kaist-ai/Multifaceted-Collection
收藏资源简介:
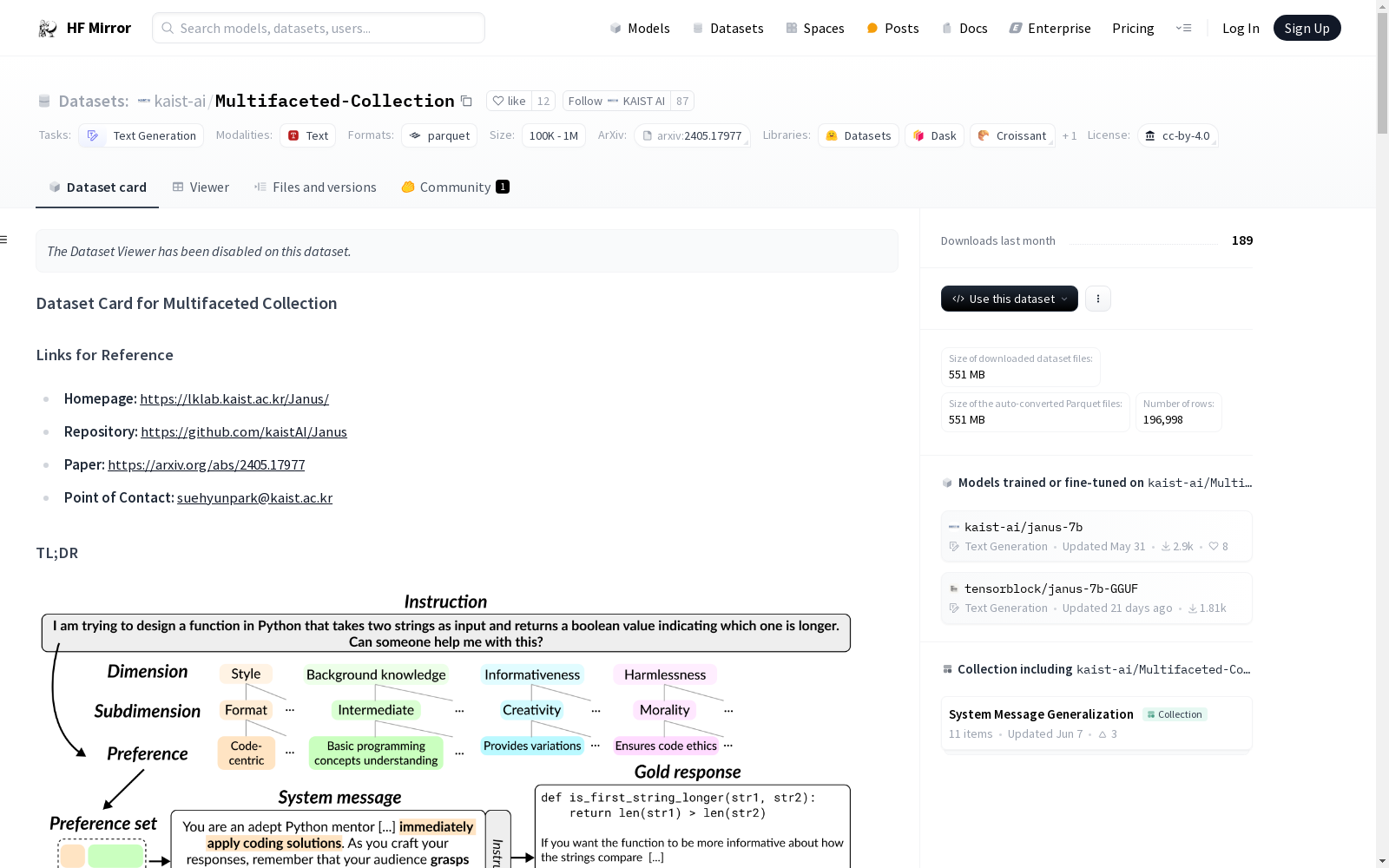
Multifaceted Collection是一个偏好数据集,用于对齐大型语言模型(LLMs)以适应多样的人类偏好。数据集包含65k个独特的指令,每个指令伴随3个表示不同偏好的系统消息和相应的响应,总计196k个实例。数据集的创建旨在解决现有对齐数据集的局限性,捕捉跨多个维度的细粒度偏好。数据集的主要字段包括`main_source`(指令的来源数据集)、`original_source`(指令的原始来源)、`preference_set`(偏好集,包含维度、子维度和具体偏好)、`system`(系统消息,详细说明要遵循的个体偏好)、`prompt`(指示特定任务的指令)和`output`(最佳响应,由GPT-4生成)。
Multifaceted Collection is a preference dataset designed for aligning large language models (LLMs) with diverse human preferences. The dataset comprises 65,000 unique instructions, each paired with 3 system messages reflecting distinct preferences and their corresponding responses, totaling 196,000 instances. This dataset was constructed to address the limitations of existing alignment datasets, capturing fine-grained preferences across multiple dimensions. The key fields of the dataset include `main_source` (the source dataset of the instruction), `original_source` (the original source of the instruction), `preference_set` (a preference set containing dimensions, sub-dimensions and specific preferences), `system` (system messages detailing individual preferences to follow), `prompt` (the instruction specifying a particular task), and `output` (the optimal response generated by GPT-4).
