proc1v/screen2ax-tree-silver-qwen3vl-235b
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/proc1v/screen2ax-tree-silver-qwen3vl-235b
下载链接
链接失效反馈官方服务:
资源简介:
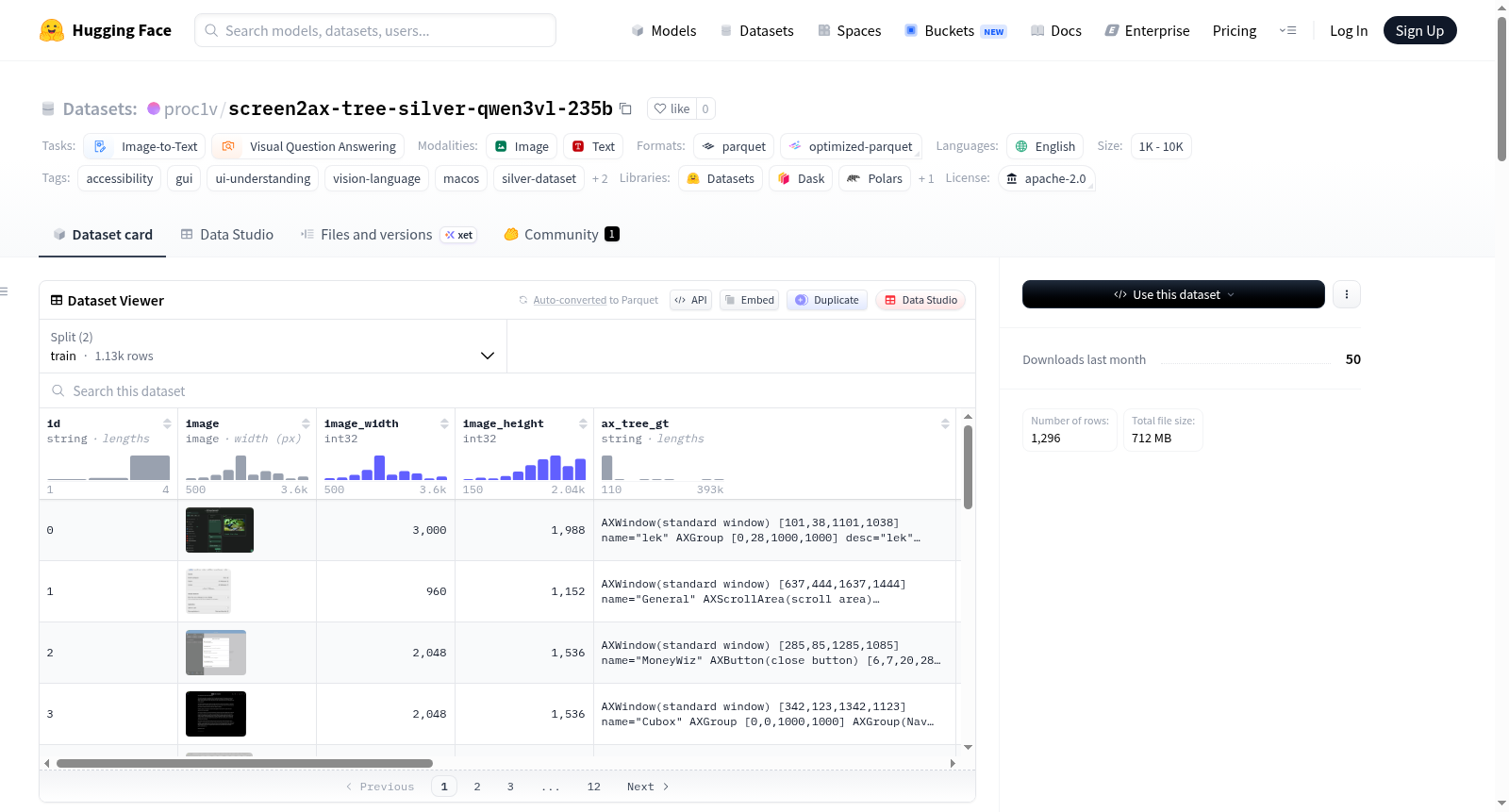
Screen2AX-Tree Silver (Qwen3-VL-235B) 是一个银级(伪标记)可访问性树数据集,用于macOS屏幕截图。该数据集由Qwen/Qwen3-VL-235B-A22B-Instruct模型在零样本设置下生成,旨在用于小型视觉语言模型的知识蒸馏,以及研究大型前沿视觉语言模型在macOS GUI理解上的失败模式。数据集包含1127个样本,每个样本包含原始截图、人工标注的真实AX树和模型预测的AX树。数据集结构包括多个字段,如id、image、ax_tree_gt、ax_tree_pred等。数据集的使用场景包括蒸馏/伪标签SFT、错误分析和基准测试预热数据。数据集的限制包括坐标缩放、生成器质量参差不齐、截断和替代代码点等问题。
Screen2AX-Tree Silver (Qwen3-VL-235B) is a silver (pseudo-labelled) accessibility tree dataset for macOS screenshots. The dataset is generated by the Qwen/Qwen3-VL-235B-A22B-Instruct model in a zero-shot setting and is intended for knowledge distillation of smaller vision-language models and for studying the failure modes of large frontier VLMs on macOS GUI understanding. The dataset contains 1127 samples, each including the original screenshot, the human-curated ground-truth AX tree, and the AX tree predicted by the model. The dataset structure includes various fields such as id, image, ax_tree_gt, ax_tree_pred, etc. Intended uses include distillation/pseudo-label SFT, error analysis, and benchmark warm-up data. Limitations include coordinate scaling, mixed generator quality, truncation, and surrogate codepoints.
