HIMO
收藏arXiv2024-07-17 更新2024-07-19 收录
下载链接:
https://lvxintao.github.io/himo
下载链接
链接失效反馈官方服务:
资源简介:
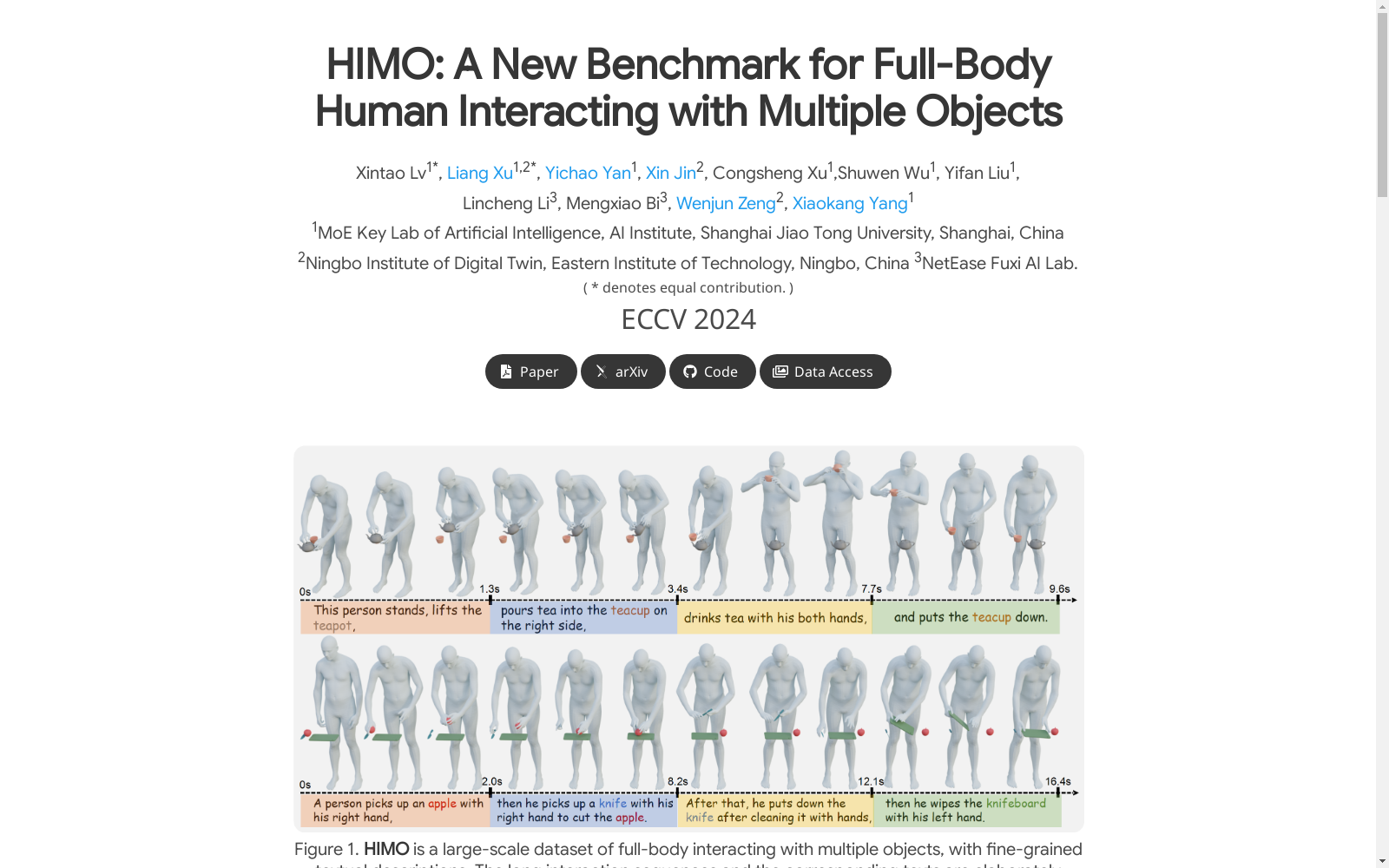
HIMO数据集由上海交通大学人工智能研究所等机构创建,是一个大规模的全身体感数据集,专注于人与多个对象的交互。数据集包含3.3K 4D HOI序列和4.08M 3D HOI帧,通过光学MoCap系统和可穿戴惯性手套捕捉精确的身体和手指运动。数据集的创建过程包括对日常对象的精确跟踪和细致的文本描述标注,旨在支持文本驱动的HOI合成研究,特别是在视频游戏、AR/VR和机器人技术等领域。
The HIMO dataset, developed by the Institute of Artificial Intelligence at Shanghai Jiao Tong University and other institutions, is a large-scale full-body motion capture dataset focused on human interactions with multiple objects. It contains 3.3K 4D HOI sequences and 4.08M 3D HOI frames, capturing precise body and finger movements through optical MoCap systems and wearable inertial gloves. The dataset construction process involves accurate tracking of daily objects and annotations with detailed textual descriptions. It is designed to support text-driven HOI synthesis research, especially in fields such as video games, AR/VR, and robotics.
