Datadog/ARFBench
收藏Hugging Face2026-05-02 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/Datadog/ARFBench
下载链接
链接失效反馈官方服务:
资源简介:
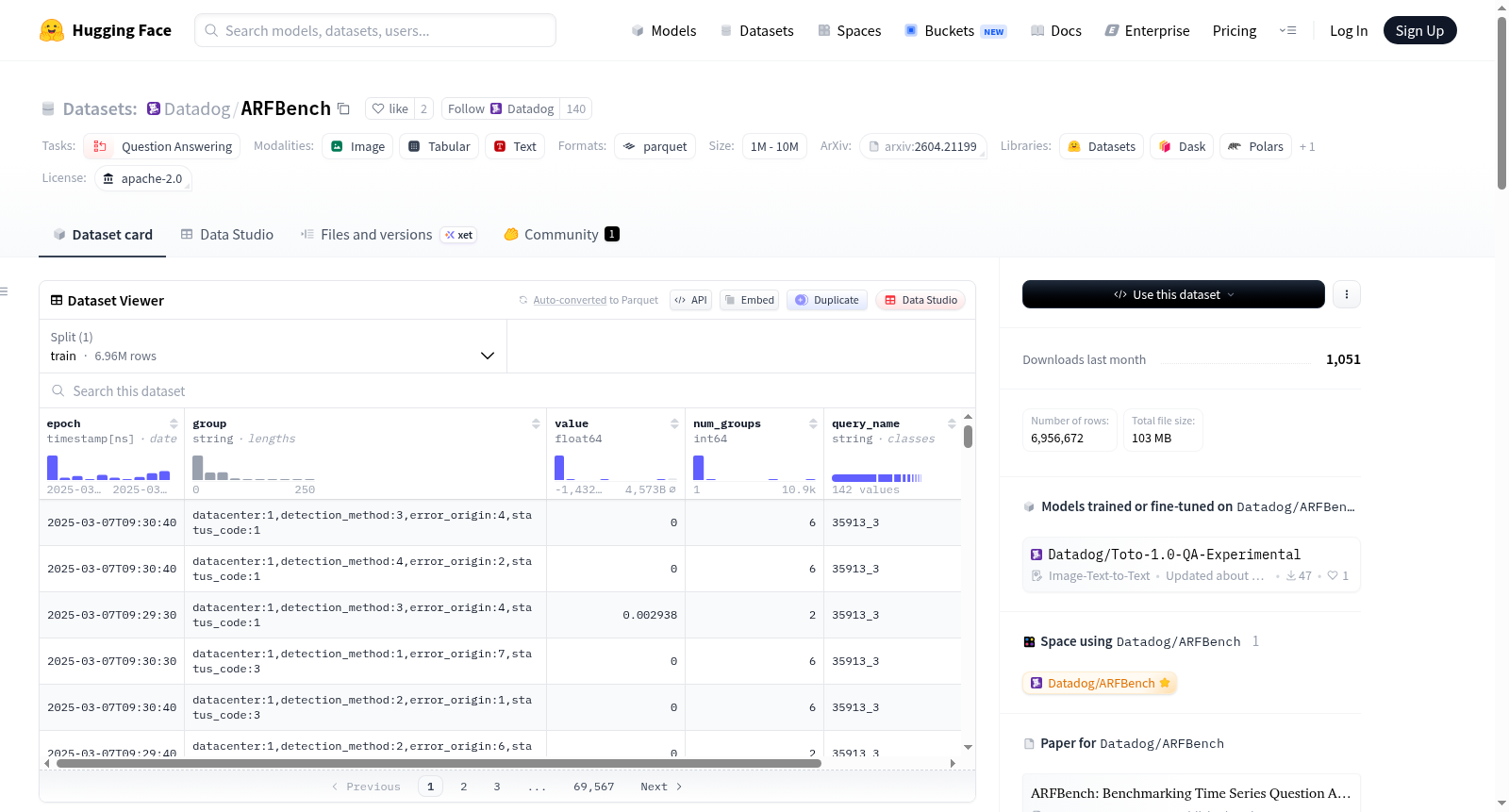
ARFBench(异常推理框架基准)是一个多模态时间序列推理基准,包含750个基于Datadog(一个领先的可观测性平台)收集的真实世界事件数据组成的问答对。这些数据覆盖了多个领域,包括应用程序使用、基础设施、网络、数据库和安全。每个问答对包括问题、任务类别、难度、选项、正确答案、查询组和插值标志。此外,每个唯一的时间序列都有两种不同的数据模态:时间序列数据和时序图。该基准旨在评估模型在软件事件响应中对多时间序列的推理能力。
ARFBench (Anomaly Reasoning Framework Benchmark) is a multimodal time-series reasoning benchmark consisting of 750 question-answer (QA) pairs composed from real-world incident data collected at Datadog, a leading observability platform. The data spans various domains including application usage, infrastructure, networking, database, and security. Each QA pair includes a question, task category, difficulty, options, correct answer, query group, and interpolation flags. Additionally, each unique time series has two associated modalities: time series data and time series plots. The benchmark is designed to evaluate the reasoning ability of models over multiple time series in software incident response.
