bus_cot_preprocessed
收藏Hugging Face2026-05-18 更新2026-05-19 收录
下载链接:
https://huggingface.co/datasets/WOOJYE/bus_cot_preprocessed
下载链接
链接失效反馈官方服务:
资源简介:
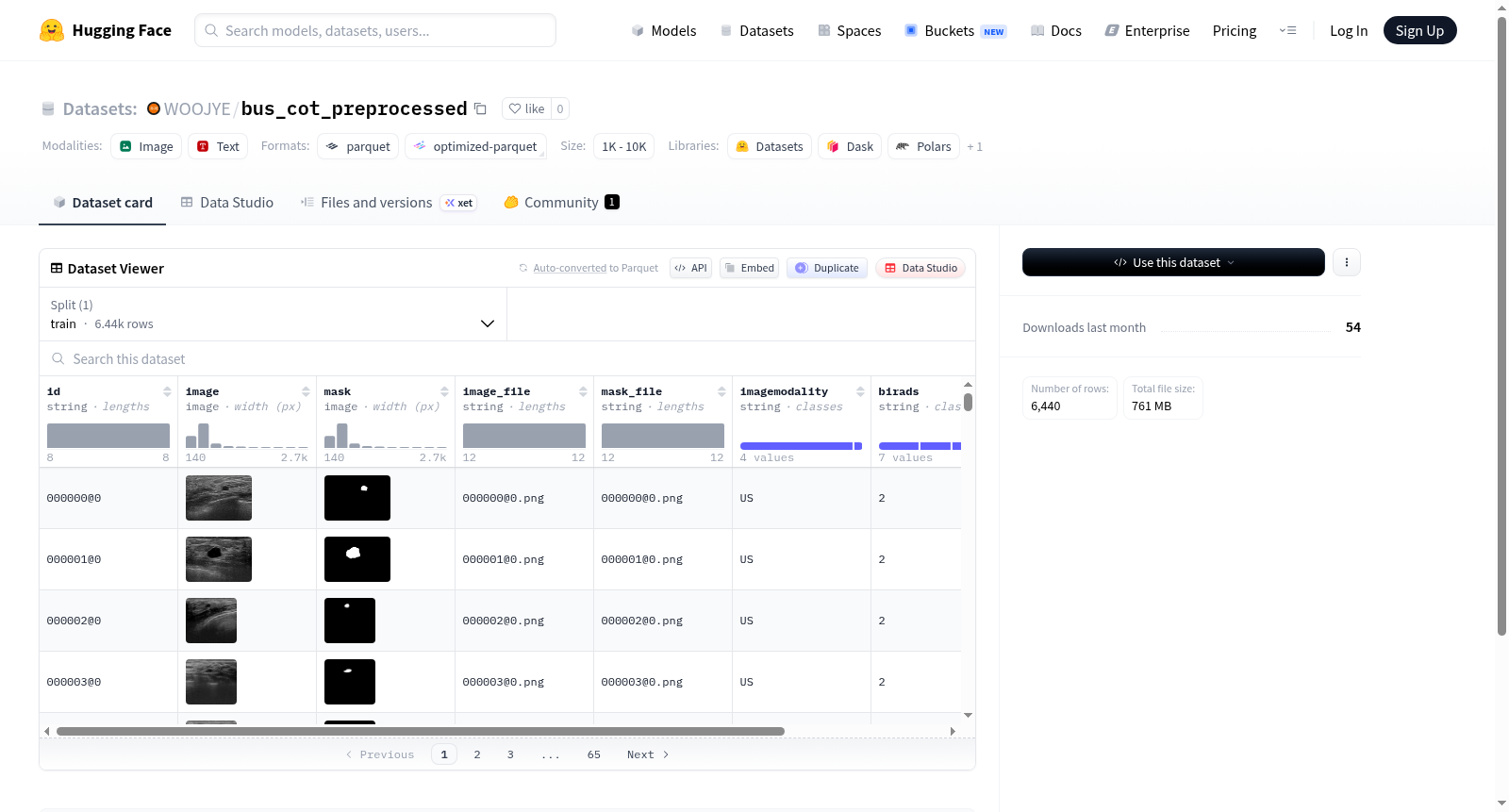
该数据集是一个医学影像数据集,专门用于乳腺影像分析任务。数据集包含6440个训练样本,总大小约648MB。每个样本包含以下核心字段:原始医学图像(image字段)、对应的分割掩码图像(mask字段)、图像文件路径(image_file和mask_file)、图像模态信息(imagemodality)、BI-RADS分类标签(birads)以及推理响应文本(reasoning_response)。数据集适用于医学影像分析、计算机辅助诊断、图像分割、分类任务以及结合视觉与文本的多模态学习研究。BI-RADS标签表明该数据集特别关注乳腺影像报告和数据系统分类,可用于开发自动分类或辅助诊断系统。
This dataset is a medical imaging dataset specifically designed for breast imaging analysis tasks. It contains 6440 training samples with a total size of approximately 648MB. Each sample includes the following core fields: original medical image (image field), corresponding segmentation mask image (mask field), image file paths (image_file and mask_file), image modality information (imagemodality), BI-RADS classification label (birads), and reasoning response text (reasoning_response). The dataset is suitable for medical image analysis, computer-aided diagnosis, image segmentation, classification tasks, and multimodal learning research combining visual and textual information. The BI-RADS label indicates that this dataset focuses particularly on the Breast Imaging Reporting and Data System classification, making it useful for developing automated classification or auxiliary diagnostic systems.
创建时间:
2026-05-08
原始信息汇总
