ms-marco-tr-hard-negatives
收藏MS MARCO TR - Zor Negatifler (Hard Negatives) Veri Seti
数据集概述
- 来源仓库:从 parsak/msmarco-tr 派生而来
- 语言:土耳其语 (
tr) - 任务:语义搜索、密集检索、嵌入训练
- 规模:约500k - 1M 训练三元组(取决于处理的查询数量)
- 作者:Lumees AI, Hasan Kurşun, Kerem Berkay Yanık
- 年份:2025
- 网站:lumees.io
数据集摘要
该数据集包含专门为土耳其语MS MARCO数据集挖掘的困难负样本。专为训练或微调土耳其语信息检索任务中的句子嵌入模型而设计。
与标准随机负样本不同,这些"困难"负样本是与查询具有高度语义相似性但不是正确答案的段落。在此数据上训练可以迫使模型学习细微的语义区别,从而显著提高检索性能。
创建过程
- 源数据:训练查询和段落来自
parsak/msmarco-tr(机器翻译的土耳其语MS MARCO)数据集 - 挖掘模型:使用 emrecan/bert-base-turkish-cased-mean-nli-stsb-tr 模型
- 方法:
- 编码:使用挖掘模型将所有查询和段落转换为密集向量
- 检索:对于每个查询,使用Faiss(内积)检索最相似的100个段落
- 过滤:从结果中移除真正的正样本(正确答案)
- 安全阈值:为防止"假负样本",相似度得分高于0.98的段落被丢弃
- 选择:从剩余候选中选择得分最高的前10个段落作为困难负样本
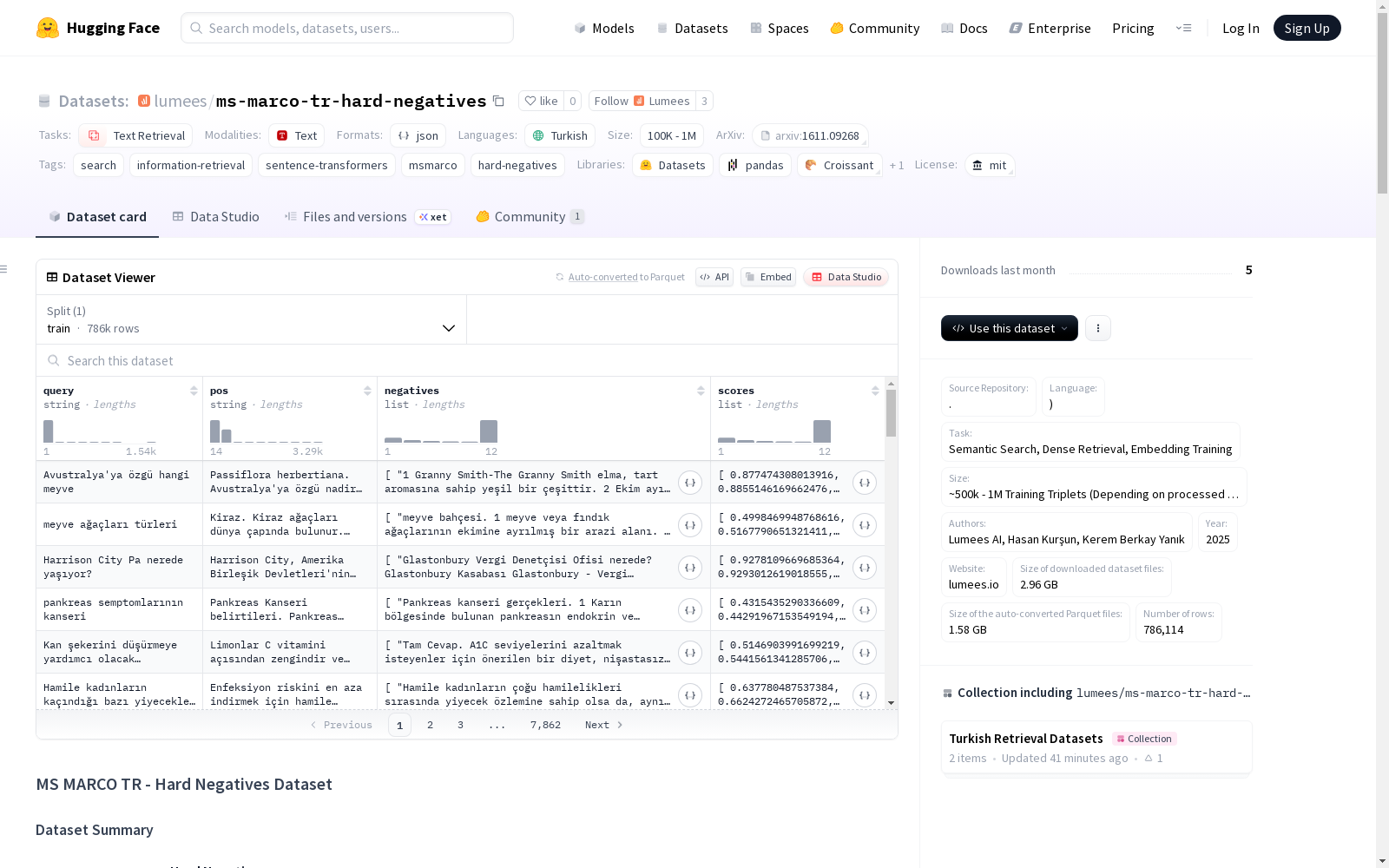
数据结构
数据示例
.jsonl文件中的每一行代表一个训练样本的有效JSON对象:
json { "query": "Manhattan projesinin başarısının hemen etkisi neydi?", "pos": "Manhattan Projesi ve atom bombası, İkinci Dünya Savaşının sona ermesine yardımcı oldu...", "negatives": [ "Manhattan Projesi, II. Dünya Savaşı sırasında ilk atom bombasını geliştirmek için...", "Proje, nükleer silah üretimi üzerine odaklanmıştı...", "..." ], "scores": [ 0.874, 0.852, "..." ] }
数据字段
query(string):搜索查询pos(string):真正的正样本段落(正确答案)negatives(字符串列表):与查询语义相近但错误的10个段落列表,按相似度排序(从高到低)scores(浮点数列表):对应negatives列表中段落的余弦相似度得分,可用于训练期间的边际过滤或加权损失函数
使用指南
数据集加载(Python)
可以使用Hugging Face datasets库或标准JSON行读取方法加载此数据集:
python from datasets import load_dataset
如果已上传到Hugging Face
ds = load_dataset("lumees/msmarco-tr-hard-negatives", split="train")