提供机构:
Datadog
搜集汇总
数据集介绍
构建方式
ARFBench是基于Datadog真实世界事件数据构建的多模态时间序列推理基准,包含750个问答对。其构建流程如下:首先,从63个内部监控事件讨论线程中提取142条独特的时间序列,这些序列涵盖应用使用、基础设施、网络、数据库与安全等多个领域。随后,借助大型语言模型管道,将时间序列与事件时间线输入,适配至八种不同的问模板,这些模板针对异常现象的多种维度进行测试。最终生成的多元选择题问答对可有效评估各类预测模型的表现。每个问答对均收录于CSV文件中,并附带时间序列数据及其可视化图像。
特点
ARFBench的核心特点在于其真实世界、多变量且富含上下文的时间序列数据,并由领域专家进行标注。与现有基准相比,ARFBench特别强调对多时间序列进行推理的能力,这对于软件事件响应至关重要。数据集按照任务类别与推理难度分层,包含八个不同复杂度级别的问类型,能够全面评估模型在异常推理各环节的表现。此外,每个时间序列均提供原始数值数据与图像两种模态,支持灵活的实验设计。
使用方法
ARFBench的使用方法简便高效。所有750个问答对均以CSV格式提供,每一行包含问描述、任务类别、难度等级、选项列表、正确答案及其对应的时间序列查询组标识。研究者可通过查询组标识找到关联的时间序列数据或图像。时间序列数据提供最多六个不同区间的同一数据片段,而图像则是由Matplotlib或Plotnine直接生成的PNG格式图。用户可将CSV文件加载至数据处理框架中,利用问与图像/数值数据进行模型评估,并通过官方排行榜提交结果以参与对比。
背景与挑战
背景概述
ARFBench(Anomaly Reasoning Framework Benchmark)是由Datadog团队于2026年发布的多模态时间序列推理基准,核心研究者包括Stephan Xie、Ben Cohen、Mononoto Goswami等。该数据集从Datadog内部监控平台收集的63个真实事件讨论线程中,提取142条多变量时间序列,构建了750个问答对,覆盖应用使用、基础设施、网络、数据库及安全五大领域。ARFBench旨在评估大语言模型在软件事件响应中对异常时间序列的理解与推理能力,填补了现有基准在真实、多变量、专家标注及跨时间序列推理方面的空白,对提升运维智能体的诊断效能具有重要推动价值。
当前挑战
ARFBench所解决的领域挑战在于,现有时间序列问答基准多依赖合成数据或单变量场景,难以模拟软件事件响应中多变量、上下文丰富的真实异常,且缺乏对跨序列因果推理的评估;该数据集的构建亦面临复杂挑战,包括从64个内部事件中提取时序数据并确保不包含客户信息,设计八种难度递增的问答模板以覆盖从基本异常识别到跨序列根因分析的推理层次,以及人工专家对时间序列进行精确标注以保障答案可信度。
常用场景
经典使用场景
ARFBench作为首个聚焦软件事件响应领域的多模态时间序列推理基准,其经典使用场景涵盖了对大型语言模型(LLM)在异常检测与根因分析任务中的评估。该数据集由750道多选题构成,每道题均配备真实运维事件中采集的多变量时间序列数据及其可视化图像,并辅以专家标注的上下文信息。研究者可利用该基准系统性地测试模型在识别异常模式、理解时间序列间因果关系以及跨指标推理等维度上的能力。例如,模型需根据CPU使用率、延迟和错误率等多条曲线,判断故障的根本原因或预测事件的发展趋势,从而全面衡量其在复杂运维环境中的智能决策水平。
衍生相关工作
基于ARFBench,研究社区已衍生出一系列富有影响力的工作。其中最具代表性的是Datadog团队同步发布的Toto-VLM模型,它专门针对多模态时间序列推理任务进行优化,在ARFBench全量问题集上取得了最高的总体F1分数,验证了视觉语言模型在运维智能领域的巨大潜力。此外,该基准催生了对时间序列数据增强策略、跨模态对齐技术与专家知识蒸馏方法的研究热潮。围绕ARFBench还建立了公开排行榜与评测平台,吸引全球研究者贡献新型推理框架,推动了诸如时序逻辑解耦网络、对比学习预训练模型等一系列前沿方法的涌现,加速了AIOps领域从规则驱动向数据驱动、从单一预测向综合推理的演变。
数据集最近研究
最新研究方向
ARFBench作为首个聚焦于可观测性领域软件事件响应的时间序列问答基准,开创性地将多模态时间序列推理与异常检测相结合。该数据集基于Datadog平台真实运维事件构建了750个多选问答对,涵盖应用使用、基础设施、网络、数据库及安全等多元监控域,通过八类模板化的异常推理问题(如变点检测、趋势分析、多序列因果推断)系统评估模型能力。当前前沿研究正围绕两大方向展开:一是利用ARFBench推动大型语言模型与视觉语言模型在时间序列理解上的能力边界突破,如“Toto-VLM”在F1指标上展现出的领先表现;二是将其作为推动运维自动化智能体的关键基准——通过模拟工程师在异常事件中解读时序图、关联上下文并做出决策的认知流程,为构建可解释、可干预的智能运维系统提供标准化评测范式。该数据集的发布不仅弥补了现有合成数据或单变量基准缺乏现实复杂性的短板,更将因果推理、多变量协同分析等前沿课题引入运维AI领域,对提升云服务可靠性管理具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


