)提示效果上的对比。最新实验表明,小型语言模型在非二元问题中能有效利用推理步骤,但在孟加拉语环境下性能提升有限,这引发了关于低资源语言特定优化方法的深入探讨。同时,研究者正通过后归因技术分析推理步骤对预测结果的贡献模式,揭示了不同语言间存在显著差异的注意力分配机制。这些发现对开发面向新兴经济地区的可信AI技术具有重要指导意义。
相关研究论文
- 1Reveal-Bangla: A Dataset for Cross-Lingual Multi-Step Reasoning Evaluation格罗宁根大学语言与认知中心(CLCG) · 2025年
以上内容由遇见数据集搜集并总结生成