提供机构:
上海交通大学人工智能研究所,宁波东方理工数字孪生研究所,网易伏羲人工智能实验室
创建时间:
2024-07-17
原始信息汇总
HIMO 数据集概述
数据集简介
HIMO 是一个大规模的 MoCap 数据集,专注于全身体与多个对象的交互。该数据集包含 3.3K 个 4D 人体-对象交互(HOI)序列和 4.08M 个 3D HOI 帧。此外,HIMO 还配备了详细的文本描述和时间片段注释,支持基于整个文本提示或分段文本提示的 HOI 合成任务,实现细粒度的时间线控制。
数据集特点
- 规模:包含 3.3K 个 4D HOI 序列和 4.08M 个 3D HOI 帧。
- 注释:提供详细的文本描述和时间片段注释。
- 应用:适用于基于整个文本提示或分段文本提示的 HOI 合成任务。
数据集应用
HIMO 数据集主要用于以下两个新颖的 HOI 合成任务:
- 基于整个文本提示的 HOI 合成:利用完整的文本描述生成 HOI 序列。
- 基于分段文本提示的 HOI 合成:利用分段的文本描述生成 HOI 序列,实现细粒度的时间线控制。
数据集访问
数据集可通过以下链接申请访问: 数据访问链接
搜集汇总
数据集介绍
构建方式
HIMO 数据集通过采用光学动作捕捉系统来获取人体的精确运动,并使用可穿戴惯性手套来捕捉手指的微妙动作。数据集包含了34名受试者执行与53种日常物体的组合互动,共产生了3,376个4D人体对象互动序列和4.08M个3D人体对象互动帧。此外,为了精确跟踪物体运动,研究者在物体表面附着了多个反射标记,并通过后校准过程补偿了物体和标记之间的偏差。
特点
HIMO 数据集的特点在于它包含了大规模的4D人体对象互动序列,以及详细的文本描述和时序分割标签。数据集的多样性体现在不同的受试者、物体组合和互动模式上。此外,数据集的文本描述和时序分割标签使得文本驱动的人体对象互动合成成为可能,并支持两种新型任务:基于整个文本提示的HIMO-Gen和基于分割文本提示的HIMO-SegGen。
使用方法
HIMO 数据集可用于研究文本驱动的人体对象互动合成。研究者可以使用数据集中的文本描述和时序分割标签来训练模型,以便生成与文本描述相匹配的人体和物体运动。此外,数据集也可以用于评估模型在生成未见过的物体几何形状和新颖的人体对象互动组合方面的泛化能力。
背景与挑战
背景概述
HIMO数据集是由上海交通大学人工智能研究院、宁波数字孪生研究院和网易伏羲人工智能实验室的研究人员共同创建的。该数据集旨在解决当前数据集中人类与单个物体交互的限制,并扩展到人类与多个物体交互的场景。HIMO数据集包含3.3K个4D人体与物体交互序列和4.08M个3D人体与物体交互帧,并具有详细的文本描述和时序分割标签。HIMO数据集的创建对于推动数字角色、增强现实/虚拟现实、机器人学和具身人工智能等领域的发展具有重要意义。
当前挑战
HIMO数据集面临的挑战包括:1) 在4D人体与物体交互捕获过程中,手指的细微动作、物体的严重遮挡和多种物体的精确跟踪等方面的挑战;2) 在构建过程中,对多个物体交互场景的复杂性进行建模和时序控制,包括物体间和人体与物体间的空间运动以及多个原子人体与物体交互间隔的时序调度。
常用场景
经典使用场景
HIMO数据集是一个大规模的运动捕捉数据集,它包含人体与多个物体交互的详细文本描述和时序分割。该数据集的经典使用场景包括训练和评估文本驱动的交互生成模型,特别是在视频游戏、增强现实/虚拟现实、机器人技术和具身AI等领域。通过对人体与多个物体的精细交互过程进行建模,HIMO数据集可以促进对复杂交互模式的理解,并推动更真实、更协调的人机交互生成技术的发展。
解决学术问题
HIMO数据集解决了现有数据集在人体与多个物体交互方面的不足,为研究文本驱动的交互生成提供了新的基准。该数据集不仅提供了丰富的交互场景和时序分割,还通过详细的文本描述,使得研究人员能够更精确地控制交互的时序和模式。此外,HIMO数据集的提出也推动了互注意力模块在交互生成中的应用,从而提高了生成的交互序列的协调性和真实性。
衍生相关工作
HIMO数据集的提出推动了多个相关领域的经典工作,包括但不限于文本驱动的交互生成、人体运动合成和时序动作合成。在文本驱动的交互生成方面,HIMO数据集为研究人员提供了新的基准和挑战,促进了更真实、更协调的人机交互生成技术的发展。在人体运动合成方面,HIMO数据集的提出推动了互注意力模块在交互生成中的应用,从而提高了生成的交互序列的协调性和真实性。在时序动作合成方面,HIMO数据集的时序分割和文本描述为研究人员提供了更精确的控制方式,推动了更复杂、更灵活的动作合成技术的发展。
以上内容由遇见数据集搜集并总结生成