根据您提供的数据集详情页面信息,以下是该数据集的总结:
数据集名称
WOOJYE/bus_cot_preprocessed
数据集地址
https://huggingface.co/datasets/WOOJYE/bus_cot_preprocessed
数据集描述
该数据集是一个经过预处理的乳腺超声(BUS)图像数据集,包含图像、分割掩膜以及相关的推理链(Chain-of-Thought)标注信息,主要用于医学图像分析中的分割与推理任务。
数据集特征
数据集包含以下字段:
| 特征名称 | 数据类型 | 说明 |
|---|---|---|
| id | string | 样本唯一标识符 |
| image | image | 乳腺超声图像 |
| mask | image | 对应的分割掩膜图像 |
| image_file | string | 图像文件名 |
| mask_file | string | 掩膜文件名 |
| imagemodality | string | 影像模态类型 |
| birads | string | BI-RADS分类(乳腺影像报告和数据系统) |
| reasoning_response | string | 推理链响应(Chain-of-Thought推理过程) |
数据集划分
数据集仅包含一个划分:
- 训练集(train):共6,440个样本,数据大小为648,680,162字节(约618.5 MB)
数据集大小
- 下载大小:750,250,981字节(约715.5 MB)
- 数据集总大小:648,680,162字节(约618.5 MB)
配置
- 配置名称:default
- 数据文件路径:
data/train-*
搜集汇总
数据集介绍
构建方式
该数据集基于乳腺超声影像构建,整合了原始图像、分割掩膜及临床标签(如BI-RADS分级)。数据预处理阶段通过自动提取每个病例的影像模态与病理推理响应,形成结构化样本。训练集包含6440个实例,每项记录均关联唯一的图像标识符(image_file)与掩膜路径(mask_file),确保原始数据与标注信息的一一映射,为模型提供可追溯的多模态输入。
特点
数据集的独特性在于融合了影像特征与临床推理链(reasoning_response),将经验性诊断逻辑显式编码为文本描述。每张图像配备对应病灶掩膜,支持定位与分类任务的双重训练。BI-RADS分级字段标准化了恶性风险等级,而模态标签(imagemodality)则区分不同超声采集参数,为鲁棒性模型开发提供细粒度控制。
使用方法
可通过HuggingFace Datasets库加载,使用默认配置直接访问6440条训练样本。典型应用流程包括:基于image字段读取超声图像,结合mask字段训练分割网络;利用birads与reasoning_response组合完成诊断推理微调。数据以分片形式存储(data/train-*),支持分布式加载与按需批量化处理,兼容PyTorch/TensorFlow等主流框架。
背景与挑战
背景概述