数据集卡片 for Multifaceted Collection
数据集详情
数据集概述
Multifaceted Collection 是一个用于对齐大型语言模型(LLMs)与多样化人类偏好的偏好数据集,其中系统消息用于表示个人偏好。该数据集包含65k条独特的指令,每条指令伴随3条表示不同偏好的系统消息及相应响应,总计196k个实例。
- 许可证: Creative Commons Attribution 4.0
- 相关数据集: Multifaceted-Collection-small, Multifaceted-Collection-DPO, Multifaceted-Collection-ORPO, Multifaceted-Collection-RM, Multifaceted-Bench
- 训练模型: Janus 7B
数据集结构
数据实例
以下是数据集中的一个示例实例:
json { "main_source": "OpenHermesPreferences", "original_source": "CamelAI", "preference_set": [ { "dimension": "style", "subdimension": "vividness", "preference": "richly descriptive", "description": "The preference leans towards using a richly descriptive style that vividly illustrates the scenario of the game, including sensory details and metaphors to make the theoretical concepts more tangible and engaging." }, { "dimension": "background_knowledge", "subdimension": "expert", "preference": "advanced mathematical concepts", "description": "This preference suggests tailoring responses to include advanced mathematical concepts and terminologies, assuming the user has a strong background in mathematics or game theory." }, { "dimension": "informativeness", "subdimension": "practicality", "preference": "application-focused", "description": "The preference is for responses that not only explain the expected value in the context of the given game but also extend the discussion to practical applications of these principles in real-life situations or other games." }, { "dimension": "harmlessness", "subdimension": "morality", "preference": "ethical considerations", "description": "A preference for integrating ethical considerations into the response, reflecting on the fairness and morality of using misleading tactics like the double-headed or double-tailed pennies in games or any competitive scenario." } ], "system": "Envision yourself as a masterful game theorist and strategist, weaving advanced mathematical concepts into the rich tapestry of game scenarios.", "prompt": "Two players, A and B, are playing a game of matching pennies.", "output": "Lets dissect the scenario with the artistry of game theory, crafting a vivid tableau from what seems a simple pas de deux of coin flips." }
数据字段
main_source(str): 指令的源数据集original_source(str): 根据源数据集的指令原始来源preference_set(List[Dict[str, str]]): 偏好集,构成系统消息的基础。每个偏好集包含四个高级维度(风格、背景知识、信息量和无害性)的偏好,按维度、子维度和特定偏好的顺序指定。system(str): 系统消息,详细说明遵循个人多方面偏好的目标。prompt(str): 指示特定任务的指令output(str): 最佳遵循系统消息和指令的黄金响应,由gpt-4-0125-preview生成
数据集创建
数据集创建理由
Multifaceted Collection 数据集旨在解决现有对齐数据集的局限性,通过捕捉跨多个维度的细粒度偏好。我们将偏好概念化为一个详细的文本描述,说明一个理想的响应应具备的质量。
数据收集和处理
1. 指令采样
从五个高质量偏好数据集中选择指令:
- Nectar
- OpenHermesPreferences
- UltraFeedback-binarized-clean
- Chatbot Arena Conversations
- Domain-Specific Preference dataset (DSP)
2. 偏好集生成
我们最初确定了四个主要维度:风格、背景知识、信息量和无害性。然后定义了一个包含每个维度一个偏好的偏好集。
3. 系统消息和黄金响应生成
使用 GPT-4 Turbo 将每个偏好集转换为系统消息,并为每个系统消息生成黄金标准的多样化响应。