pexels-photos-janpf
收藏Hugging Face2024-06-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/opendiffusionai/pexels-photos-janpf
下载链接
链接失效反馈官方服务:
资源简介:
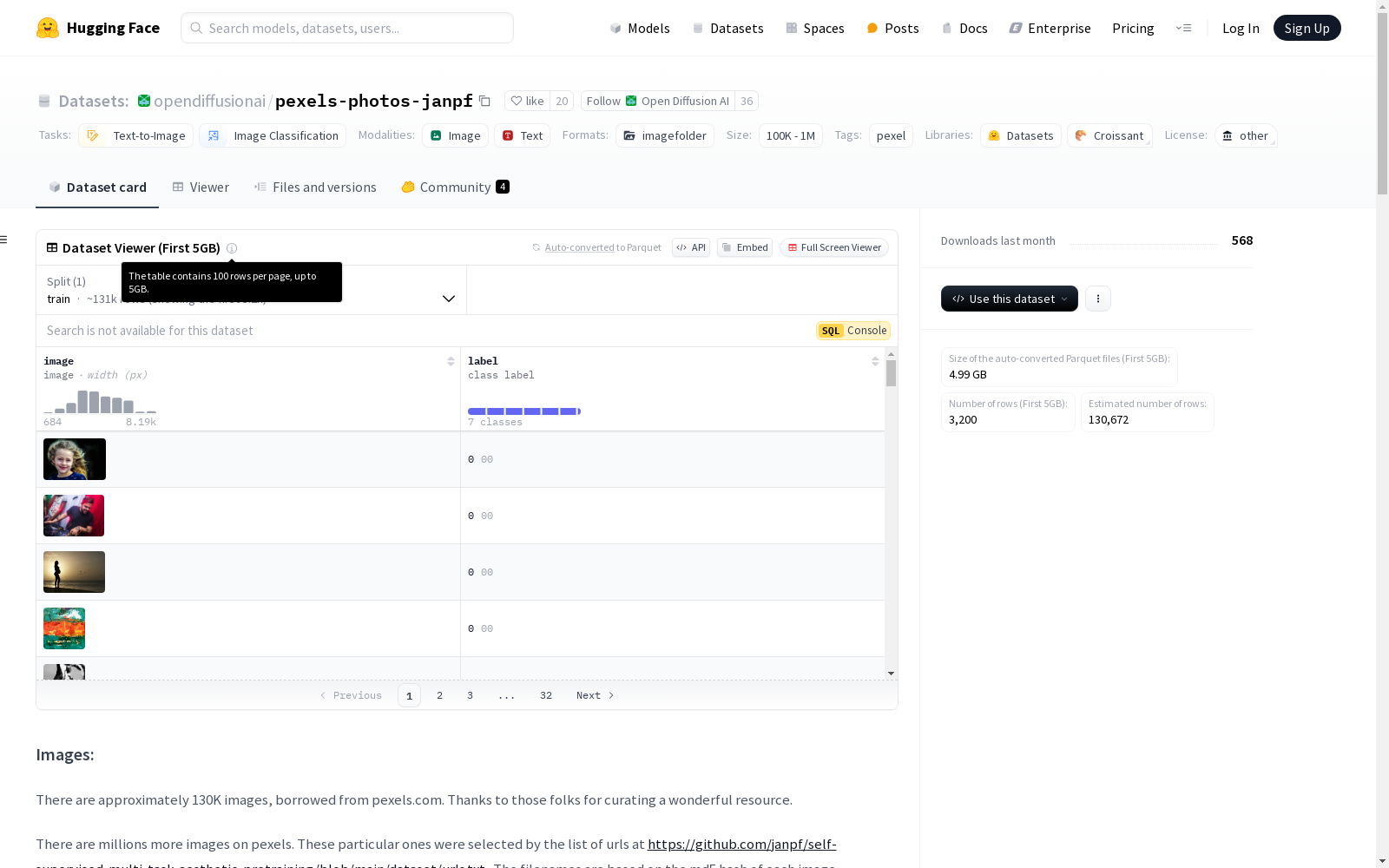
该数据集包含约130,000张从pexels.com借用的图片,这些图片通过特定的URL列表进行选择。数据集提供了两种预生成的图像描述:WD14和InternLM。WD14使用的是WD14vit2 LLM,而InternLM使用的是InternLM 7b VLM。此外,数据集还提供了一个名为'1girl'的子集,该子集通过过滤减少了约1300个错误标记的图像,最终包含20,000张图像。图像文件被组织在64个zip档案中,每个档案覆盖4个目录。
创建时间:
2024-06-25
原始信息汇总
数据集概述
数据集信息
- 许可证: other
- 任务类别:
- text-to-image
- image-classification
- 标签: pexel
- 数据量: 100K<n<1M
图像信息
- 数量: 约130,000张
- 来源: pexels.com
- 文件名: 基于图像的md5哈希值
- 格式: 混合.jpg和.png
- 尺寸: 不统一,范围从3000到6000像素
图像组织
- 存储方式: 分为64个zip文件,每个文件包含特定子目录(如00,01,02,03)的图像
图像描述
- 预计算描述: 提供三种不同来源的描述文件
txt-ilm7qant.ziptxt-wd14.ziptxt-llava38bi4.zip
- 描述来源:
- WD14: 快速但不准确
- ilm7quant: 使用InternLM 7b (量化) VLM,简洁客观
- LLava 38b: 最全面的描述
元数据
- 格式: parquet
- 查询示例: 提供
makequery.py脚本
子集
- 特定子集:
list-woman-18000.txt: 约18,000张图像,目标为"woman"list-pww-1000.txt: 约1,000张图像,从上述列表中筛选
- 子集筛选: 提供Linux命令示例进行筛选
搜集汇总
数据集介绍
构建方式
pexels-photos-janpf数据集构建于Pexels.com平台,精选了约130K张图像,这些图像通过URL列表从Pexels中筛选而来。每张图像的文件名基于其MD5哈希值生成,确保了数据的唯一性和可追溯性。数据集以64个压缩包形式组织,每个压缩包包含若干子目录,便于管理和下载。此外,数据集还提供了三种预计算的图像描述(WD14、InternLM和LLava-38b),用户可根据需求选择适合的描述方式。
使用方法
使用pexels-photos-janpf数据集时,用户可以通过Hugging Face CLI工具或直接从Pexels.com下载图像。下载后,用户可选择使用预计算的描述文件进行图像筛选,或通过编辑自动下载脚本来定制下载格式和分辨率。数据集还提供了详细的元数据文件,用户可以通过编写代码进行高级查询。此外,数据集支持通过文本文件进行图像筛选,如查找包含特定标签的图像或排除不相关的内容。对于需要特定子集的用户,数据集提供了多个预定义的子集列表,用户可根据需求选择使用。