乳腺超声影像作为乳腺癌筛查与诊断的重要工具,其解读高度依赖于放射科医生的经验与认知水平。然而,临床实践中不同医生对乳腺影像报告和数据系统(BI-RADS)分级的主观判断差异,以及诊断推理过程的不可见性,制约了人工智能辅助诊断系统的可信度与可解释性。针对这一困境,研究者构建了名为“bus_cot_preprocessed”的数据集,该数据集在传统超声影像与掩膜标注的基础上,创新性地引入了“思维链”(Chain-of-Thought)形式的推理响应字段,旨在推动具备推理能力的医学视觉语言模型的发展。数据集创建于近年来医学多模态大模型快速发展的时期,核心研究问题聚焦于如何通过结构化的推理标注提升模型在乳腺超声诊断中的可解释性与准确性。该数据集包含6440个训练样本,涵盖影像、掩膜、BI-RADS分级及对应推理过程,为乳腺超声领域的可解释人工智能研究提供了宝贵的基础资源。
当前挑战
该数据集面临的核心挑战在于超声影像本身的固有特性,包括图像信噪比低、病灶边界模糊、伪影干扰严重等,使得从影像中提取可靠的视觉特征并进行准确分级极具难度。此外,乳腺肿瘤的形态异质性与良恶性交界情况的复杂性,要求模型不仅要识别影像模式,还需理解临床推理中的逻辑链条,这对现有视觉语言模型的推理能力提出了更高要求。在数据集构建过程中,挑战同样显著:收集大规模、高质量、来自多家机构的超声影像受限于设备差异、采集协议不统一以及患者隐私保护法规,导致数据标准化与脱敏处理极为繁琐;而为每张影像标注BI-RADS分级及其对应的专家级推理过程,需要资深放射科医生投入大量时间与认知资源,不仅成本高昂,且不同专家间的标注一致性难以保障。这些挑战共同制约了数据集规模与模型泛化能力的进一步提升。
常用场景
经典使用场景
在乳腺超声影像分析领域,bus_cot_preprocessed数据集以其精细的标注结构,为医学图像分割与诊断推理提供了经典研究平台。该数据集不仅包含高分辨率的乳腺超声图像及其对应的病灶掩膜,更创新性地引入了多模态特征描述(如成像模态、BI-RADS分级)与链式思维推理文本,使其成为联结视觉特征与临床知识、推动可解释性深度学习方法发展的标杆性资源。研究者在乳腺病灶边界勾勒、良恶性判别等细粒度医学影像解读任务中,常以此数据集作为基准,验证模型在结合语义推理与像素级预测方面的能力。
解决学术问题
该数据集直接回应了乳腺超声诊断中两大核心学术难题:一是在数据稀缺背景下如何提升模型对病灶区域的精准分割能力,二是如何弥合临床影像特征与诊断逻辑之间的语义鸿沟。通过提供标准化的BI-RADS分级与详细的推理过程文本,bus_cot_preprocessed使得研究者能够训练出不仅能够识别病灶,还能解释其医学判断依据的智能系统。这极大推动了医学影像分析从“黑箱”预测向可解释、可信赖的临床辅助决策方向的转型,对于提升早期乳腺癌筛查的准确率与透明度具有深远意义。
衍生相关工作
基于bus_cot_preprocessed数据集,研究者已衍生出一系列前沿工作。例如,部分团队将其中的图像与链式思维文本对用于训练多模态大语言模型,探索视觉语言模型在医学影像诊断中的零样本或少样本泛化能力;另有学者利用其提供的BI-RADS标签与推理数据,开发了具备逐步推理能力的分割-分类联合框架,显著提升对复杂病灶的鉴别准确率。这些衍生工作不仅验证了该数据集在推动医学人工智能可解释性研究中的核心价值,也促进了一系列跨模态与知识引导式学习范式的诞生,为后续乳腺影像智能分析奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