提供机构:
proc1v
搜集汇总
数据集介绍
构建方式
Screen2AX-Tree Silver (Qwen3-VL-235B) 数据集源自 macOS 屏幕截图的可访问性树(Accessibility Tree)任务,其构建过程采用知识蒸馏范式。该数据集以 macpaw-research/Screen2AX-Tree 为基础,保留了原始截图与人工标注的真实树结构,同时利用大规模视觉语言模型 Qwen/Qwen3-VL-235B-A22B-Instruct 在零样本设定下为每张截图生成伪标签树。生成过程中采用确定性解码(temperature=0.0),最大生成长度设为 8192 tokens,仅对输出进行 Markdown 代码块剥离等轻量后处理,未通过样本或思维链引导,从而确保了伪标签的独立性与可复现性。
特点
该数据集的核心特色在于其作为银标准(Silver Standard)数据集的定位。每个样本同时包含人工校验的真实树(ax_tree_gt)与模型预测树(ax_tree_pred),为研究者提供了清晰的噪声监督信号与干净参考基准。数据集包含 1127 个样本,涵盖丰富的字段信息,如模型标识、采样参数、生成延迟、解析成功标志等,便于进行细粒度的误差分析。预测树采用统一的线性化格式,以缩进层级表示 UI 元素层次,并包含角色、子角色、边界框及可选属性,结构严谨且易于解析。
使用方法
该数据集主要通过 HuggingFace Datasets 库加载,调用 load_dataset 函数即可获取训练集。使用时,研究者可根据需求筛选字段:ax_tree_pred 适用于小规模视觉语言模型(如 Qwen2-VL-7B)的蒸馏或伪标签监督微调,而 ax_tree_gt 则作为评估的干净标签。建议在蒸馏前对预测树按节点数量或解析成功标志进行过滤,以剔除截断或解析失败的样本。坐标转换需注意屏幕截图的 Retina 缩放,将 0–1000 的归一化边界框乘以实际图像尺寸即可得到像素坐标。
背景与挑战
背景概述
Screen2AX-Tree Silver (Qwen3-VL-235B) 数据集创建于2025年,由MacPaw研究团队基于其先前发布的 Screen2AX-Tree 数据集构建,旨在探索利用大规模视觉语言模型(VLM)为macOS图形用户界面(GUI)生成可访问性(Accessibility)树的可行性。核心研究问题聚焦于:前沿VLM(如Qwen3-VL-235B)是否能够零样本地从截图中准确推断出层级化的UI结构信息,从而为小模型的知识蒸馏提供高质量的伪标签。该数据集包含1127个样本,每个样本均保留了原始截图、人工标注的真实可访问性树以及模型预测结果,为GUI理解与可访问性自动化领域提供了宝贵的比较基准。其影响力体现在推动了大模型在界面感知任务中的知识迁移研究,并为可访问性工具的开发提供了数据基础。
当前挑战
该数据集所解决的领域问题挑战在于,GUI可访问性树的生成长期依赖人工标注或规则解析,成本高昂且难以扩展,尤其在macOS这类复杂桌面环境中,界面元素的层级关系、角色分类及空间坐标的精确建模极具挑战性。构建过程中,大规模VLM虽具备强大能力,但面临多方面的困难:模型对深层UI树的召回率不足,常出现子树遗漏、角色幻觉或层级扁平化;预测结果受限于最大生成长度(8192 tokens),部分样本被截断导致树结构不完整;坐标标准化需处理Retina屏幕的2×缩放,转换时易引入误差;此外,零样本提示策略未提供示例或思维链,模型需完全依赖对输出语法的理解,导致部分预测无法解析。这些挑战凸显了大型VLM在结构化界面理解任务中的性能边界,也明确了伪标签作为监督信号时的噪声特性。
常用场景
经典使用场景
在图形用户界面理解与无障碍领域,screen2ax-tree-silver-qwen3vl-235b数据集被设计为一种知识蒸馏的关键资源。其核心用途在于,利用大型视觉语言模型Qwen3-VL-235B对macOS截屏生成的伪标签无障碍树,为参数量较小的视觉语言模型提供监督信号。研究人员通常采用该数据集对学生模型进行微调,使之习得从截屏直接生成结构化UI元素层次关系的能力,从而在保证效率的同时逼近大模型的生成性能。
实际应用
在实际应用中,screen2ax-tree-silver-qwen3vl-235b数据集主要服务于两个方向。其一,辅助训练轻量级UI理解模型,例如将其部署于移动设备或浏览器扩展中,实现实时截屏的UI结构提取,为视障用户提供即时语音描述。其二,用于自动化测试与QA分析,通过对生成树节点的坐标和角色进行校验,可快速定位界面渲染异常或功能缺失,极大提升macOS应用的兼容性测试效率与质量保障流程。
衍生相关工作
基于此数据集,学术界已衍生出一系列关键工作。一方面,研究者将其与原始Screen2AX-Tree结合,构建教师-学生蒸馏框架,提出如Qwen2-VL-7B和ShowUI等轻量模型的指令调优策略。另一方面,该数据集也被用于错误分析,对Qwen3-VL-235B在深层树结构、角色幻觉等场景下的失败案例进行系统性剖析,推动了层级式GUI理解评估基准的完善,并为多模态大模型在无障碍场景下的边界探索提供了实证基础。
以上内容由遇见数据集搜集并总结生成