背景与挑战
背景概述
pexels-photos-janpf数据集是一个包含约130K图像的大规模数据集,源自pexels.com,由janpf团队精心挑选并整理。该数据集主要用于文本到图像生成和图像分类任务,涵盖了多种图像格式和分辨率。其创建时间可追溯至2020年代初期,旨在为自监督学习和多任务美学预训练提供高质量的图像资源。pexels-photos-janpf的发布为计算机视觉领域的研究者提供了丰富的实验素材,尤其在图像生成和分类模型的训练中发挥了重要作用。
当前挑战
pexels-photos-janpf数据集在构建和应用中面临多重挑战。首先,图像格式和分辨率的不一致性增加了数据预处理的复杂性,研究者需借助工具如img2dataset进行标准化处理。其次,尽管提供了多种预生成图像描述(如WD14、InternLM和LLava-38b),但这些描述在准确性和完整性上存在差异,尤其是WD14描述中存在明显的标签错误。此外,数据集的规模虽大,但部分图像因过于艺术化或经过过度处理,可能不适合直接用于模型训练,需通过子集筛选进一步优化。这些挑战为研究者在数据预处理、模型训练和评估中提出了更高的技术要求。
常用场景
经典使用场景
pexels-photos-janpf数据集广泛应用于图像生成和分类任务中,尤其是在需要大量高质量图像进行模型训练的场景。该数据集包含了约130K张来自pexels.com的图像,涵盖了多种主题和风格,为研究人员提供了丰富的视觉素材。通过使用这些图像,研究者可以训练出更加精准的图像生成模型,提升图像分类的准确性。
解决学术问题
该数据集解决了图像生成和分类领域中数据稀缺和质量不一的问题。通过提供大量高质量的图像,研究人员可以更好地训练深度学习模型,提升模型的泛化能力和准确性。此外,数据集还提供了多种预生成的图像描述,帮助研究者在自然语言处理与计算机视觉的交叉领域进行探索,推动了多模态学习的发展。
实际应用
在实际应用中,pexels-photos-janpf数据集被广泛用于广告设计、社交媒体内容生成以及虚拟现实场景构建等领域。广告公司可以利用这些图像生成更具吸引力的广告素材,社交媒体平台则可以通过图像分类技术自动筛选和推荐相关内容。此外,虚拟现实开发者可以使用这些图像构建逼真的虚拟环境,提升用户体验。
数据集最近研究
最新研究方向
在计算机视觉领域,pexels-photos-janpf数据集因其丰富的图像资源和多样化的标注信息,成为文本到图像生成和图像分类任务的重要研究工具。近年来,随着多模态模型的快速发展,该数据集被广泛应用于视觉语言模型(VLM)的预训练和微调任务中。特别是LLava-38b等大规模视觉语言模型的使用,显著提升了图像描述的准确性和语义丰富度,推动了图像生成与理解的前沿研究。此外,数据集中的子集筛选功能为特定任务(如人物识别、场景分类)提供了高效的数据支持,进一步促进了领域内精细化模型训练的研究进展。
以上内容由遇见数据集搜集并总结生成