如果从本地文件加载
ds = load_dataset("json", data_files="msmarco_tr_hard_negatives_final.jsonl", split="train")
print(ds[0])
使用Sentence Transformers训练
该数据集针对MultipleNegativesRankingLoss或InfoNCE等损失函数进行了优化:
python from sentence_transformers import InputExample
train_examples = [] for row in ds: # 结构:[查询, 正样本, 负样本1, 负样本2, ...] texts = [row[query], row[pos]] + row[negatives] train_examples.append(InputExample(texts=texts))
限制与偏差
- 翻译错误:原始
parsak/msmarco-tr数据集是通过机器翻译从英语创建的,因此某些土耳其语表达可能不自然或包含翻译错误 - 假负样本:尽管有
0.98的相似度过滤器,但某些被选为"负样本"的段落实际上可能是原始数据集中未标记的正确答案 - 模型偏差:负样本是使用
emrecan/bert-base-turkish模型提取的,数据集自然反映了这个基础模型的偏差和语义理解
引用
如果使用此数据集,请引用Lumees AI、原始MS MARCO作者和土耳其语翻译来源:
bibtex @misc{lumees_msmarco_hn_2025, author = {Lumees AI and Kurşun, Hasan and Yanık, Kerem Berkay}, title = {MS MARCO TR - Hard Negatives Dataset}, year = {2025}, howpublished = {url{https://lumees.io}}, }
@article{bajaj2016ms, title={MS MARCO: A Human Generated Machine Reading Comprehension Dataset}, author={Bajaj, Payal and Campos, Daniel and Craswell, Nick and Deng, Li and Gao, Jianfeng and Liu, Xiaodong and Majumder, Rangan and McNamara, Andrew and Mitra, Bhaskar and Nguyen, Tri and others}, journal={arXiv preprint arXiv:1611.09268}, year={2016} }
@misc{parsak_msmarco_tr, author = {Parsak}, title = {MS MARCO Turkish Translation}, year = {2023}, publisher = {Hugging Face}, journal = {Hugging Face Hub}, howpublished = {url{https://huggingface.co/datasets/parsak/msmarco-tr}} }